.jpg)
梯度下降算法在深度学习中的数学原理与优化

葛亚萍
蚌埠经济技术职业学院 安徽蚌埠 233000
一、引言
深度学习作为人工智能领域的关键技术,在图像识别、自然语言处理、语音识别等众多任务中取得了巨大成功。深度学习模型通常包含大量参数,需要通过训练来优化这些参数,以最小化损失函数,从而提高模型的性能。梯度下降算法是深度学习中最常用的优化算法之一,它通过不断沿着目标函数的负梯度方向更新参数,逐步逼近最优解。因此,深入研究梯度下降算法在深度学习中的数学原理与优化方法,对于提高深度学习模型的训练效率和性能具有重要意义。
二、梯度下降算法的基本概念与数学原理
(一)梯度下降算法的基本概念
梯度下降算法是一种迭代优化算法,用于寻找函数的极小值。在深度学习中,目标函数通常是损失函数,它衡量了模型预测结果与真实标签之间的差异。梯度下降算法的核心思想是通过不断沿着目标函数的负梯度方向更新模型的参数,使得损失函数逐渐减小。
(二)目标函数的构建
在深度学习中,目标函数的构建取决于具体的任务。例如,在分类任务中,常用的目标函数是交叉熵损失函数;在回归任务中,常用的目标函数是均方误差损失函数。目标函数通常是一个关于模型参数的非线性函数,其形式较为复杂。
(三)梯度的计算
梯度是目标函数在各个参数方向上的偏导数组成的向量,它表示了目标函数在该点处的变化率。计算梯度是梯度下降算法的关键步骤。在深度学习中,由于模型参数众多,直接计算梯度往往比较困难。通常采用反向传播算法来高效地计算梯度。反向传播算法基于链式法则,从输出层开始,逐层向前计算每个参数的梯度。
(四)梯度下降算法的更新规则
梯度下降算法的参数更新规则为: 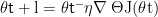 ,其中 θt是第 t 次迭代时的参数向量,η 是学习率,
,其中 θt是第 t 次迭代时的参数向量,η 是学习率, 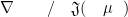 是目标函数 J(θ)在 θt处的梯度。学习率控制了参数更新的步长,学习率过大可能导致算法震荡或不收敛,学习率过小则会使算法收敛速度过慢。
是目标函数 J(θ)在 θt处的梯度。学习率控制了参数更新的步长,学习率过大可能导致算法震荡或不收敛,学习率过小则会使算法收敛速度过慢。
三、梯度下降算法在深度学习中面临的挑战
(一)局部最优解问题
深度学习中的目标函数通常是非凸函数,存在多个局部最优解。梯度下降算法在寻找最优解的过程中,可能会陷入局部最优解,而无法找到全局最优解。这会导致模型的性能无法达到最佳。
(二)梯度消失与爆炸问题
在深度神经网络中,随着网络层数的增加,梯度在反向传播过程中可能会出现消失或爆炸的现象。梯度消失是指梯度在反向传播过程中逐渐变小,导致浅层网络的参数无法得到有效更新;梯度爆炸是指梯度在反向传播过程中逐渐变大,导致参数更新过大,使模型无法收敛。
(三)学习率选择困难
学习率是梯度下降算法中的一个重要超参数,其选择对算法的性能有很大影响。学习率过大可能导致算法不收敛,学习率过小则会使算法收敛速度过慢。目前,学习率的选择通常需要依靠经验或通过实验进行调优,缺乏有效的理论指导。
(四)鞍点问题
除了局部最优解外,深度学习中的目标函数还存在大量的鞍点。鞍点是指在某些方向上梯度为零,但在其他方向上梯度不为零的点。梯度下降算法在鞍点附近可能会陷入停滞,导致收敛速度变慢。
四、梯度下降算法的优化策略
(一)动量法
动量法通过引入动量项来加速梯度下降算法的收敛。动量项记录了之前梯度的加权平均值,使得参数更新方向不仅取决于当前梯度,还取决于之前梯度的方向。动量法可以缓解梯度震荡问题,加快算法在平坦区域的收敛速度。其参数更新规则为:\vt=γvt-1+η∇θJ(θt),\θt+1=θt-vt, 其 中 \γ 是动量系数,\vt 是第\t 次迭代时的动量项。
(二)自适应学习率方法
自适应学习率方法根据参数的历史梯度信息自动调整学习率。例如,Adagrad 算法根据每个参数的历史梯度的平方和来调整学习率,使得频繁更新的参数学习率较小,不频繁更新的参数学习率较大。RMSprop 算法对 Adagrad 算法进行了改进,引入了衰减因子来平滑历史梯度的平方和。Adam 算法结合了动量法和 RMSprop 算法的优点,同时考虑了梯度的一阶矩估计和二阶矩估计,具有较好的收敛性能。
(三)批量归一化
批量归一化通过对每一批数据进行归一化处理,使得每一层网络的输入分布更加稳定。这可以缓解梯度消失和爆炸问题,加快模型的收敛速度。批量归一化还可以降低模型对初始参数的敏感性,提高模型的泛化能力。
(四)学习率衰减策略
学习率衰减策略是指在训练过程中逐渐减小学习率。常见的学习率衰减方法有指数衰减、余弦衰减等。学习率衰减可以使算法在训练初期使用较大的学习率快速接近最优解,在训练后期使用较小的学习率进行精细调整,从而提高算法的收敛精度。
五、实验分析与结论
(一)实验设计
为了验证不同优化策略的效果,设计了一系列实验。选择常见的深度学习模型,如多层感知机(MLP)、卷积神经网络(CNN)等,在不同的数据集上进行训练。对比不同优化策略(如 SGD、动量法、Adam 等)在训练过程中的损失函数变化、准确率变化等指标。
(二)实验结果分析
实验研究结果表明,各类优化策略在不同模型架构和数据集规模下呈现出显著的性能差异。随机梯度下降(SGD)算法在浅层网络结构和小规模数据集场景中展现出良好的优化效果,其实现简单且计算开销较小;然而当面对深层神经网络和大规模数据训练时,SGD 表现出明显的收敛速度下降问题。动量优化法通过引入历史梯度信息,有效改善了 SGD 在平坦区域的收敛效率,但对于高维参数空间中的鞍点问题仍存在优化停滞的局限性。相比之下,自适应矩估计(Adam)算法综合了动量法和自适应学习率的优势,在绝大多数实验场景中均表现出卓越的收敛特性,能够快速定位到较优的参数解空间。值得注意的是,批量归一化技术通过规范各层输入的分布特性,显著提升了模型训练的稳定性和效率;而动态学习率衰减策略则通过训练过程中的精细调节,进一步优化了模型的最终性能。这些发现为深度学习实践中的优化器选择提供了重要的实证依据。
结论
本文深入探讨了梯度下降算法在深度学习中的数学原理与优化方法。梯度下降算法是深度学习模型训练的核心算法,但在实际应用中面临着局部最优解、梯度消失与爆炸、学习率选择困难等挑战。通过引入动量法、自适应学习率方法、批量归一化和学习率衰减策略等优化方法,可以有效提高梯度下降算法的性能。在实际应用中,需要根据具体的模型和任务选择合适的优化策略,以获得最佳的模型性能。未来的研究可以进一步探索更高效的优化算法,以应对深度学习不断发展带来的挑战。
参考文献
[1] 施开波 , 汪硕婷 , 王文昊 . 高等数学中梯度下降类算法的研究及应用 [J]. 理科爱好者 , 2024, (06): 1- 4.
[2] 薛艳锋 , 刘继华 , 张翔 , 等 . 基于梯度下降的不可微损失函数优化算法 [J]. 软件工程 , 2023, 26 (06): 46- 49.
作者简介:葛亚萍, 女,1984.10, 安徽, 汉, 本科, 讲师, 研究方向:数学应用与教学研究
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)