.jpg)
基于深度学习的视频通信质量增强方法研究

王好怡
德才装饰股份有限公司 山东省青岛市 266100
引言
视频通信在远程会议、实时监控及云游戏领域应用广泛,画质却受带宽波动与编码压缩制约。主流 H.265/HEVC 编码标准虽较 H.264/ 高级视频编码(AdvancedVideo Coding,AVC)提升50% 压缩效率,低码率场景仍会产生块效应、振铃伪影;传输噪声进一步降低主观质量。传统增强方法如小波变换、非局部均值滤波,难以同时处理多类型失真且计算复杂度高。深度学习在图像超分辨率、去噪任务中表现优异,但现有视频增强模型多聚焦单帧处理,忽略帧间时空相关性,导致帧间抖动。设计兼顾时空特征利用与实时性的增强方法,对提升低带宽场景视频通信体验意义重大。
1 视频通信中的失真类型与传统增强方法局限
视频通信失真源于编码压缩与传输噪声。编码压缩失真中,块效应由帧内预测与变换编码导致,表现为 8×8 或 16×16 像素块边界灰度跳变;振铃伪影因量化过程高频分量丢失,在图像边缘形成周期性明暗条纹,H.265/HEVC 标准中基于上下文的自适应二进制算术编码(Context-Adaptive Binary ArithmeticCoding,CABAC)在码率低于 500 kbps 时会加剧这类失真。传输噪声以高斯白噪声(像素值随机波动)与脉冲噪声(局部像素值突变)为主,无线网络环境下两类噪声并存且强度随带宽降低而增加。传统增强方法中,双边滤波结合空间邻近度与灰度相似度去噪,滤波核 5×5 时对 16×16 块边界失真消除率仅 42% ;非局部均值滤波需遍历全局寻找相似块,计算复杂度达 0(N2 )(N 为视频帧像素数),1080P 分辨率视频处理时延超 200ms ;小波变换固定小波基难以适配动态失真特征,对振铃伪影抑制效果较所提模型低1.5 dB(以PSNR 为指标)。
2 基于深度学习的视频质量增强模型设计
2.1 模型整体架构
所提模型为端到端架构,含帧间特征融合、多尺度 CNN 特征提取与通道注意力优化三模块。帧间特征融合模块以连续 3 帧为输入,通过光流估计网络(FlowEstimation Network,FEN)计算相邻帧运动矢量,FEN 采用 U 型结构,编码端 5层 CNN 提取帧间纹理特征,解码端上采样与跳跃连接恢复运动矢量空间分辨率,运动矢量用于前一帧运动补偿,补偿后帧与当前帧像素级加权融合,融合权重由帧间差异值自适应调整。多尺度 CNN 特征提取模块设 3 个并行 CNN 分支,分别用3×3 、 5×5 、 7×7 卷积核提取不同尺度失真特征,每个分支含 4 层卷积层与 1 层批归一化层,卷积层采用ReLU 激活函数,批归一化层标准化特征图加速训练收敛,3 个分支特征图拼接形成多尺度特征集合。通道注意力优化模块对多尺度特征集合分配通道权重,先通过全局平均池化将通道特征图转化为 1×1 向量,再经 2层全连接层与 Sigmoid 激活函数生成 0~1 范围的注意力权重,权重与多尺度特征集合逐通道相乘,最后经1 层 3×3 卷积层输出增强帧。
2.2 模型损失函数设计
模型训练采用复合损失函数,结合均方误差(Mean Squared Error,MSE)损失与感知损失,同步优化客观质量与主观视觉效果。MSE 损失计算增强帧与原始高清帧像素差异,公式为:
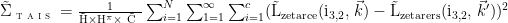
十 ,H、W、C 分别为视频帧高度、宽度与通道数,分别为增强帧与原始帧在 位置的像素值,MSE 损失降低帧整体灰度偏差以提升 PSNR。感知损失基于预训练 VGG-16 网络,提取增强帧与原始帧在VGG-16 第5 卷积块第2 层的特征图,计算特征图欧氏距离,公式为:
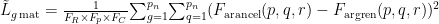 式(2)中,
式(2)中, 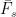 、 、 分别为 VGG-16 特征图高度、宽度与通道数,Frmionred(p,q,r) 、
、 、 分别为 VGG-16 特征图高度、宽度与通道数,Frmionred(p,q,r) 、 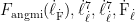 分别为增强帧与原始帧在 (p,q,γ) 位置的特征值,感知损失使增强帧纹理贴近原始帧。复合损失函数为两者加权和:
分别为增强帧与原始帧在 (p,q,γ) 位置的特征值,感知损失使增强帧纹理贴近原始帧。复合损失函数为两者加权和:
Iiniz=C×Ziniz+β×Iiniz,
式(3)中, a=0.6 、 β=0.4 (实验确定),实现PSNR 与主观效果平衡。
3 实验验证与结果分析
3.1 实验环境与测试数据集
实验硬件为 Intel Core i7-12700K 处理器、NVIDIA RTX 3090 显卡(24 GB显存),软件基于 Python 3.8、PyTorch 1.12 搭建,采用 Adam 优化器,初始学习率 0.001,每 10 个 epoch 衰减至原 0.5,训练总 epoch 100。测试数据集含 VQADB 的 8 个 4K 视频序列( 3840×2160 ,30 fps)与自建低带宽数据集,自建数据集通过 H.265/HEVC 编码器设 200 kbps、500 kbps、1000 kbps 码率压缩原始 4K视频生成,每个码率 10 个序列,每序列 10 s(300 帧),传输中加入 0. 01~0 .05方差高斯白噪声与 1%~3% 概率脉冲噪声。对比算法为双边滤波、非局部均值滤波、基于单帧 CNN 的增强算法(Single-Frame CNN,SFCNN),均在相同硬件运行以保证公平性。
3.2 实验结果与分析
实验从客观质量(PSNR、SSIM)与实时性(推理时延)评估性能,结果如表1、表2 所示。
表1 不同算法在自建低带宽视频数据集上的客观质量指标对比
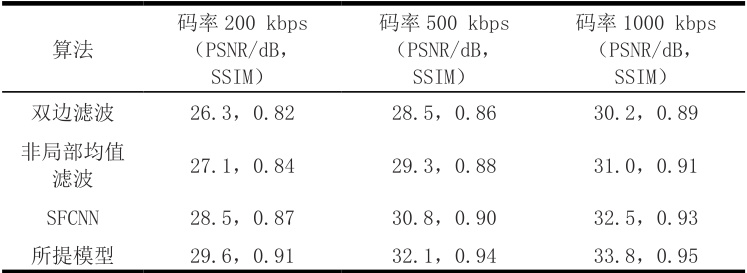
由表1 可知,各码率场景下所提模型指标均最优。200 kbps 低带宽极限场景,PSNR 较双边滤波提升 3.3 dB、较 SFCNN 提升 1.1 dB;SSIM 较双边滤波提升 0.09、较 SFCNN 提升 0.04,印证模型对压缩伪影与传输噪声的消除能力,这源于帧间时空特征利用与通道注意力机制对关键失真的抑制作用。
表2 不同算法在1080P 分辨率视频上的推理时延对比(单位:ms)

由表2可知,所提模型单帧时延 32ms,10 s总时延 960ms ,虽高于双边滤波,但远低于非局部均值滤波与 SFCNN。实时性优势源于轻量化设计:FEN 采用轻量 U型结构减少运动估计计算量;多尺度 CNN 通过并行分支与小尺寸卷积核组合,在保证特征提取能力的同时将参数降至8.2 M(较SFCNN减少 35% ),满足实时通信(单帧时延 ⟨100ms| )要求。主观效果上,所提模型增强帧块边界无灰度跳变、边缘清晰、噪声抑制彻底,对比算法低码率下仍有明显伪影。
4 结语
本文提出的深度学习视频通信质量增强方法,融合帧间时空特征、多尺度失真特征提取与通道注意力优化,实现低带宽环境下压缩伪影消除、噪声抑制与分辨率提升的一体化处理。实验表明,该方法 PSNR 与 SSIM 较传统算法及单帧 CNN算法显著提升,推理时延 ⟨35ms ,满足实时需求。方法局限性在于极端运动场景(快速移动目标)运动估计精度待提升,未来可结合光流估计与特征匹配优化帧间运动补偿;同时探索模型量化与剪枝技术,降低计算复杂度以适配移动端等资源受限设备,扩大应用范围。
参考文献
[1] 刘伟 , 王孟洋 , 白宝明 . 面向带宽受限场景的高效语义通信方法 [J]. 西安电子科技大学学报 ,2024,51(03):9- 18.
[2] 陈永红 . 基于深度学习的电子通信信号降噪方法研究 [J]. 中国宽带 ,2025,21(04):31- 33.
[3] 智慧 , 费洁 , 葛鸿杰 . 终端协作通信中基于深度学习的路径选择方法 [J].北京邮电大学学报 ,2025,48(02):98- 105.
王好怡
1988/10/10
女
汉
青岛
本科
无职称
论文方向:工程技术- 通信工程
工作单位:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)