.jpg)
人工智能翻译中的决策树与贝叶斯方法研究

王宝妮 王锦 蔡沅沅
西安翻译学院信息工程学院,陕西省西安市710105;西安讯飞超脑信息科技有限公司,陕西省西安市710076
1 机器学习的概念
机器学习的概念是建立在人类学习概念上的。所谓机器学习就是用计算机系统模拟人类学习的一门学科,这种学习目前主要是一种以归纳思维为核心的行为,它将外界众多事实的个体,通过归纳思维方法将其归结成具一般性效果的知识[1]。
机器学习的结构模型分为计算机系统内部与计算机系统外部两个部分。其中,计算机系统内部是学习系统,它在计算机系统的支持下工作。计算机系统外部是学习系统外部世界。整个学习过程即是由学习系统与外部世界交互而完成学习功能。
机器学习中的学习系统主要完成学习的核心功能,它是一个计算机应用系统,这个系统由三个部分内容组成:①样本数据:在学习系统中,计算机的学习都是通过数据学习的,这种数据一般称为样本数据,它具有统的数据结构,并要求数据量大、数据正确性好。样本数据 般都是通过感知器从外部环境中获得。②机器建模:在学习系统中,学习过程用算法表示,并用代码形式组成程序模块,通过模块执行用以建立学习模型。在执行中需要输入大量的样本进行统计性计算。机器建模是学习系统中的主要内容。③学习模型:以样本数据为输入,用机器建模作运行,最终可得到学习的结果,它是学习所得到的知识模型,称为学习模型。
2 决策树与贝叶斯方法
2.1 决策树
决策树是一种归纳性方法,这种方法的输入是一组带标号样本数据,根据样本数据通过算法流程可以构造一棵树。树中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,而树中叶结点表示带标号的结果,而树的最顶层结点是根结点,这种树称为决策树。确定决策树后即可对树作优化,即是树剪枝。最后根据所得到的优化后的树获得归纳规则[2]。
该算法规则形成的过程由三部分组成,它们是:①决策树基本算法。②树剪枝。 ③ 由决策树提取规则。
决策树主要用于分类学习中。
(一)决策树算法(1)算法介绍
决策树的基本算法是一种贪心算法,它以自顶向下递归的方式构造决策树。算法在执行前必须满足下面几个关键性要求:①算法的输入是带标号训练样本。 它由若干个属性组成。 ②所有属性值必须是离散的,即必须是有限个数的。 ③ 该算法的结果是 棵决策树 作为结点构成的一棵外向树,其中非叶结点由决策对象属性构成,叶结点由标号属性构成。 开始按层构 ,每次选取一个属性作为当前测试结点,结点选择通过信息论中的信息增益的熵值作 度 关度量 的 算 将在度量计算方法中说明),选择其最大的属性作为当前的结点。
算法:Generate-decision-tree由给定的训练数据产生一棵决策树。
输入:训练样本samples,由离散值属性表示;候选属性的集合attribute-list。
输出:一棵决策树。
流程:
步骤1:创建结点 N 。步骤2:if samples都在同一个类 C then。步骤3:返回 N 作为叶结点,以类 C 标记。步骤4:if attribut-list为空then。步骤5:返回 N 作为叶结点,标记为samples中最普通的类//多数表决。步骤6:选择attribute-list中具有最高信息增益的属性test-attribute。步骤7:标记结点 N 为test-attribute。步 骤 8 : for each test-attribute 中 的 已 知 值 ai // 划 分 samples 。 步 骤 9 : 由 结 点 N 长出一个条件为test-attrbute= ai 的分支。步骤10:设 si 是samples中test-attrbute= ai 的样本的集合//一个划分。步骤11:ifsi ,为空then。步骤12:加上一个树叶,标记为samples中最普通的类。步骤13:else 加下一个由Generate-decision-tree( si ,attribute-list-test-attribute)返回的结点。
算法的基本流程如下:
(1)树从训练样本中的一个结点属性开始(步骤1)。(2)如果样本都属同一个类,则该结点成为树叶,并用该类标记(步骤2和步骤3)。(3)否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。(4)对测试属性的每个已知的值,创建一个分支,并据此划分样本(步骤8~步骤10)。(5)算法使用同样的过程递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必考虑该结点的任何后代(步骤13)。(6)递归划分步骤仅当下列条件之一成立时停止:①给定结点的所有样本属于同一类(步骤2和步骤3)。②没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下使用多数表决(步骤5)。这涉及将给定的结点转换成树叶,并用samples中的多数所在的类标记它。换一种方式,可以存放结点样本的类分布。 ③ 分支test-attribute= ai 没有样本(步骤11)。在这种情况下,以samples中的多类创建一个树叶(步骤12)。
(二)树剪枝
在创建树过程中,训练样本起关键作用,而训练样本集中的数据往往存在着个别的噪声与孤立点,它将对决策树的建立起着错误指导作用,这种决策树过分拟合训练样本集的现象称为过度拟合,为解决此问题必须即时剪去那些异常的分支称为决策树剪枝。常用的决策树剪枝有两种方法:
(1)预剪枝方法
预剪枝方法是限制决策树的过度生长。一种最为简单的手段是事先限制树的最大生长高度,另一种手段是通过一些统计检验方式,以评估每次结点分裂对系统性能的增益,如增益值小于预先给定阈值,则停止分裂而把当前结点作为叶结点。
(2)后剪枝方法
后剪枝方法是允许决策树过度生长并在决策树生成完成后再按一定规则作剪枝,其规则是:①对树中结点用一些方法评估其预测误差率,并将误差率高的结点作剪枝,剪去其子树并将该结点变成一个叶结点。②对树的剪枝可有两种方式:一种是自底向上;另一种是由顶向下。自底向上方法即是从树的底层非叶结点开始剪枝,而由顶向下则是从根结点以下开始剪枝。
(三)由决策树提取规则
可以由决策树得到分类的归纳规则,对从根到树叶的每条路径创建一个规则,并以If-Then形式表示。沿着给定路径上的每个属性值对形成规则前件(“If”部分)的一个合取项。叶结点包含类预测形成规则后件(“Then”部分)。
2.2 贝叶斯方法(一)概述
贝叶斯方法是一种统计方法,它属概率论范畴,它用概率方法研究客体的概率分布规律。贝叶斯方法中的一个关键定理是贝叶斯定理,利用贝叶斯方法与贝叶斯定理可以构造贝叶斯分类规律。目前贝叶斯分类有两种:一种是朴素贝叶斯分类或称朴素贝叶斯网络;另一种是贝叶斯网络或称为贝叶斯信念网络[3]。
贝 叶 斯 分 类 也 是 以 训 练 样 本 为 基 础 的 , 它 将 训 练 样 本 分 解 成 n 维 特 征 向 量X={x1,x2,…,xn} ,其中特征向量的每个分量 xi{i=1,2,…n} 分别描述X 的相应属性 Ai i 1, 2,, },混的度量。在训练样本集中,每个样本唯一的归属于m 个决策类 C1,C2,… , Cm 中的一个。如果特征向量中的每个属性值对给定类的影响独立于其他属性的值,亦即是说,特征向量各属性值之间不存在依赖关系(称此为类条件独立假定),此种贝叶斯分类称为朴素贝叶斯分类,否则称为贝叶斯网络。朴素贝叶斯分类简化了计算,使得分类变得较为简单,利用此种分类可以达到精确分类目的。而在贝叶斯网络中,由于属性间存在依赖关系,因此可以构造一个属性间依赖的网络以及一组属性间概率分布参数。
贝叶斯方法具有如下优势:①可以综合先验信息与后验信息; ② 适合合理带噪声与干扰的数据集; ③ 其结果易于被理解,并可解释为因果关系; ④ 对于满足类条件独立假定时所用的朴素贝叶斯分类更具有概率意义下的精确性; ⑤ 贝叶斯方法一般也用于分类学习中。
(二)贝叶斯理论与贝叶斯定理
下面介绍贝叶斯方法的基本理论及贝叶斯定理,贝叶斯理论是一种基于统计的概率理论,分几部分介绍。(1)概率
在贝叶斯理论中有两种概率:
第一,在一组客体中事件 X 出现的概率可记为 P(X),在贝叶斯理论中也可说P(X)是 X 的先验概率。设客体数为u,X 出现次数为v,此时则有 P(X)=ν/u 。
第二,在一组客体中,条件 Y 下事件 X 出现的概率可记为 P(X∣Y) ,在贝叶斯理论中也可说 P(X∣Y) 是条件 YFX 的后验概率,设客体数为 u,而满足 Y 的客体数为 u ,X 出现次数为 u ,此时则有 P(X∣Y)=ν/u' 。
(2)贝叶斯定理
贝叶斯方法中的最主要的定理是贝叶斯定理,贝叶斯定理如式:
P(H∣X)=P(X∣H)⋅P(H)/P(X)
该定理中先验概率 P(X)P(H) 是易于计算的,因此该定理实际上是建立了两个后验概率的关系, 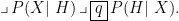 。
。
贝叶斯定理是构成贝叶斯分类归纳规律的
(三)朴素贝叶斯分类归纳方法
朴素贝叶斯分类方法是整个贝叶斯分类方法的基础,它建立在贝叶斯定理之上,其分类过程如下:(1)分类前提
有一个数据样本集,每个样本是一个 n 维向量 X=(x1,x2,…,xn) ,它表示样本n 个 属 性 A1,A2,…,An 的 度 量 , 并 假 设 均 为 离 散 值 。 有 m 个 类 :C1,C2,…,Cm ;每个样本唯一的归属于一个类。
(2)分类原理
应用贝叶斯定理,用先验概率 P(X),P(H) 及后验概率 P(X∣H) 计算出后验概sP(H|X) ,亦即是说在 P(X)XP(H) 为易于计算下,可由已知的分类规则
在分类中,由于 X=(x1,x2,…,xn),H=(C1,C2,…,Cm), 因此得到式:
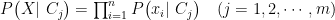
在分类方法中,已知有一个数据 Δx 需要求得它的类别,即求 H ,此要求可用概率方式写为:
P(HmidX),##H=(C1,C2,…Cm) ,因此可写为:P(Cj|X)(j=1,2,…,m) 按贝叶斯定理,可写成如式所示: 注意,
注意,  是固定值,因此可忽视之。
是固定值,因此可忽视之。 此应用贝叶
此应用贝叶
斯定理可以由训练样本集经计算预测 X 的类别。
(3)分类计算
分类计算是已知一个 X 值(即希望分类的未知样本)需求得H 的概率值,其计算过程为:(a)计算:
(c)计算:

从而得到最终的结果,并以概率形式给出。
3 总结
本文深入分析了人工智能翻译领域 决策树通过贪心算法自顶向下构造,利用信息增益的熵值度量选择最优 最终提取分类规则。贝叶斯方法则基于概率论,通过贝叶斯 网络,前者简化计算,适用于属性间独立场景;后者考虑属 有效处理噪声与干扰数据,结果易于理解,具有概率意义 的应用,不仅提高了翻译的准确性与效率,还为机器学习在自然 具有重要的理论与实践价值。
致谢
本文研究工作受到人工智能翻译陕西省高校工程研究中心资助。
参考文献
[1]孙雨晴.机器学习算法在数据挖掘中的应用[J].中国科技信息,2025,(10):50-52.
[2]徐赟.基于知网和贝叶斯模型的词义消岐技术的研究[D].南京理工大学,2010.
[3]王狄.加权的贝叶斯网络分类算法研究及应用[D].湖北师范大学,2024.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)