.jpg)
基于深度学习的中文商业事件检测方法

钟慎杰
齐鲁工业大学(山东省科学院菏泽校区)(分院) 山东菏泽 274000
0 引言
随着互联网的日益普及以及 Web 信息的爆炸式增长 , 各大新闻门户网站如雨后春笋般涌现 , 为新闻事件提供了一个较为权威的发布途径。在商业领域,这些新闻对企业来讲是一个丰富且意义重大的信息库。然而企业用户获取的信息通常是海量的、局部的、碎片化的。用户很难把握和理解商业事件。有效抽取信息,检测商业事件,成为一项亟待解决且富有挑战性的工作。
事件抽取,也称为事件提取、事件识别或事件分析,旨在从海量的非结构化文本中抽取出人类感兴趣的内容,将其表示并储存为便于人和计算机后续处理和应用的结构化信息 [1]。分为两个子任务,事件检测和参数提取。
事件检测指从一段文本中提取标志事件,包括事件触发词识别与事件类型分类。触发词是指直接引起事件发生的词语,触发词的词性为动词或表示动作或状态的名词。例如 “今日凌晨 2 点,美联储降息25 个基点,10 年来首次”。其中触发词为“降息”,事件类型为“财经/ 交易- 降息”。
在英文中单词有明显边界,但是中文词汇边界模糊。中文事件抽取存在语义表征不充分、特征提取不全面等问题。本文采用深度学习模型 BERT,它利用大规模无标注语料训练、获得文本丰富语义信息语义表示,将语义表示在特定 NLP 任务中作微调,最终应用于该NLP 任务, BERT 预训练后产生的向量的语义表征会更充分。
本文的主要贡献如下:
(1)本文提出了一种预训练的事件检测模型,使用事件类型标注器提取所有可能的事件类型,后将事件类型作为先验条件融入语义信息,不仅加强了子任务之间的交互,还能避免抽取出冗余的触发词。
(2)本文在中文事件抽取数据集上进行了实验,结果表明模型在事件抽取的任务上均取得了较好的性能。
1 相关工作
中文事件抽取不仅存在比英文更加严重的数据稀缺问题 , 而且也存在方法和语言特性的问题 . 中文语言词语间没有显式间隔 , 进行分词时会出现比英文更加明的误差。中文语言的复杂性和灵活性让相同语义的词语、短语和句子有更多表达方式 , 即同一类型事件触发词可以使用更多词语表达。
近年来,深度学习大力发展,相比较于基于机器学习的方法,不需要借助外部自然语言处理工具的同时也降低了人工成本。基于深度学习的方法通常为联合抽取模型,田梓函 [2] 提出一种基于预训练模型与条件随机场相结合的事件检测模型。李熠 [3] 提出了一种基于 Fin-BERT 和 PTPCG 的模型 Fin-PTPCG,该方法充分利用 Fin-BERT 预训练模型的表达能力,更好的完成了事件抽取的任务。
2 模型设计
本文设计一种基于深度学习的事件检测抽取模型,该模型通过BERT 和 MLP 进行事件检测。
2.1 文本特征提取
文本特征提取器采用 BERT, 在训练速度和准确率方面相对于其他的预训练模型有更好的表现。Trans‐former 在文本分类、命名实体识别等多个领域均被证明是有效的。
进过预处理的文本数据,送入已经预训练完毕的 BERT 中,输出特征向量,特征向量作为下一步的输入。
2.2 事件检测分类和触发词检测
经过 BERT 训练过的向量,送入事件检测分类器中,分类器为二
层感知机,第一层为全连接层加激活层,第二层为全连接层 . 激活函数为RELU 函数,经过事件检测分类器后,得到预测的事件类型。
数据在送入 BERT 的同时,运用 jieba 分词工具对句子进行分词,将分词完的词语同时送入 BERT 的到词向量,将事件类型分类和词向量结合起来检测句子中的触发词。
3 实验设计
3.1 数据集信息
本文的数据集来自于百度中文数据集的商业和金融事件部分,进行了一系列实验评估来验证模型的性能, DuEE 是一个大型中文事件抽取数据集,从中筛选出商业领域相关的事件部分,共得到 835 个事件,其中563 条做训练集,272 条做测试集。
3.2 评价指标
对于事件检测任务,本文分别对模型在以下任务的表现进行评估:触发词识别、事件类型识别。
在深度学习学习领域,评价模型性能是至关重要的一步,可以从中不断调整模型的算法及参数,以提高模型的准确性、鲁棒性和泛化能力。本文采取的是精准率,召回率,F1 作为评价指标。
3.3 实验过程
将数据集进行简单的处理,加载预训练的 BERT 模型,在训练分类器的过程中,采用了正则化和学习率逐步递减的方式防止过拟合。经过分类器训练完,得到事件类型分类。同时,基于 jieba 对测试集文本进行分词,将分词输入 BERT,得到词向量。将分类结果和词向量一起预测触发词。
3.4 实验结果与分析
事件检测任务建模为多分类任务,所实现的对比模型及效果见表3,
表3 事件检测性能对比
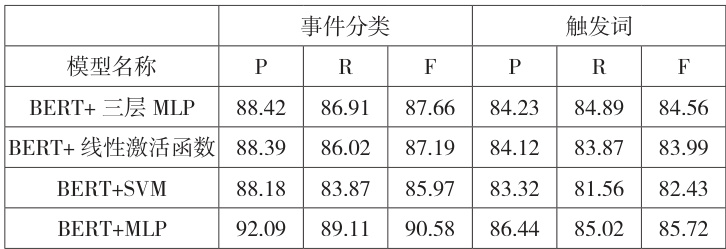
由表 3 数据可知,本文提出的方法在事件分类和触发词提取模块的精准率、召回率和F1 值高于其他模型,表明的模型的有效性。
4 结论和未来展望
本文提出了一种中文商业事件检测方法,利用 BERT 预训练模型获取向量表示,利用 MLP 进行事件类型分类,将分类结果送入触发词检测模块中,提高了触发词的检测能力,目前现在的事件检测方法大都基于文本数据进行检测,忽略了新闻网站上的图像、语音、视频等多模态信息。所以下一步研究方向的重点是多模态信息的分析。
参考文献
[1] 郭 喜 跃 , 何 婷 婷 . 信 息 抽 取 研 究 综 述 [J]. 计 算 机 科学 ,2015,42(02):14-17+38.
[2] 田梓函 , 李欣 . 基于 BERT-CRF 模型的中文事件检测方法研究 [J]. 计算机工程与应用 ,2021,57(11):135-139.
[3] 李熠 , 耿朝阳 , 杨丹 . 基于 Fin-BERT 的中文金融领域事件抽取方法 [J]. 计算机工程与应用 ,2024,60(14):123-132.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)