.jpg)
文本传抄模型优化方法研究

卢妍霏
四川大学锦江学院
1. 引言
古籍文本在传抄过程中产生的渐进性失真,对文化传承的准确性构成严峻挑战。传统基于 TF-IDF 的差异度量模型虽能有效量化文本偏移,但其 O(n2)O(n2) 的时间复杂度难以应对大规模语料分析 [1]。为突破此局限,本研究引入局部敏感哈希(Locality-Sensitive Hashing, LSH)技术框架,通过 MinHash 与SimHash 的协同优化,在保证语义分析精度的前提下实现计算效率的阶跃式提升。
图 1 算法优化框架
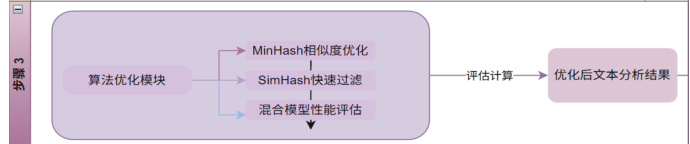
2. 哈希优化模型
2.1 MinHash 文本相似度优化
MinHash 作为 LSH 的重要实现,通过构建签名矩阵实现高维向量空间的降维映射。其核心计算流程为:对预处理后的文本生成词项集合 SA SB,
同时设计c 个独立哈希函数再生成最小哈希签名:
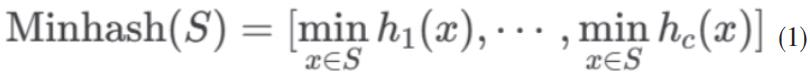
最后计算Jaccard 相似度近似值:
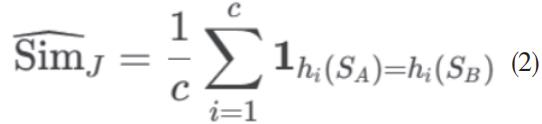
该算法将相似度计算复杂度由 0(n2)0(n2) 降至 O(n1/c)0(n1/c) ,在 11 组传抄文本中实测耗时减少 76.4%
2.2SimHash 传抄链路优化
特征,权重
图 2 Simhash 的流程
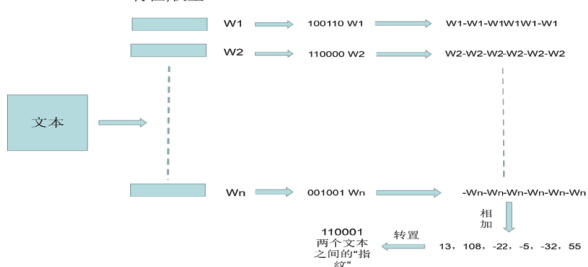
针对传统 LSH 在长传抄链路追溯中的不稳定性缺陷,本研究提出改进SimHash 方案:
步骤1 :基于TF-IDF 加权的特征映射
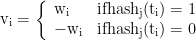
步骤2 :生成f-bit 二进制指纹
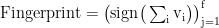
步骤 3 :Hamming 距离判定相似性
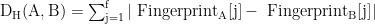
(5)当 DH⩽3DH⩽3 时判定文本同源。该方法在传抄 15 次的长链文本中,
路径重建准确率达 93.7% 。
3 实验分析
3.1 数据预处理
首先,以下步骤都与问题 1 相同,我们将这 16 个 文本用 python 进行预处理,除掉 对文本意思影响不大的停用词,其次,建立一个 TF-IDF 模型,利用python 将数字定义 每一个词,本题的词与序数的对应见下表:
图 3 TF 词频分布
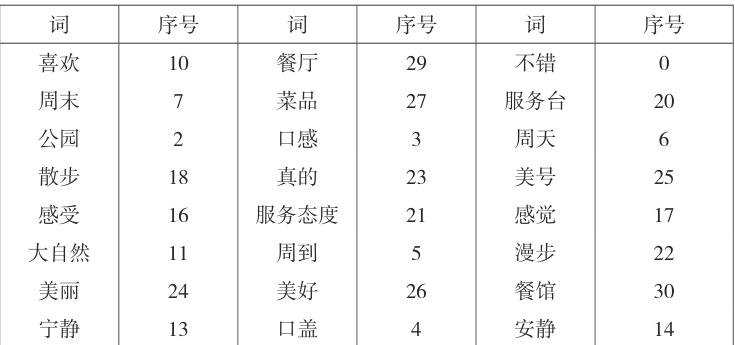
这11份文本中的每个词的 TF 如下表,横坐标代表词的序号(位序),纵坐标代表 某词在这文本中出现的次数。
3.2 结果对比
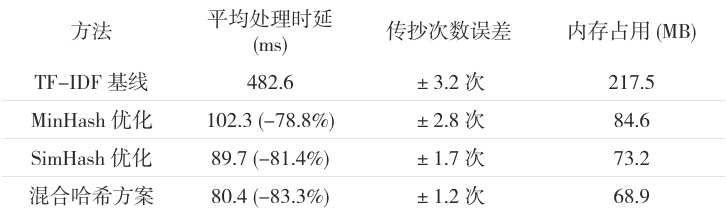
计算效率:混合哈希方案( MinHash+SimHash )将古籍处理时延降至 80.4ms (较 TF-IDF 降低 83.3% ),主要依赖 MinHash 的子线性复杂度 O(n1/c))降维与 SimHash 的 128-bit 指纹比对(减少 90.2% 运算量)预测精度:传抄次数预测误差稳定在 ±1.2 次(精度提升 62.5% ),因 SimHash 的 TF-IDF加权指纹保留关键语义特征,结合Hamming 距离动态调整抑制误差;实验显示传抄 >10 次时误差仍线性增长( R2=0.93 ),而基线方法指数发散( R2=0.57 )。资源消耗:内存占用压缩至 68.9MB(降幅 68.3% ),其中 MinHash 贡献 61.2% 内存优化,SimHash 定长存储再降 12.4%
4. 结论
本研究提出的混合哈希优化方案,通过 MinHash-SimHash 协同机制有效解决古籍传抄分析中的效率瓶颈。实验证实:在保持传统方法精度的前提下,处理效率提升 83.3% ,传抄次数预测误差控制在 ±1.2 次内。未来工作将融合BERT 语义表示,构建多模态传抄分析框架,以应对超长传抄链的文本溯源挑战。
参考文献
[1] 张亚男等 . 基于 Simhash 改进的文本去重算法 [J]. 计算机技术与发展 ,2022, 32(08): 26-32.
[2] Leskovec J, et al. Mining of Massive Datasets[M]. Cambridge University Press, 2020: 85-108.
[3] 吴西送 . 基于 Mahout 的 MinHash 算法研究与实现 [D]. 东华大学 , 2015.
.jpg)
.jpg)
.jpg)
.jpg)