.jpg)
中俄东线离散式焊接工况数据汇总方法的研究

袁吉庆
辽河油田建设有限公司 辽宁省盘锦市兴 124010
一、目标及现状分析
1、预期目标
为实现数据提取并补录的目标,首先需要分析下工况采集数据库内有哪些字段,即需要采集哪些工况数据项目。首先使用数据库软件远程连接后台数据库,打开相应的采集表子目.
2、现状分析
为保证补录数据的完整性,需要将所有数据从焊接采集模块中的导出,因施工现场各焊接工序的数据采集模块分别安装在不同的焊接棚内,数据分布高度离散化,这就需要使用移动式存储设备(U 盘或硬盘)将每个焊接棚内的数据拷贝到 PC 端上然后进行后续处理。
通过观察可得知,第一层级文件夹是以焊层代号命名的,而进入每个第一层级文件夹内部,都会出现以焊接日期命名的第二层级文件夹,再次进入每个第二层级文件夹,则会出现以焊枪编号命名的第三层级文件夹,而点击每个第三层级文件夹,都会进入存在若干个焊接工况数据的 txt 文本文件。简单推算一下 txt 文件的数量:
第一层级文件夹数量:11 个;
第二层级文件夹数量:若以每 15 天导出一次为例,则为 15 个;
第三层级文件夹数量:2 个;
第四层级中文件数量:从 1 到数十个不等,假定为 20 个;
假定拷贝的数据各文件夹中 txt 文件不缺失,则可计算:
txt 文件总数量 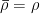 第一层级文件夹数量 × 第二层级文件夹数量 × 第三层级文件夹数量 ×
第一层级文件夹数量 × 第二层级文件夹数量 × 第三层级文件夹数量 ×
第四层级中文件数量=11×15×2×20
=6600
通过计算可得出,若以每15 天导出一次为例,导出的txt 文件约为6600个。鉴于 txt 文件数量级巨大,手动进行文件夹中的 txt 文件“脱离文件夹”处理是不可行的。即需要采取批量化处理。
再次,通过观察每个工况数据文档,可发现每个文档的内容格式都是规范化的数据,且采集项目均包含在数据库中的字段范围之内。因此可通过字符串相关的函数进行处理,即可得到想要的数据字段。
三、实施步骤
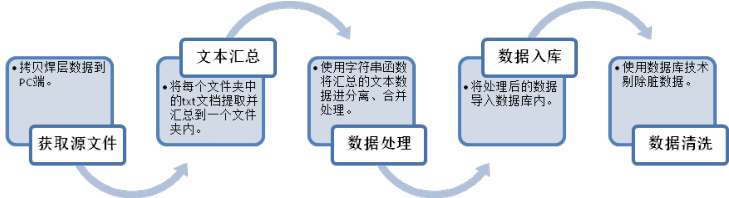
1、获取源文件
采用移动式存储设备(U 盘或硬盘)将每个焊接棚内的数据拷贝到 PC端上。
2、文本汇总
采用批量化脚本对获取到的源文件进行从多层级、多文件夹中提取,并集中汇总到一个新的文件夹内。并为了保证在转移 txt 文本过程中,同名但内容不同的文件不发生覆盖替换而导致数据缺失的情况,在批处理过程中将文件路径添加到文件名称中。
3、数据处理
(1)在 txt 文本使用脚本复制到新建文件夹后,新建 Access 数据库,创建相应的表对象,然后使用代码遍历读取 txt 文本中的每一行数据,并导入到表对象内。
(2)创建查询,将表对象中的每条数据根据分隔符,进行字符串拆分,再组合等操作.
4、数据入库
将分离、组合之后的数据进行汇总到新的表对象内,以供下一步操作。
5、数据清洗
因施工过程中存在设备调试的情况,焊工不进行焊口、入场证、焊层二维码信息的扫码操作,因此在工况数据汇总之后,考虑将数据库内的焊层、焊口编号、焊工编号字段存在空值的记录剔除掉。
四、效果验证
通过多次测试,导入数据的速度基本在 1000 条/秒以上,较之手工查找汇总分析的效率大大提高,实现了预期的目标。在数据汇总之后,即可通过操作界面的焊口查找功能将缺失工况信息的焊口进行筛选导出,为线下向 PIM 平台补录提供数据依据。
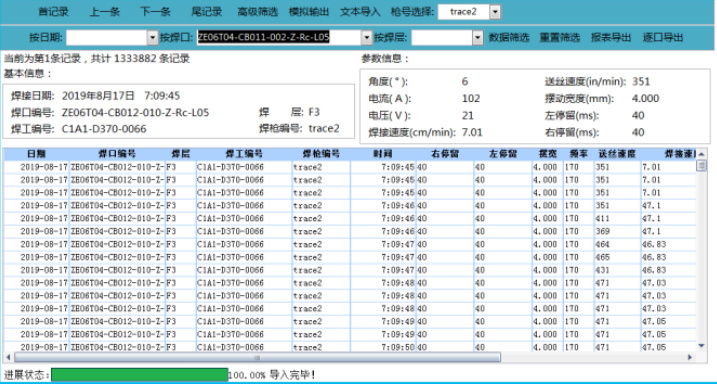
图 2 焊口筛选导出界面
五、结语
本次研究主要是将离散式的焊接工况数据汇总整理的过程,但其应用不仅限于补录数据,更是可以为焊接工况的大数据分析提供数据来源,即大数据分析中的“数据收集”的环节。数据是大数据分析的基础和灵魂,数据的质量和数量直接决定了后续数据分析结果的正确与否,能否为管理人员提供有价值的决策参考依据,因此做好数据收集工作十分有必要且有重大的现实意义。
.jpg)
.jpg)
.jpg)
.jpg)