.jpg)
基于机器学习的清河流域城市内涝风险评估

董肖依
中国中元国际工程有限公司 北京市 100089
1. 引言
近年来,受全球气候变化影响,极端天气事件频发,城市内涝问题日益凸显,已成为城市安全与可持续发展面临的重要挑战。在北京等超大城市,高比例的不透水地面、复杂的地形条件以及排水系统设计标准滞后等问题,进一步加剧了极端降雨下的内涝风险。传统的基于物理机制的水文水动力模型虽然具有良好的理论基础,但存在对高分辨率数据依赖强、计算负荷大、难以在大范围或实时场景中快速应用等局限。
为应对上述挑战,近年来,数据驱动方法——尤其是机器学习在城市内涝风险评估中的应用日益受到关注。机器学习模型能够在不依赖显式水力公式的情况下,从多源数据中学习非线性关系,在城市积涝的识别与预测中表现出良好的适应性与精度。
本研究以清河流域为研究对象,该区域是城市典型的积涝高发区,曾在极端降雨事件中多次发生严重积水。研究基于地形、气象与社会经济三大类共十个风险因子,构建包含 30 个历史积水点与 200 个非积水点的训练数据集,采用 GBDT 与 XGBoost 两种机器学习模型进行训练与性能比较,评价指标包括准确率、F1 值与 AUC 等。同时,通过空间预测与特征重要性分析,识别高风险区域与主要致涝因子,为城市精细化防涝规划与设施优化提供支撑。
2. 模型算法
2.1 GBDT 梯度优化决策树(Gradient Boosting Decision Tree)
GBDT 通过采用加法模型以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。它通过多轮迭代 , 每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的(为了降低方差)。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
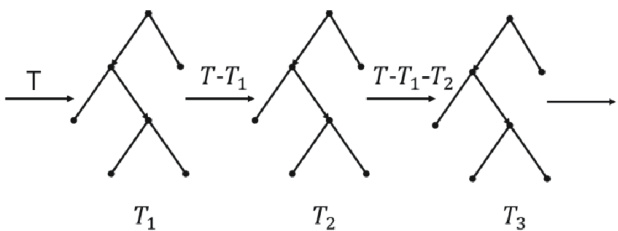
从图 1 可以看出,GBDT 的训练过程是线性的,无法像随机森林一样并行训练决策树。第一棵决策树训练的结果与真实值的残差是第二棵树训练优化的目标,即,第三棵树训练优化的目标是真实值与第一棵和第二棵决策树训练的结果和的残差,即,以此类推,最终模型得到的结果是将每一棵决策树的结果进行加和得到的,即。
2.2 XGBoost
XGBoost 对代价函数做了二阶泰勒展开,同时用到一阶和二阶导数信息,这样可以更精准的逼近真实的损失函数,提升算法框架的精准性,基于二阶导数信息能够让梯度收敛的更快。同时,XGBoost 在代价函数里加入正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的预测值的 L2 的平方和,正则项有利于降低模型的方差,使学习出来的模型更加简单,防止过拟合。
3. 研究方法与技术路线
本研究以清河流域为研究范围,结合多源空间数据与机器学习方法,构建城市内涝风险评估模型。
为全面反映城市内涝的致灾环境,本研究从地形、气象和社会经济三大维度选取十类因子,分别为:高程、坡度、河网密度、道路密度、离道路距离、NDVI、人口密度、GDP 密度、年均降雨量和6–8 月降雨均值。
3.1 数据处理
所有数据均统一投影、栅格化处理,并重采样至相同空间分辨率。对栅格数据进行归一化标准化操作,以消除量纲差异对模型训练的影响。
3.2 样本构建与特征提取
根据前期调研资料与市政积水事件记录,选取清河区域内 30 个典型积水点作为正样本。同时,采用 ArcGIS 工具在无积水记录区域随机生成 200 个非积水点作为负样本。在每个样本点位置提取对应网格的十个特征因子值,构成训练数据集。
3.3 技术路线
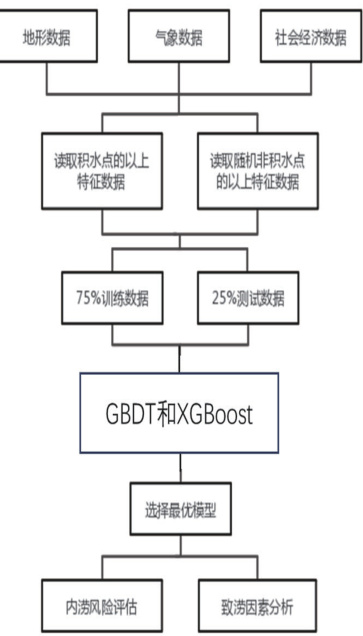
采用Python 语言构建城市内涝风险评估流程,整体技术路线包括:多源数据处理、训练样本构建、机器学习模型训练与优化、内涝风险预测与可视化、主导致涝因子提取等五大步骤。首先,基于积水点及非积水点空间位置,提取其对应网格的特征值,并通过周边采样方式扩充训练样本集。然后选取两类典型机器学习模型 GBDT 与XGBoost 进行建模评估。
4. 结果与分析
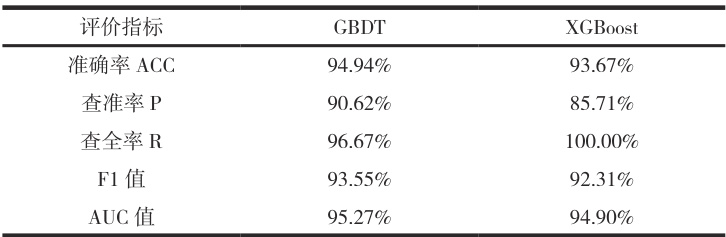
在使用默认参数的情况下,GBDT 和XGBoost 模型对清河流域做积水点预测,选取准确率、查准率、查全率、F1 值和 AUC 值作为评判模型预测效果的指标,如表 2 所示,GBDT 算法除了在查全率上稍逊色于 XGBoost 算法,另外四项指标均为最优,所以选择 GBDT 模型作为最终预测模型。
4.1 内涝风险可视化
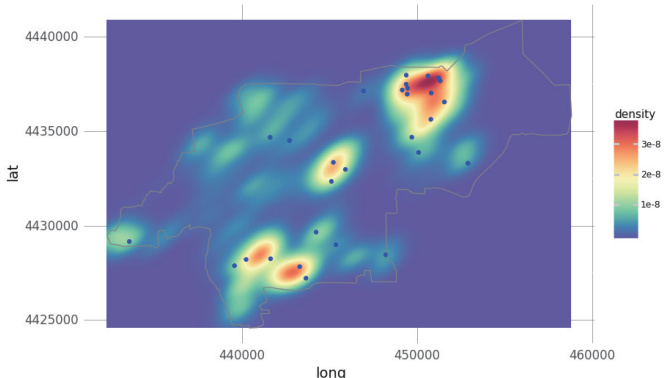
使用模型对清河流域的积水点进行预测,得到预测结果后通过高斯核密度法对输出数据进行处理,以做出可视化的内涝风险密度图,结果如图3 所示。
4.2 清河流域致涝因素
通过 GBDT 算法对清河区域致涝因素进行分析,对清河流域内涝风险影响较大的前三个因素依次是坡度、离道路距离及高程。
5. 结论与建议
本研究以清河流域为例,构建了融合多源数据与机器学习的城市内涝风险预测模型,验证了 GBDT 算法在城市内涝空间识别中的高精度与强泛化能力。研究成果为北京清河区域城市内涝综合治理提供了决策参考,建议相关部门可基于模型成果进一步加强重点区域监测点布设,优化排水基础设施设计,提升精细化预警水平。后续研究可引入实时气象与雷达数据,结合动态模拟与深度学习模型,实现从静态评估向动态预报的升级,提高城市面对极端降雨的应急响应与主动防控能力。
.jpg)
.jpg)
.jpg)
.jpg)