.jpg)
基于RISC-V 的局部和全局历史分支预测方法

张帅 李艳 王子健 陈佳
武汉第二船舶设计研究所 湖北武汉 430025 武汉晴川学院 湖北武汉 430204 中国地质大学 湖北武汉 430074
1 基于局部历史的分支预测方法
饱和计数器作为分支预测器的重要组件,其在面对一些具有特定规律的分支指令的预测效果并不理想。例如跳转规律为  的一条分支指令,其中 1 表示该分支跳转,0 表示不跳转。以两位饱和计数器为例,若将两位饱和计数器状态初始化为弱不跳转状态 01,在第一次执行该分支指令时,预测结果为不跳转,但实际结果为跳转,因此饱和计数器状态更新为弱跳转状态 10 在第二次执行该分支指令时,预测结果为跳转,但实际结果不跳转,状态又变为弱不跳转 01。若按此规律继续执行下去,饱和计数器的状态始终处于弱跳转与弱不跳转之间,预测准确率为 0
的一条分支指令,其中 1 表示该分支跳转,0 表示不跳转。以两位饱和计数器为例,若将两位饱和计数器状态初始化为弱不跳转状态 01,在第一次执行该分支指令时,预测结果为不跳转,但实际结果为跳转,因此饱和计数器状态更新为弱跳转状态 10 在第二次执行该分支指令时,预测结果为跳转,但实际结果不跳转,状态又变为弱不跳转 01。若按此规律继续执行下去,饱和计数器的状态始终处于弱跳转与弱不跳转之间,预测准确率为 0
对于这种跳转状态十分规律的分支指令,可以采用一个历史寄存器记录该分支指令在过去的历史跳转情况,通过该分支历史对分支指令进行预测。这样的寄存器叫分支历史寄存器(Branch History Register,BHR),这种只考虑被预测的分支指令自身过去的跳转情况的预测方法,本文称之为基于局部历史的分支预测方法。
同样是跳转规律为  的一条分支指令,若采用宽度为 2 的 BHR对该分支指令的跳转历史进行记录,则 BHR 共有四种不同的值 00、01、10、11,其中 0 表示不跳转,1 表示跳转。与之对应的是一个由四个饱和计数器构成的PHT,其结构如图1 所示。
的一条分支指令,若采用宽度为 2 的 BHR对该分支指令的跳转历史进行记录,则 BHR 共有四种不同的值 00、01、10、11,其中 0 表示不跳转,1 表示跳转。与之对应的是一个由四个饱和计数器构成的PHT,其结构如图1 所示。
图1 基于局部历史的预测方法
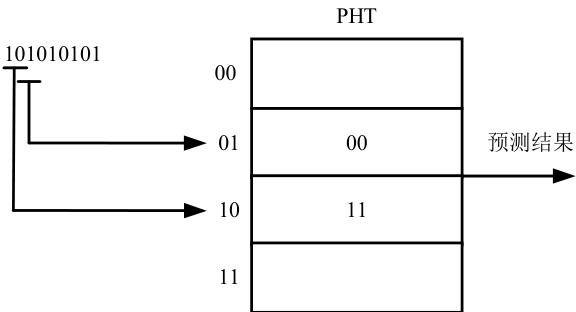
每当执行一次分支指令后将跳转结果写入 BHR 的低位,舍弃掉高位,则BHR 会交替出现01 和10 两种状态。当出现01 状态时,指向PHT 中第二个表项,由于 01 的下一次跳转情况为 0,也就是下一次该分支指令一定不跳转,因此指向 01 表项的饱和计数器会达到强不跳 00 的饱和状态,即预测该分支指令不跳转。而 10 状态的下一次分支一定跳转,于是指向 10 的表项也会被训练成强跳11 的饱和状态预测该分支指令跳转。
经过一定的训练时间后,加入 BHR 后的基于局部历史的预测方法在面对两位饱和计数器无法预测的分支指令时,能够达到十分准确的预测。以上这种跳转结果序列中每两位后面跟着的数值都是唯一的,称这个序列的最小循环周期为 2,一般采用两位的 BHR 就能捕获到这种跳转规律,对该分支指令进行很好的预测。对于一个最小循环周期为 n 的序列,可以采用任何宽度大于 n 的BHR 进行预测,但是位宽越大的 BHR 意味着需要更多 PHT 的表项,同时也需要更多的时间将 PHT 中的饱和计数器训练到饱和状态,因此 BHR 的位宽需要根据实际的分支跳转情况进行权衡。
2 基于全局历史的分支预测方法
当对一条分支指令的跳转方向进行预测时,需要考虑前序分支指令的跳转结果,这种方法本文称为基于全局历史的分支预测方法。在实际程序执行过程中,分支指令的跳转行为往往表现出不同的相关性特征。某些分支指令的跳转行为与其自身的局部执行历史密切相关,适合采用基于局部历史的方法进行预测;而另一些分支指令的跳转行为则主要依赖于其余指令的执行历史构成的全局历史,更适合采用基于全局历史的方法进行预测。例如以下例子:
If( aa==0 )//b1a=1. ;
If( bb==0 )//b2b=1 ;
If( a==b )//b3c=3 ;
可以看出,分支 b3 的执行,依赖于 b1 以及 b2 分支的执行,只要 b1 与 b2
分支均跳转,其对应的分支将会执行,即变量 a 以及 b 均会被赋值为 1,此时跳转条件 a==b 满足,分支指令 b3 一定会发生跳转。此时若采用基于局部历史的预测方法是无法通过 b1 以及 b2 的跳转规律推测出 b3 的跳转情况的,但使用基于全局历史的预测方法,记录下 b1 以及 b2 的跳转规律,即可准确预测出b3 的跳转情况。
在基于全局历史的预测方法中,同样需要一个寄存器记录所有分支指令在过去的跳转情况,这个寄存器被称为全局历史寄存器(Global History Register,GHR)。每当执行完一条分支指令后,将该指令的执行结果写入到GHR 的低位,并将高位舍弃,如图2 所示为基于全局历史的预测方法示意图。
图2 基于全局历史的预测方法
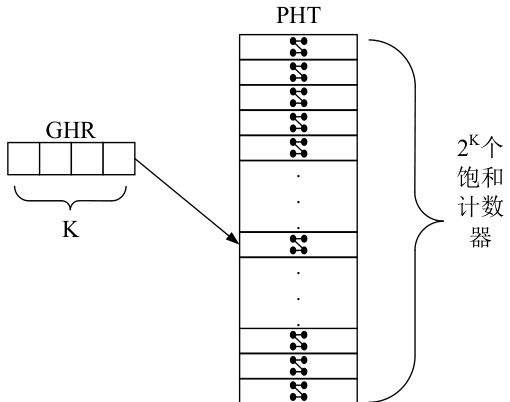
该方法利用 GHR 对 PHT 进行索引,位宽为 k 的 GHR 对应的 PHT 中饱和计数器的个数为 2k 。面对上述例子,当对分支指令 b3 进行预测时,GHR 中低两位的结果可能时 00、01、10、11 中其中的任何一种,若 GHR 中最低两位记录的值为 11,即 b1 以及 b2 两条分支指令均发生跳转,则会预测 b3 同样发生跳转。但若是其它三种情况则 b3 可能跳转也可能不发生跳转,此时的预测准确度就无法保证。最理想的情况是根据 PC 地址的不同为每条分支指令分配一个 PHT,这样每条分支指令在预测时均采用 GHR 对当前指令对应的 PHT 进行寻址,由于每条指令有着不同的 PHT,所以即使相同的 GHR 也不会寻址到同一个饱和计数器造成冲突。但如此会占用大量的存储空间,可以通过对 PC 地址进行 hash 处理,使其利用更少的位宽以区分不同的分支指令,就能使用更少的 PHT0 。最简单的方法就是只使用一个 PHT,缺点是会发生 GHR 相同的不同分支指令共同访问同一个饱和计数器的情况。当这两条分支指令跳转方向相同时,彼此之间就不会造成负面影响,甚至能使饱和计数器更快速的被训练至饱和状态。但是若两条分支指令跳转方向不同,则会不断的更改饱和计数器的值,使其无法到达饱和状态。
.jpg)
.jpg)
.jpg)
.jpg)