.jpg)
基于LLaVa的图像车辆识别方法

陈畅 刘冰 陈晓慧 刘心燕 张会欣
1.信息工程大学,河南郑州,450001 2.河南省科学院空天信息研究所,河南郑州,450046 3.河南中天高新智能科技股份有限公司,河南郑州,450046
摘要:近年来,预训练多模态大模型强大的语义理解和跨模态泛化能力为图像中的车辆识别提供了新的技术路径。本文提出了一种基于多模态大模型的图像车辆识别方法,首先测试了LLaVA模型的车辆基础识别能力,然后基于LoRa方法对模型进行微调,显著提高了模型对车辆图像的分类精度和泛化能力。实验结果表明,模型参数规模越大,对车辆类型识别效果越好,尤其在民用车辆识别上表现优异。
关键词:多模态大模型,预训练,低成本微调,车辆识别
Abstract: In recent years, the powerful semantic understanding and cross modal generalization ability of pre trained multimodal large models have provided a new technological path for vehicle recognition in images. This work proposes an image vehicle recognition method based on a multimodal large model. Firstly, the vehicle basic recognition ability of the LLaVA model was tested, and then the model was fine tuned based on the LoRa method, significantly improving the classification accuracy and generalization ability of the model for vehicle images. The experimental results show that the larger the size of the model parameters, the better the performance of vehicle type recognition, especially in civilian vehicle recognition.
Keywords: multimodal large model, pre training, low-cost fine-tuning, vehicle recognition
1.引言
图像中的车辆识别技术在军用和民用领域有着广泛的应用。车辆识别方法是通过捕捉车辆的特征,根据不同车辆特征的不同从而判断车辆的类别,计算机视觉和图像处理技术的不断发展,车辆识别技术从最初的人工检查和记录,逐步发展到自动化和智能化的阶段。目前车辆识别技术的发展主要经历了基于传统计算机视觉的车辆识别分类方法和基于深度学习的车辆识别分类方法两个阶段[1-2]。基于传统计算机视觉的车辆识别分类方法是车辆识别领域的重要组成部分,通常依赖于手工设计的特征和传统的机器学习算法,分类的准确性依靠于人工获取特征描述符,需要消耗大量的人工工作。基于深度学习的车辆识别分类方法原理是利用深度神经网络自动学习图像的特征,可以显著提高车辆识别的精度,通常以卷积神经网络为核心,首先通过目标检测算法定位车辆的检测区域,然后通过分类网络进行车型的识别,该方法的优点是分类准确率较高,但依赖大规模的标注图像数据,工作量较大,且训练模型时计算资源需求高。
在人工智能快速发展的今天,大语言模型和多模态大语言模型已成为推动技术进步的核心力量。大语言模型(Large Language Model, LLM)作为生成式人工智能的核心技术范式,通过构建超大规模参数化神经网络,基于自监督学习范式对海量无标注文本进行预训练,实现了对人类语言深层次语义规律的建模与泛化能力的突破性提升,广泛应用于各个领域。随着模型参数规模突破百亿级临界点,LLM逐渐涌现出零样本学习、思维链推理、多模态融合等超越传统模型的智能特征。
多模态感知大模型能够平等且独立地从视觉、听觉、文本等不同模态数据提取各自模态信息,进行对齐和融合。跨模态认知大模型指的是各种模态信息被内生性地同时处理,不同模态信息在统一编码框架中自由交叉混合。目前,多模态感知大模型主要通过预训练模型进行实现,在图文方面表现非常突出,图文大模型指的是将图像和文本同时输入并生成结果。2021年OpenAI提出的CLIP模型作为视觉-语言预训练任务中的代表作为众人提供了指导性的思路,其利用一个图像编码器和一个文本编码器分别从图像和文本中提取特征,接着通过对比学习,实现特征空间的对齐,将两种独立地模态进行融合,这是经典的双编码器架构[3]。BLIP(引导式语言-图像预训练)旨在实现文本理解和生成任务的统一,为多模态任务的研究提供了新的思路和方法[4]。MiniGPT-4使用简单的线性层将预训练的视觉编码器和大型语言模型Vicuna连接起来,实现图像和文本的理解。因为在训练过程中只需要训练线性层参数,MiniGPT-4具有高训练效率的特点[5]。LLaVA使用简单的投影矩阵将预训练的CLIP ViT-L视觉编码器和大型语言模型Vicuna连接起来[6]。MiniGPT-4利用GPT-4强大的文本理解和生成能力,通过用详细的文本描述替换图像来生成高质量的多模态指令遵循数据集。
在当前研究背景下,传统车辆识别分类技术通常依赖大规模预训练数据集来优化模型性能,然而这种方法对数据量的需求较高,且在面对新类别或未见样本时往往表现出泛化能力不足。相比之下,基于多模态大模型驱动的车辆识别技术突破了传统方法的局限性。多模态大模型凭借其强大的语义理解和跨模态泛化能力,能够直接利用预训练模型的通用知识,无需额外的预训练过程,即可实现对车辆类别的零样本分类,显著降低了对大规模标注数据的依赖。但在特定领域或任务中,模型性能仍可能受到领域差异或数据分布偏差的影响。因此,本文旨在探索多模态大模型在车辆识别分类中的应用潜力,并通过利用相关数据集进行少量样本微调,进一步优化模型性能,验证其在实际场景中的可行性和有效性。
2.所提出方法
本文使用开源的LLaVa模型来实现视频车辆的零样本识别,然后基于少量训练数据对LLaVa模型进行微调,进一步增强其对于细粒度车辆类别的识别能力。
2.1 LLaVA大模型
LLaVA[7],作为一个大型语言和视觉助手,通过其projection模块将视觉编码器与大型语言模型相连接。该视觉编码器基于CLIP的ViT-L/14模型,并利用transformer层前后的特征。Prejection作为一个简单的线性层完成从视觉编码到语言模型输入token的映射。大语言模型采用Vicuna作为语言解码器,用于接收token化的视觉编码以及语言指令的token,输出语言回应。整体模型架构如下图所示。
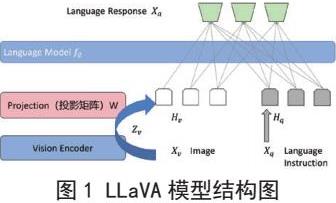
使用LLaVA模型进行图像处理的具体实现过程如下。输入图像,使用预训练好的CLIP视觉编码器ViT-L/14提取图像视觉特征表示为,在实验中引入了一个简单的线性层将最后一个transformer层前后的特征与语言模型中的词嵌入空间,这个线性层使用一个可训练的投影矩阵,将视觉特征转换为语言嵌入标记,确保了与语言模型中的词嵌入具有相同的维度:
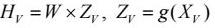
模型的训练过程共分为两个阶段:
在第一阶段,LLaVA模型从数据集中选取了图像-文本对,并采用了一种简单的扩展方法将这些对转换成符合指令格式的数据。这一转换过程涉及将随机抽样的问题作为图像的指令,并将原始标题作为预期的答案。在这个阶段,LLaVA模型固定了视觉编码器和LLM的权重,只调整投影矩阵以最大化生成预期答案的可能性。
在第二阶段,LLaVA模型固定了视觉编码器的权重,并更新了模型的投影层和LLM的权重。LLaVA模型的可训练参数包括投影矩阵W和LLM的参数φ。LLaVA模型使用了收集到的语言图像指令跟踪数据来训练聊天机器人,同时均匀地采样多轮和单轮回答。此外,LLaVA模型在ScienceQA基准测试中评估了模型的性能,其中问题以自然语言或图像的形式提供上下文,助手负责推理过程并从多个选项中选择一个答案。
2.2基于LLaVA模型的车辆识别分类技术
本文方法采用LLaVA多模态大语言模型驱动的零样本图像分类方法,核心原理在于通过视觉-语言模态对齐,将输入的车辆图像数据与结构化文本指令进行联合编码,利用模型的跨模态推理能力实现类别判别。首先遍历指定目录中获取子文件夹名称即分类标签,建立基于目录层级的标签空间,其中各子目录名构成封闭类别集合。然后通过动态构建约束性提示词模版如下“which category is this image most likely to belong to in []. Output format: <Category>”有效抑制模型幻觉(Hallucination)现象,确保输出严格遵循预定分类体系。将编码后的图像和提示词同时输入到LLaVA多模态大模型进行跨模态注意力计算,获得模型响应的回答。
在回答中提取车辆分类结果,与子文件夹名称对比,预测分类结果与实际分类结果相同则视为分类正确,进而计算模型图像分类正确率。
2.3 LoRa低成本微调
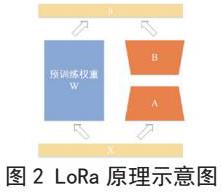
预训练LLaVa模型对于细粒度车辆识别能力可以通过对模型进行微调来提升。本文采用LoRa低成本微调方法对LLaVa进行微调。如图2所示,LoRa(Low-Rank Adaptation)基于大模型的内在低秩特性,通过增加旁路降维矩阵和升维矩阵来模拟全参数微调,是当前最有效的大模型微调方法之一。具体训练时,冻结大语言模型的预训练参数,只更新降维矩阵 A和升维矩阵B的参数。模型完成训练后,将预训练参数W和矩阵参数A和B进行叠加。矩阵参数A和B的参数量远远小于预训练参数W。因此,LoRa能够有效减少训练参数的数量,从而降低大模型训练对于硬件的需求。所以,本项目拟采用LoRa方法来训练多模态大模型实现遥感影像和文本(开放词汇)的语义对齐。
3.实验结果与分析
3.1实验数据
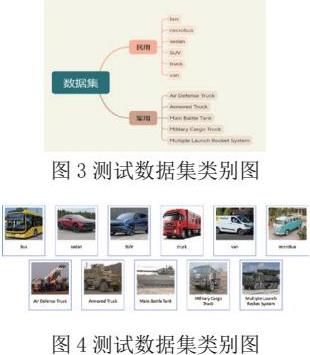
为了验证所提出方法的有效性,本文构建了包含3300张图像的实验数据集。根据车辆用途划分为民用和军用两大类,具体分类结构如图3所示。其中民用类别包含六种子类别,军用类别包含五种子类别,每种子类别包含300张示例图像,每个车辆类别的示例如图4所示。
3.2 预训练模型车辆识别实验
为了评估模型在不同参数规模下的分类性能,本实验设计了两种提示词(prompt),分别用于引导模型对军用和民用两类数据进行分类任务。实验中,三种参数规模的模型均在相同条件下运行,以确保结果的可比性。最终的分类正确率验证结果如图5 和图6 所示,分别展示了两种提示词下的模型性能对比。提示词一为“which category is this image most likely to belong to in ?”,提示词二为“which category is the vehicle in the picture most likely to belong to in ?”
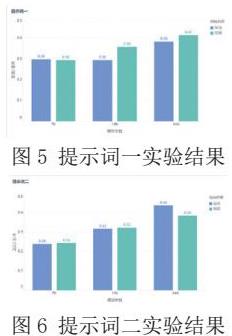
根据实验结果分析,不同的提示词对分类正确率的影响较小,模型参数越大,分类正确率越高,车辆类型识别效果越好,这表明较大的参数规模能够提升模型的泛化能力。
在提示词一的引导下,34B模型在民用类别上的正确率达到了 0.42,显著高于7B和13B模型。在提示词二的引导下,34B模型在军用类别上的正确率达到了0.44,进一步验证了参数规模的增加对模型性能的提高。但是从实验结果总体来看,LLaVA-v1.6三种参数的模型因为模型参数较小,泛化能力弱,对于车辆识别分类正确率均低于0.50,因此,进一步研究工作是使用MS-swift工具对模型进行微调,提高模型对车辆识别分类的效果。
3.3 微调模型车辆识别实验
在本实验中,使用MS-swift工具对ModelScope社区支持的多模态大模型LLaVA-v1.6-7B模型进行LoRA微调,微调实验思路为:通过命令行使用指定训练集对模型进行LoRA微调,得到n个检查点及模型参数相关文件,然后合并Lora生成本地模型文件,在命令行使用python命令将模型部署到服务端,通过用户端调用的方式进行模型正确率验证。通过改变训练集和训练参数,在训练样本数相同的情况下,将LLaVA-v1.6-7B模型对民用车辆的分类正确率由0.30调整到了0.71,对军用车辆的分类正确率由0.30调整到了0.45,实验表明,模型对于民用车辆的分类泛化效果明显比军用车辆要好。
4.结论
本文探索了多模态大模型在车辆识别分类中的应用潜力,并通过利用相关数据集进行少量样本微调,进一步优化模型性能,通过在包含11个细粒度类别的3300张图像上的识别实验验证了所设计方法的有效性。
参考文献
[1] 尚亚博,贾得顺.基于混合注意力机制的细粒度车辆分类识别研究[J].汽车实用技术,2025,50(07):35-40.
[2] 李昌赫.基于改进YOLO的车辆与行人识别算法分析[J].电子技术,2025,54(01):80-82.
[3] 陈露,张思拓,俞凯.跨模态语言大模型:进展及展望[J].中国科学基金,2023,37(05):776-785.
[4] Zhang Y, Li Y, Li H, et al. Bootstrapping Language-Image Pre-training with Contrastive Learning[J]. arXiv preprint arXiv:2304.12210, 2023.
[5] Wang J, Li H, Li Y, et al. MiniGPT-4: Enhancing Vision-Language Models with Linear Layers[J]. arXiv preprint arXiv:2305.12121, 2023.
[6] Wu Y, Li H, Li Y, et al. LLaVA: A Lightweight Vision-Language Assistant[J]. arXiv preprint arXiv:2306.00877, 2023.
[7] Liu, Haotian, et al. "Visual instruction tuning." NeurIPS, 2023.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)