.jpg)
基于双模态时空特征融合的毫米波雷达语音识别系统

周楷翰 王心意 张晗豫
天津工业大学 天津市 300387
引言
普适计算和无线通信的飞速发展促使移动互联应用迅猛崛起。作为人机互联的重要手段,语音识别在智能驾驶、线上会议、智慧养老等众多场景中扮演重要角色。例如,在智能驾驶场景,语音识别能够帮助驾驶人减少手动操作,降低驾驶安全隐患[1];在线上会议场景,语音识别可将人声转换为速记文本,提升会议记录效率[2];在智慧养老场景,语音识别能够为行动不便、视力不佳、功能障碍的老年人提供紧急呼叫、健康监测等环境感知服务,提升老年人生活质量[3]。伴随第五代演进通信网络和第六代通信网络的兴起,新型移动互联网将为语音识别提供更加广泛的应用场景,并对其性能提出更要要求。
现有语音识别技术主要为基于麦克风的语音识别方案[4-6]。基于麦克风的方案通过近距离或喉部麦克风采集语音信号,并结合知识蒸馏、噪声抑制等技术提升识别性能,但其易受环境噪声、多径效应及远距离信号衰减的制约。
近年来,毫米波雷达凭借高分辨率、强抗干扰能力及对微米级运动的敏感性,在非接触式感知领域崭露头角。研究表明,毫米波信号可穿透衣物并捕捉唇部振动、声带运动等生理特征,为语音识别提供了新的技术路径。例如,VocalPrint 系统通过毫米波信号提取声道特征实现身份认证[7],而多模态融合方案利用毫米波与音频信号的互补性提升噪声环境下的识别精度[8]。然而,现有研究仍面临动态干扰抑制不足、信号衰减敏感及模型复杂度高等挑战,制约了其规模化应用。
针对上述问题,本文提出一种基于毫米波雷达的双模态高精度语音识别系统。该系统同时捕捉声带振动特征与唇部运动特征,同时设计双通道差分信号处理机制,结合卡尔曼滤波运动补偿算法,消除头部运动以引起的动态干扰,确保特征提取的稳定性。在信号处理层面,本文构建了分层注意力驱动的多模态融合网络,并且采用卷积神经网络提取毫米波时频图特征并通过空间注意力聚焦关键频段,引入Transformer 模块建模唇部与声带运动的时序关联性,结合跨模态注意力机制融合毫米波信号增强语义表达的鲁棒性。
1 提取信号特征
1.1 信号预处理
本文利用毫米波雷达发射FMCW 信号采集唇部和声带信号特征,并采用波束成形技术将信号能量集中到指定区域,如图1 所示。
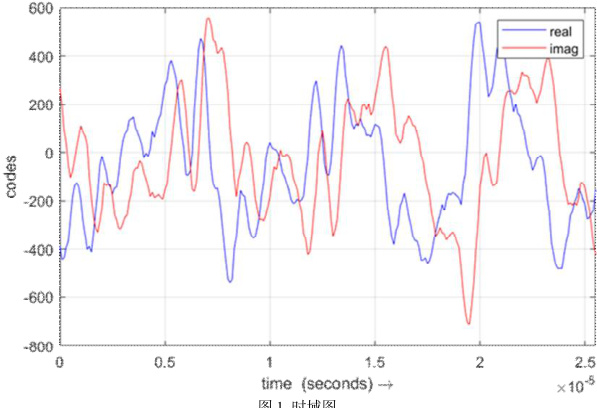
为了估计嘴唇和喉部的运动,我们对接收到的信号在快速时间窗口进行 Range-FFT 运算,在慢速时间窗口进行 Doppler-FFT 运算,如图 2 所示:
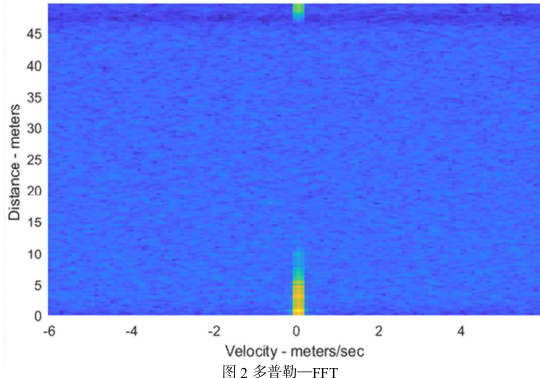
然后,我们就可以获得包含嘴唇和声带运动的相位信号。
1.2 动态干扰抑制
我们使用卡尔曼滤波去除动态干扰,从唇部运动所在的相邻范围区间估计动态干扰信号,表示为
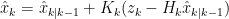
其中 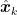 是干扰信号的动态特性,结合实际观测值 zk ,计算卡尔曼增益 Kk ,更新状态估计
是干扰信号的动态特性,结合实际观测值 zk ,计算卡尔曼增益 Kk ,更新状态估计
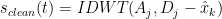
由公式(3)可得到无动态干扰的唇部运动信号。
1.3 语音活动检测
为了有效区分语音活动和非语音活动,本文利用毫米波雷达记录声带振动信号和唇动信号并利用交叉验证来对唇部运动和声带振动进行分类。在进行唇动预检测的过程中,我们使用基于阈值的能量检测算法估计窗口内唇动信号的能量强度,将唇部运动信号分割成长度为 Δτ 的窗口段,然后在窗口内计算能量强度 El(t,t+Δτ) ,进一步验证与声带振动特征的一致性。之后,项目组拟使用滑动窗口dt 进行声带振动信号的检测,重叠率为窗口长度的一半,根据辅音和元音交替原则计算每个窗口的能量 El(t,t+Δτ) ,此外,系统拟在 τ 窗口内获得唇部运动频谱图的能量El )和声带振动信号的能量 Eν(τ) ,为了综合考虑唇部运动和声带振动的能量,使用Concat 运算将唇动能量 El(Δτ) 和声带振动能量 Eν(Δτ) 将它们连接起来,合并得到最终的能量 E(Δτ) ,表示为
E(Δτ)=Concat(El(Δτ),Eν(Δτ)).
进一步,利用支持向量机对语音检测能量进行分类,其中正样本为语音活动信号,负样本为非语音活动信号。
2 双模态时空特征融合
嘴唇运动和声带振动分别从宏观和微观角度代表人类的语音信号。毫米波雷达可以同时感知嘴唇运动和声带振动,通过融合声带微振动特征和嘴唇宏观运动特征,提高多模态特征的互补性,并使用多通道和自注意机制融合声带振动特征和嘴唇运动特征。
我们通过交叉注意力和合并注意力交替连接来实现特征之间的相关性和互补性。通过交换注意力信息,挖掘嘴唇动作和声带振动之间特征的相关性,即 As=att((K⋅L,V⋅L),Qs) 和 Al=att((Ks,Vs),QL) ,同时,通过合并注意力 Al=att((Ks,Vs),QL )来实现特征的互补性。
为了实现语音识别并验证特征融合的有效性,我们在融合网络的输出连接一个识别模块。该识别模块采用了类似于编码器结构的多头注意力子层和前馈子层,并在每个子层之前,添加归一化层以确保特征的稳定性,并在每个子层之后使用了残差连接以保留原始特征信息。
3 结论
本文提出了一种基于毫米波雷达的语音识别新型解决方案,通过波束成形技术精确提取唇部运动和声带振动的多模态特征,在多声源和环境噪声情况下进行语音识别。为了从唇部运动中提取带有身体和头部运动动态干扰的信号特征,我们提出了一种基于卡尔曼滤波的方法来消除动态干扰。我们提出了一种基于交叉验证的语音检测方法,以区分说话活动和非说话活动,从而避免在非说话活动上浪费计算资源。相较于传统麦克风方案,本方法在信噪比低于5dB 的强噪声环境下仍能保持 82.4% 的识别精度,展现出显著的鲁棒性优势。
参考文献
[1]W.Li et al., "Global-Local-Feature-Fused Driver Speech Emotion Detection for Intelligent Cockpit in Au tomated Driving," IEEE Transactions on Intelligent Vehicles, vol.8, no.4, Apr.2023, pp.2684-2697.
[2]T.Hori et al., "Low-Latency Real-Time Meeting Recognition and Understanding Using Distant Micropho nes and Omni-Directional Camera," IEEE Transactions on Audio, Speech, and Language Processing, vol.20, no. 2 , Feb.2012, pp.499-513.
[3]H.M.Do, K.C.Welch, and W.Sheng, "SoHAM: A Sound-Based Human Activity Monitoring Framework f or Home Service Robots," IEEE Transactions on Automation Science and Engineering, vol.19, no.3, Jul.2022, pp.2369-2383.
[4]T.Suzuki, T.Tsunakawa, M.Nishida, M.Nishimura and J.Ogata, "Effects of Mounting Position on Throat Microphone Speech Recognition," 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 2019, pp.873-874.
[5]I.Yoo et al., "Development of Directional MEMS Microphone Single Module for High Directivity and SNR," in IEEE Sensors Journal, vol.22, no.7, 1 April1, 2022, pp.6329-6335.
[6]Jianwei Yu, Shi-xiong Zhang and Bo Wu"Audio-Visual Multi-Channel Integration and Recognition of O verlapped Speech," in IEEE Access, vol.5, 2021, pp.2067-2082.
[7]H.Li, C.Xu, A.S.Rathore, Z.Li, H.Zhang, C.Song, K.Wang, L.Su, F.Lin, K.Ren et al., “Vocalprint: explo ring a resilient and secure voice authentication via mmwave biometric interrogation,” in Proceedings of the 18t h Conference on Embedded Networked Sensor Systems, 2020, pp.312–325.
[8]Y.Liu, M.Gao, et al, "Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mm Wave and Audio Signals," Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems Zhejiang University, 2021.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)