.jpg)
一种基于深度学习的社交媒体情感数据分析方法研究

王永昌 呼洪强 刘旭宁
石家庄学院 河北省石家庄市 050035
一、引言
社交媒体已转变成大众表达情感、沟通各类观点的主要平台,依照 Statista 公布的数据可知,2024 年,全球社交媒体的用户群体规模为49 亿,日均所生成的内容超过 50 亿条,当中蕴藏的诸如喜怒哀乐的情感资讯,对舆情预警(像突发事件后公众情绪的疏导)、企业决策(诸如产品口碑的监测)具备关键价值。传统的情感分析途径主要借助人工特征组构,可社交媒体文本存在零散、口语化、多载体(文字与表情包/ 图片结合)等特质,造成其局限性全面凸显,深度学习技术借多层神经网络自行学习数据特征,不依靠人工干涉,在情感分析范畴展示突出优势性。本文着重针对社交媒体多模态情感数据展开,创立一种 BERT与 CNN 融合起来的分析途径,目的在于提升复杂情形下情感识别的准确水平,为相关应用提供技术后盾。
二、相关技术与研究现状
基于情感词典的方式,借助匹配预先设定的正 / 负向词汇(像“开心”“失望”这类)来算出情感得分,标志性工具诸如 TextBlob、SnowNLP,该途径简单易落实,但在处理网络新词、对语境依赖严重的表达(如“这电影太‘精彩’了”的反讽情况)时识别能力差。以传统机器学习为基础采用 SVM、逻辑回归等算法,采用 TF - IDF、词袋模型达成特征提取,借助 SVM 对微博文本做正 / 负二分类,准确率大概处于 75%-80% 的波动范围,然而依赖人工进行特征设计的安排,泛化的通用性欠佳。基于深度学习构建的循环神经网络(RNN/LSTM),擅长应对序列数据处理,可把握文本的上下文关联,做情感分析时,准确率会在 82%-85% 之间波动;Transformer 模型(如 BERT 这样的)运用自注意力机制并行处理文本内容,可同时去留意句中不同词语间存在的关联,比如“虽然下雨,但很开心”里面,“但”字实现情感反转单文本情感分析准确率增加到 85%-88% 区间;多模态模型把文本和图像这两种特征融合,像借助 CNN 提取表情包的视觉特性,把文本特征拼接后做分类,进一步优化复杂场景里的准确率水平[1]。
三、基于深度学习的社交媒体情感分析方法设计
(一)方法框架
本文推出的多模态情感分析方法有数据预处理、特征提取、特征融合、情感分类四个模块,输入为社交媒体文本跟表情包,经预处理流程结束后,借助 BERT 模型提取文本特征,采用 CNN 进行表情包特征提取,二者依靠注意力机制实现融合之后,经全连接层处理后输出情感类别[2]。具体流程如下:S101 获取多模态情感分析训练样本的文本与图像数据;S102 图像数据经空间变换网络(STN)处理并提取特征,得到图像特征向量;S103 文本数据单词转文本向量,用双向长短时记忆网络(Bi - LSTM)建模,获单词隐藏状态向量;S104 拼接、加权单词隐藏状态向量,得最终文本特征向量;S105 连接文本与图像特征向量,获文本、图像表示向量;S106 第 k 次迭代时,以前一次文本、图像表示向量等为注意力层输入,得新图像、文本特征表示向量;S107 融合图像与文本特征表示向量,进行情感分类及图文情感倾向性相关性分析,属于人工智能、情感计算领域的技术流程。

(二)关键步骤实现
1. 数据预处理
就社交媒体文本的特点而言,清除URL、 @ 用户名以及类似“【】”的特殊符号;把“yyds”映射成“永远的神”,把“蓝瘦香菇”替换成“难受想哭”;采用BERT 分词器让文本成为词向量,把长度统一至128 维,获取 10 万以上常用表情包,根据情感属性(正面情感 / 负面情感 / 中性情感)做标注,把它变为 64×64 像素的 RGB 图像规格,作为 CNN 模型输入项。
2. 文本特征提取
借助预训练好的 BERT - base 模型,把处理好的文本序列输入,采用最后一层 [CLS] 向量(句向量)作为文本情感的表征,维度达到了768 维,该向量体现文本整体的情感趋向性,就像“今天收到礼物,太开心了!”这句话的向量,在正面情感空间得分颇高。
3. 表情包特征提取
设计轻量级 CNN 模型:囊括 3 个卷积层(卷积核大小依次是3×3 、3×3、5×5)、 2×2 的池化层,以及 BatchNorm 层,给出具有256 维的表情包情感特征向量,模型借助学习表情包色彩,像红色往往代表正面,灰色多寓意负面)、神情状态(像明朗笑脸、黯然哭脸)等可见特质,实现情感倾向的量化分析[3]。
4. 特征融合与分类
引入并启用“跨模态注意力机制”,考量文本特征跟表情包特征的相似水平,实时赋予权重,若文本和表情包情感相符时,二者权重呈对等状态;要是文本与表情包情感相悖,把表情包权重提升至 0.6,文本权重削减至 0.4,优先采信视觉情感的表达,把 768 维与 256 维融合成的1024 维特征向量导入全连接层,借助Softmax 函数给出正面(1)、负面(0)、中性(2)三种情感的概率数值。
(三)模型训练与优化
采用自我搭建的社交媒体情感数据板块,有微博、抖音评论合计10 万条,文本与表情包结合的数据占比达 65% ,情感类别由 3 名标注员对每条数据进行手动标注,Kappa 系数为 0.89,显示出其一致性较高,采用 Adam 作为优化器,学习率采用 2e - 5 这一数值,采用 32 作为 batch 的规模,执行10 个训练周期,采取早停举措,一旦验证集准确率连续三轮不再提升就停止训练,防范模型陷入过拟合,评估采用的指标包含准确率(Accuracy)、精确率(Precision),以及召回率(Recall)、F1 分数。
四、实验结果与分析
(一)对比实验设计
为验证本文方法的有效性,设置 4 组对比模型:情感词典法:基于 SnowNLP 工具;传统机器学习法:SVM+TF-IDF 特征;单一文本深度学习法:BERT 模型(仅文本特征);简单多模态法:BERT 文本特征 +CNN 表情包特征直接拼接(无注意力机制)。
(二)实验结果分析
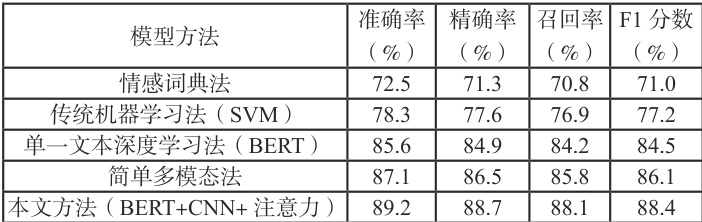
各模型在测试集(2 万条数据)上的表现如下表所示。
(三)结果分析
本文方法准确率达 89.2% ,较单一文本 BERT 模型提升 3.6 个百分点,较简单多模态法提升 2.1 个百分点,说明跨模态注意力机制能有效融合文本与表情包情感信息。在含反讽、表情包与文本矛盾的样本中,本文方法优势更显著。
五、结论
本文提出的基于深度学习的社交媒体情感分析方法,通过融合BERT 文本特征与 CNN 表情包特征,并引入跨模态注意力机制,有效提升了复杂场景下的情感识别准确率。实验表明,该方法能处理网络俚语、多模态表达等难点问题,为舆情监测、品牌管理等领域提供技术支持。
参考文献
[1] 曹蓓 , 赵奎 . 基于双重情感和多特征融合的虚假新闻检 测 [J]. 计 算 机 工 程 ,2025,51(06):193-203.DOI:10.19678/j.issn.1000-3428.0070158.
[2] 冯立杰 , 秦浩 , 王金凤 , 等 . 融合专利数据与社交媒体数据的潜在颠覆性技术识别—— 基于深度学习模型 [J]. 情报学报 ,2024,43(02):181-197.
[3] 杨腾飞 , 解吉波 , 闫东川 , 等 . 基于深度学习的社交媒体情感信息抽取及其在灾情分析中的应用研究 [J]. 地理与地理信息科学 ,2020,36(02):62-68.
博士科研启动基金项目
课题名称:面向情感分析的文本分类方法研究
课题编号:23BS019
作者简介:王永昌(1978.5-)男,汉族,江苏省无锡市,博士研究生,讲师,研究方向:舆情分析,大数据分析,机器学习。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)