.jpg)
机器化学家大数据建模与预测优化研究

孙嘉祎
杭州师范大学 浙江省杭州市 311100
1. 问题背景
机器化学家平台通过融合机器人实验、人工智能算法和高通量计算,革新了化学物质的开发模式。本研究基于该平台提供的 20 万分子数据集,其包含 103 个物理化学指标,重点解决四个关键问题:分子编号与性质的隐含关联建模、高维特征下的关键指标筛选、多类别分子精准分类机制设计以及预测模型的精度优化。这些问题的突破将显著提升化学研究的智能化水平。
2. 模型建立与求解
2.1 数据预处理与特征工程
数据清洗采用循环遍历法验证完整性,基于箱线图法识别并剔除异常值,确保数据质量。特征工程针对不同预测目标设计差异化策略:对于性质 y1 预测,采用遗传算法筛选关键特征,其适应度函数以最大化特征 - 目标相关系数为核心准则;对于性质 y3 预测,运用主成分分析降维技术,保留 90% 信息量的主成分;分子分类任务则通过支持向量机系数权重排序确定核心影响因子。所有数据随机划分为 80% 训练集与 20% 测试集,保证模型验证的客观性。
2.2 核心模型构建
在非线性预测建模中,通过散点分析发现性质 y2 与分子编号存在"S" 型关联,据此建立 Logistic 方程表征该非线性映射,并采用迭代优化算法最小化残差平方和求解参数。多元线性回归模型构建过程中,首先通过遗传算法筛选出8 个关键特征,再运用最小二乘法估计回归系数,最后通过灵敏度分析识别主导性特征。对于分子多分类问题,创新性地设计分层支持向量机架构,训练三个独立的一对多分类器并通过决策融合机制输出最终类别,该方法有效解决了传统多分类器的样本不平衡问题。神经网络优化模型采用三层架构,输入层、隐含层和输出层分别设置 100、17 和 1 个节点,通过双重归一化处理和动态学习率调整策略提升训练效率。
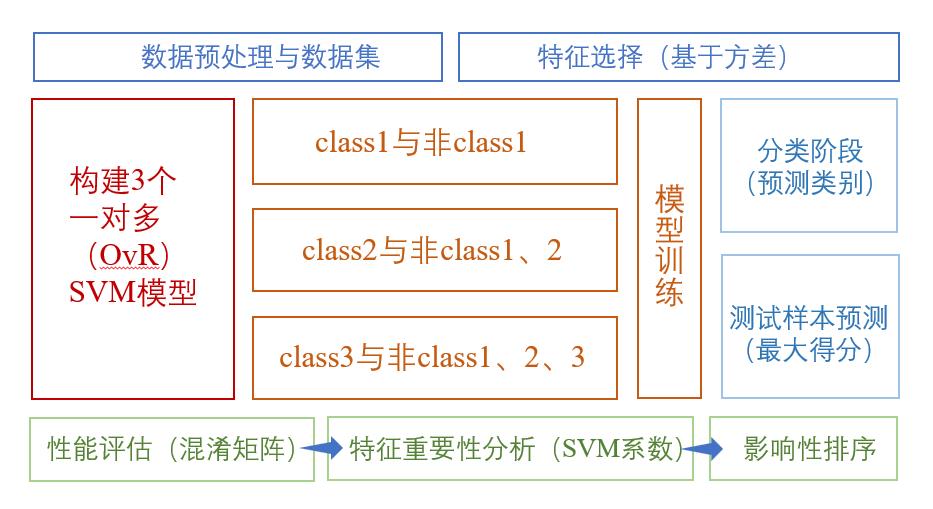
·多分类SVM 模型
在 data 数据集中有三个分子类别,需要为每个类别训练一个二分类 SVM 模型,共三个。每个模型都是一个二分类,所以需要正、负样本的划分。正样本全部来自该类别,负样本从其它两个类别中随机选择,确保数目与正样本相同。训练样本 X 即为每一类的正、负样本;再设定标签 +1 ,-1,得到样本标签 Y;其它参数均默认不设,每一类样本训练SVM 模型建立完成。
分别训练三个类别的 SVM 模型,并将训练好的 SVM 模型分别对测试样本进行预测分类,得到三个预测标签。求出测试样本在三个模型中预测为“正”得分的最大值,作为该测试样本的最终预测标签,用于判定样本类别。最后,团队利用混淆矩阵函数confusionmat 分析模型表现。为证明所构建的模型的准确性,团队在测试集上评估模型查准率、查全率和综合评价指标,结果如下表所示。
表1 模型评估指标

查准率为某个类别被预测为正类的样本中,实际为该类别的比例。查全率为某个类别中实际为正类的样本中,被正确预测为该类别的比例。综合评价指标是查准率和查全率的调和平均,结果显示接近 1,说明模型具有较好的准确性,分类策略优秀。最后,团队将用该模型将predict中数据的预测的分子分类结果填入submit 数据集。
·特征重要性分析
在上述支持向量机(SVM)模型中,团队采用的超参数优化为MATLAB 中的 fitcsvm 函数,其输出 Beta 值代表模型的系数。基于线性SVM 的系数可分析特征的重要性,识别出对分子分类结果影响最大的特征。得到三个模型的Beta 系数。
为筛选对分子分类结果影响最大的特征,将系数进行归一化处理并排序,归一化后的系数越大表明该性质对分子分类预测的影响性越大,从例子中得到分子分类影响性从高到低分别是 x1,y2,x5,x8,x6,x7,x4,x2
3. 结论与展望
本研究证实遗传算法能稳定筛选关键特征,大幅降低预测模型复杂度;神经网络通过特征自学习机制突破了传统模型的精度瓶颈。这些进展将推动机器化学家平台向更高水平的智能化发展。
参考文献:
[1]Jiang J, et al. Machine C hemist: C hallenges and Opportunities. Science China Chemistry, 2023.
[2]X iao H, et al. Integrated R obotic Platform for C hemical Synthesis. Science China Chemistry, 2023.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)