.jpg)
视觉一语言多模态翻译技术研究

杨佩 尤国强 焦永禄
西安翻译学院信息工程学院 西安市710105 西安讯飞超脑信息科技有限公司 西安市710076
1. 引言
1.1 研究背景
近年,深度学习推动了人工智能翻译的发展。借助深度学习,许多有关外文翻译的问题都得到了很好的解决。但随着手机等智能设备的普及以及各类社交媒体平台的流行,外文信息的获取、传递和翻译已经逐渐从单一文本模态数据转变为图像、视频等多种模态数据的融合。因此,针对多模态信息数据的翻译、理解和推理研究将推动人工智能翻译更深层次的应用、推广和落地。在人工智能翻译的多模态研究进展方面,可从机器翻译算法、翻译场景中语言、图像的多模态特征提取和数据融合等方向来了解相关研究现状。
(1)机器翻译算法。机器翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。近年,随着数据的增加和计算资源的发展,基于深度学习的算法[1–3]是解决机器翻译问题的主流方法。由于机器翻译模型的输入和输出都是连续的一句话或者一段话,因此,序列编码—序列解码的模型[4]是解决机器翻译的一个自然选择。对于输入源语言,可以使用一个能够处理序列的模型[5],例如长短记忆网络(LSTM)[6]或门控循环单元(GRU)[7]来得到整个输入序列的表示。然后,以这个表示作为输入,可以使用一个序列解码的模型来逐步的输出翻译序列。序列编码—序列解码模型不仅可以捕捉到整个序列的表示,而且还可以利用之前步骤输出的信息,从而增强了输出语句的准确性与连贯性。鉴于这种优势,后续发展的机器翻译模型基本都是基于序列编码—序列解码的思想而设计。特别的,由于长短记忆网络不能有效的存储长期信息[8],Jonas等人[9]和Ashish等人[10]分别提出了基于卷积的序列生成模型(如图1左侧所示)和Transformer序列生成模型(如图1右侧所示)。通过使用分层的结构,这两种模型可以有效的捕捉序列信息,缓解了长期信息的损失。此外,Transformer序列生成模型[10]使用了注意力机制,可以有效的在每层捕捉到与输出相关的信息,从而缓解了信息的损失,提高了翻译的准确性。基于Transformer序列生成模型,Devlin等人提出了一个用于语言理解的预训练的双向Transformer模型[11]。在多个机器翻译任务上,这两个模型都取得了优越的性能。
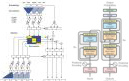
(a) 基于卷积的序列模型
(b) Transformer 序列模型
图1 基于卷积的序列翻译模型和Transformer 翻译模型
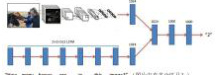
(2)文本、图像、视频等多种模态数据融合的人工智能翻译研究。Antol等人[12]研究了文本、图像、视频等多种模态数据条件下的信息识别问题,该问题建立了一个视觉问答系统模型,其以图像和对应的语句问题作为输入,输出问题对应的答案。该研究的挑战是需要模型充分的理解视觉及其对应语句问题的内容。然后,基于视觉内容与问题内容的对应关系,推出正确的答案。目前,基于深度学习的算法是解决这个问题的主流方法。种简单的解决方案[12]如图2所示。对于图片,这种方案使用深度图像识别模型提取视觉特征。对于语句问题,这种方案使用长短期记忆网络,即LSTM,提取语言特征。然后,对视觉特征和语言特征进行融合(使用的对应元素相乘的操作)。最后,基于融合的特征,模型输出对应问题的答案。这种方法提供了解决视觉问答的基本框架。从图2可以看到这个框架主要包括四个模块,即 1)视觉特征提取模块、2)语言特征提取模块、3)视觉和语言特征融合模块和4)答案推理模块。后续提出的方法基本都是在这四个模块的基础上进行改进。
图2 基于语言和图像的多模态信息提取方法
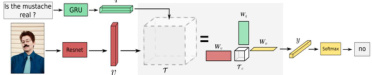
由于视觉特征和语言特征属于两种不同的模态,因此,设计一种有效的方法融合这两种模态的特征是一种自然的选择。多模态融合的本质是生成一个新的特征。这个新的特征能够充分的包含两种不同模态特征的信息。常用的多模态融合方法包括元素间加和、元素间相乘和拼接操作。由于不同模态的特征向量位于不同的特征空间中,多模态向量的对应元素之间可能不存在相互作用或相互关联。因此,这些方法并不能有效的融合多模态特征。为此,Fukui等人[13]提出了一种双线性多模态融合的方法。通过使用外积运算,这种方法能够让视觉特征和语言特征中的对应元素充分的融合。然而,这种方法对高维度特征是有效的。对于低纬度特征,效果不明显。为此,Kim等人[14]提出了一种改进方法。这种改进方法对于低纬度特征依然有好的效果。但是,这种改进方法的收敛速度却很慢。Yu等人[15]提出了一种新的改进方法。这种方法融合了上面两种方法的优点,在视觉问答任务上证明是有效的。此外,基于双线性多模态融合,Ben-younes等人[16]提出了一种基于张量分解的多模态融合算法。如图3所示,这种方法通过对视觉和语言特征进行分解,从而能够得到准确且丰富的多模态融合特征。
图3 基于张量分解的多模态融合算法
1.2 研究意义
随着智能手机、家用电脑和移动网络的普及以及微信、微博、抖音和知乎等社交媒体的流行,外文翻译和交流已经不再局限使用单一的模态信息,而可能同时使用多种模态信息,例如,文本、图像和视频。当前我们正处于一个媒体大数据时代,海量的图像、视频、文本和音频等多媒体数据快速涌现,多媒体信息的使用不仅有助于我们更好的进行交流,而且还有助于我们更加全面的了解事物。通常,多媒体数据类型多样、来源广泛、关系复杂、呈现出跨模态特性,因此,面向多模态数据的外文翻译、理解和推理就成为了一个挑战性的问题。
此外,跨媒体分析推理技术是国家《新一代人工智能发展规划》中建立新一代人工智能关键共性技术体系中的重点攻关技术之一,是国家人工智能发展的核心方向。鉴于此,本课题拟对视觉和语言两种常见模态在外文翻译的理解和推理方面进行研究,分别从多模态联合表达、理解、推理和交互四个方便进行探索,以有效提高多媒体时代背景下,图片、视频中外文翻译的合理性和准确度。
2. 视觉—语言多模态融合方法
2.1 总体研究思路
本文的总体研究思路是:将语言信息和视觉信息视为两个不同模态,通过分别对视觉—语言多模态融合、视觉内容语义描述生成、翻译表达和推理等方面开展研究,形成“视觉—语言”跨模态翻译理解和推理的理论方法框架,并在“视觉—语言”人机翻译交互方面进行应用探索。
2.2 研究目标
针对人工智能多模态研究方面的研究现状和存在问题,本问研究了解决视觉—语言多模态特征融合不充分以及视觉常识推理中翻译上下文建模弱和推理不合理的问题,具体研究目标为:
(1)为了解决视觉—语言多模态特征融合不充分的问题,本课题将研究新的多模态融合算法,新算法的计算目标是为了让多模态特征元素之间充分交互,以在视频描述生成和外文翻译的时序行为定位任务上有效进行两种模态的跨模态融合,提高多媒体场景下外文翻译的准确性。
(2)为了解决视觉常识推理中翻译上下文建模弱和推理不合理的问题,本课题将研究一种连接认知网络模型。该模型的建立和求解目标是能够通过对图形、视频中的视觉元素模块进行视觉元素连接、情景化连接以及用于推理的有向连接,来实现动态捕捉视觉信息,提高视觉常识推理数据集的应用合理性,以有效提高多媒体场景下外文翻译的合理性本文提出的的技术实现路线如图4所示。
图4 多模态融合技术实现路线图

2.3 视觉—语言融合方法
随着手机等智能设备的普及以及社交媒体和网购平台的流行,外文翻译场景常常已经不再局限于一种单一的模态信息,而是同时使用多种模 前我们正处在一个媒体大数据时代,海量的图像、文本、音频和视 常针对单一模态数据比较有效,而用于处理多模态数据的算法则 中 希望设计的翻译算法能够有效的处理多模态数据,因此本课 题将重点研 多模态数据的特征提取和融合的方法,以提高“视觉—语言”跨模态理解性能,增强多模态场景下外文翻译的准确性。
另外,在具有图像或视频的复杂翻译场景中,有时仅基于图像信息很难得到合理的翻译结果,这就需要翻译算法模型必须能够根据提取的视觉和语言特征进行准确的推理。现有的视觉—语言分析算法仅关注于将两种模态的信息内容进行准确关联,很少使用推理的方法处理翻译的上下文合理性。为此,本课题还将重点研究人工智能翻译算法的认知网络模型,以提高“视觉—语言”跨模态推理性能,增强多模态场景下外文翻译的合理性。
常用的多模态融合方法包括特征元素间求和、特征元素间乘积和特征拼接。然而,由于多模态特征处于不同的特征空间中,特征对应元素之间并不总是存在相关性。特征对应元素间求和、乘积和特征拼接仅仅是部分的探索了多模态特征间的对应,并没有很好的融合多模态特征,且跨模态计算中大量的矩阵运算会大大增加模型的复杂度和计算量,因此本课题的一个研究难点是如何进行多模态特征融合的精准建模,并减小计算规模,以提高“视觉—语言”跨模态理解性能。
在多模态场景下,为了实现语言翻译中更全面的视觉理解,翻译算法模型必须从感知转向推理,其中包括具有场景相关细节和相关常识的认知推理。目前已有的认知网络推理模型将语言翻译和视觉表示分别处理,该推理方式与人类大脑的认知方式存在巨大差异,还不能达到人类的认知高度,因此如何建立具有全局、动态推理特征的有向认知网络推理模型,以动态的捕捉高层次视觉语义信息,是增强多模态场景下外文翻译合理性研究中的难点问题。
与上面的研究内容相对应,本文的研究方法可归纳为以下两点。
(1)针对视觉—语言多模态特征融合不充分的问题,分别提出多模态循环矩阵融合和多模态交叉卷积融合方法。其中,循环矩阵融合方法用于利用 言特征,然后通过矩阵乘法实现多模态信息的充分融合;交叉卷积融合方法用于构造视觉 语言特征卷积核,然后通过卷积运算以实现多模态信息的融合。通过这两种多模态融合方法可以提高多个“视觉—语言”跨模态理解任务的性能。
(2)针对视觉常识推理中翻译上下文建模弱和推理不合理的问题,由神经科学中关于大脑连接和认知研究的启发,研究一种基于人脑理解形式的连接认知网络模型。在该模型通过建立一个基于图的局部聚合描述模块,来动态的捕捉与语言内容相匹配的视觉信息。同时,考虑到推理往往具有方向性,研究中将在模型中添加一个基于图的有向推理模块来获得更为正确合理的翻译结果,以提高多个“视觉—语言”跨模态理解任务中的翻译性能,提高多模态条件下外文翻译的合理性。
3. 总结
随着智能设备和社交媒体的普及,外文翻译和交流已逐渐使用多种模态信息,因此面向多模态数据的外文翻译、理解和推理成为挑战性问题。跨媒体分析推理技术是国家人工智能发展的核心方向之一。针对文本、图像、视频等多种模态数据融合的人工智能翻译研究,目前流行的基于深度学习的算法,可以进行视觉问答系统模型和多模态融合方法,实现大幅度提高译文质量的效果。
总的来说,本文研究内容深入探讨了人工智能翻译中多模态信息数据的研究现状、价值、目标、内容和方法,为进一步提高多媒体场景下外文翻译的合理性和准确度提供了理论支持和技术路径。
致谢
本文研究工作受到人工智能翻译陕西省高校工程研究中心资助。
参考文献
[1] Kang L, He S, Wang M, et al. Bilingual attention based neural machine translation[J]. Applied Intelligence: The International Journal of Artificial Intelligence, Neural Networks, and Complex Problem-Solving Technologies, 2023.
[2] Jian L, Xiang H, Le G. LSTM-Based Attentional Embedding for English Machine Translation[J]. Scientific Programming, 2022, 2022: 1-8.
[3] Oda Y, Arthur P, Neubig G, et al. Neural Machine Translation via Binary Code Prediction[C].Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Vol-ume 1: Long Papers), 2017,1:850–860.
[4] Sutskever I, Vinyals O, Le Q V. Sequence to Sequence Learning with Neural Networks[C].Advances in Neural Information Processing Systems 27, 2014:3104–3112.
[5] Chung J, C¸aglar Gülc ¸ehre, Cho K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv:1412.3555, 2014.
[6] HochreiterSepp, SchmidhuberJürgen. Long Short-Term Memory[J]. Neural Computation, 1997.
[7] Cho K, van Merrienboer B, Bahdanau D, et al. On the Properties of Neural Machine Trans-lation: Encoder–Decoder Approaches[C]. Proceedings of SSST-8, Eighth Workshop on Syntax,Semantics and Structure in Statistical Translation, 2014:103–111.
[8] Weston J, Chopra S, Bordes A. Memory Networks[C]. ICLR 2015 : International Conference on Learning Representations 2015, 2015.
[9] Gehring J, Auli M, Grangier D, et al. Convolutional sequence to sequence learning[C]. Proceed-ings of the 34th International Conference on Machine Learning - Volume 70, 2017:1243–1252.
[10] Vaswani A, Shazeer N, Parmar N, et al. Attention is All You Need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017:5998–6008.
[11] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]. NAACL-HLT 2019: Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2019:4171–4186.
[12] Antol S, Agrawal A, Lu J, et al. VQA: Visual Question Answering[C]. 2015 IEEE International Conference on Computer Vision (ICCV), 2015:2425–2433.
[13] Fukui A, Park D H, Yang D, et al. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding[C]. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016:457–468.
[14] Kim J H, On K W, Lim W, et al. Hadamard Product for Low-rank Bilinear Pooling[C]. ICLR 2017 : International Conference on Learning Representations 2017, 2017.
[15] Yu Z, Yu J, Fan J, et al. Multi-modal Factorized Bilinear Pooling with Co-attention Learning for Visual Question Answering[C]. 2017 IEEE International Conference on Computer Vision(ICCV), 2017:1839–1848.
[16] Ben-younes H, Cadene Cord M, al. MUTAN: Multimodal Tucker Fusion for Visual Question Answering[C]. 2017 IEEE International Conference on Computer Vision (ICCV),2017:2631–2639.
.jpg)
.jpg)
.jpg)
.jpg)