.jpg)
数字人在远程教育中的多场景应用与效能分析

刘磊
图萌(上海)科技有限公司 201100
1 引言
数字人技术是实现智能化远程教育的重要组成部分,也是现代教育信息化发展的基础。数字人技术可应用于很多教育领域中。例如,虚拟教师可用于提供个性化教学指导并预测学习效果。在远程教育中,数字人技术可用于在线课堂,其目标是检测学习者的学习状态,并提供实时教学反馈。构建数字人教育系统的任务相当具有挑战性,因为学习者的学习方式缺乏统一标准,且不同个体的学习需求各有不同。虽然目前围绕数字人的研究主要集中在从语音中推断出情感状态,但是视觉信息(面部表情和手势)也已被广泛使用。随着深度学习技术的出现,在过去的十年中,许多突破性的改进在几种已建立的教育技术领域,已经观察到诸如智能推荐、学习分析和适应性学习等方面。
在本文中,我们以端到端的方式研究,同时使用多模态交互和智能分析的数字人教育系统。使用为教学场景设计的深度神经网络架构,从学习行 提取特征;使用Transformer 网络架构,从教学内容中提取语义特征。这些网络的输出融合在一起并馈入智能决策模块,以确定最优的教学策略。与当前的做法相反,在该做法中,每个模块都经过单独训练,结果仅输入分类器,我们的系统以端到端的方式进行训练。
2 数字人教育方案
传统远程教育系统的第一步就是从教学数据中提取有效特征。为了提取学习行为中的特征,可以使用时间序列分析方法,通过滤波器进行时域分解以减少噪声数据的影响,也可以使用更复杂的深度学习内核。本文模型的关键部分是多模态融合运算。对于学习行为和教学内容信号,分别使用LSTM 和Transformer 进行特征提取。
其中 f(x)是一个智能决策函数,根据现有教学数据进行机器学习确定其参数。在对学习信号进行建模之后,该模型针对当前的教学目标,消除了无关信息并增强特定教学信号,使用带有注意力机制的神经网络对学习行为的时序结构进行建模。这种方法相较于人工设计特征的传统网络更为便捷和精确。最后,我们使用多目标函数对模型进行反向传播训练。
3 多场景网络结构
3.1 视觉交互网络
传统数字人视觉交互流程,都不是第一步就利用手工特征来提取面部表情特征。例如,光流法(OpticalFlow)和局部二值模式(Local Binary Pattern,LBP)等方法。深度卷积神经网络已经可以用于提取面部表情特征。本文中使用基于 ResNet-50 的改进深度网络,网络的输入部分,我们使用的像素强度从视频中经过预处理的面部图像中获得。深度残差网络通过堆叠构造块来采用残差学习形式:
其中 x 和 y 是第 k 层的输入和输出,F(xk,{Wk})是要学习的残差函数,h(xk)可以是恒等映射或线性投影来匹配 F 函数的维度和输入 x。改进的 ResNet-50 的第一层是一个 7x7,64 个特征映射的卷积层,随后跟一个尺寸 3x3 的最大池化层,网络的其余部分,包含 4 个 bottleneck 架构,在这些体系结构之后添加一个捷径(shortcut)连接。这些架构包含 3 个卷积层,每个残差函数的大小分别为 1x1、3x3 和 1x1。每个 bottleneck 架构复制数和特征映射数见下表。在最后一个瓶颈架构之后,插入一个全局平均池化层。

3.2 语音交互网络
与在传统语音识别领域所做的工作相反,先将语音特征提取然后传递给机器学习算法,我们的目的是在一个联合训练的模型中学习特征提取和情感识别步骤,来预测学习者状态。
输入:
在对音频序列进行预处理以使其具有零均值和单位方差之后,我们将原始音频分割为 5 秒长的序列,以解决不同学习者之间语音特征变化的问题。在16 kHz 采样率下,这对应于80000 维输入向量。
为了从高采样率信号中提取精细的频谱信息,我们使用 F=25 时空有限脉冲滤波器和4ms 的滑动窗口。本文使用 400ms 窗口的 M=50 时空有限脉冲滤波器。这些用于提取语音的更长期特性和语音信号的情感特征。
每个滤波器的脉冲响应通过一个 ReLU 激活函数(类似于人耳中的听觉处理步骤),然后通过将每个脉冲响应与大小为3 的池进行合并,向下采样到8 kHz。
跨通道的最大池化
本文在池域大小为 8 的整个通道域上执行最大池化。这会降低信号的维数,同时保留卷积信号的必要统计信息。
由于参数数量很大,需要执行一些正则化操作,以使模型不会过度拟合训练数据。本文选择使用概率为0.4的 dropout 值。
3.3 目标函数
为了评估网络的预测与教学效果之间的一致性水平,本文提出了教学效能相关系数(ρe)。但是,先前的工作在网络训练期间将MSE 最小化,但针对ρ 评估了模型。相反,我们建议在用于训练网络的目标函数(Le)中包括用于评估性能(L)的度量。由于目标函数是成本函数,因此我们将Le 定义如下:
3.4 网络训练
在训练多模态网络之前,将分别训练每个模态网络以加快训练过程。
视觉网络:
对于视觉网络,本文选择在此工作中使用的教 数据库上微调预训练 ResNet-50。该模型是在 ImageNet2012 分类数据集上训练的,该数据集由 1000 组成。 从头开始训练网络相比,预训练模型更可取,以便从模型已学习的功能中受益。为了训练网络, 顶部堆叠 个具有 128 个单元的 2 层 LSTM,以捕获时间信息。
语音网络:
CNN 网络对原始音频信号进行操作以提取特征。考虑到语音的时间结构,本文在CNN 顶部使用两个LSTM层,每个128 个单元。
多模态网络:
在训练视觉网络和语音网络后,将丢弃 LSTM 层,仅考虑提取的特征。语音网络提取 1024 个特征,而视觉网络提取 512 个特征。将它们连接起来以形成 1536 维特征向量,并用于为每个包含 256 个单元的 2 层 LSTM注入数据。对LSTM 层进行了训练,并对视觉和语音网络进行了微调。每个单峰和多峰网络的目标是最小化:对于语音、视觉和多模式网络的循环层,我们将 5 秒序列分割为 125 个较小的子序列,以匹配 40ms 频率的粒度。
4 实现架构
4.1 数字人渲染引擎
数字人渲染引擎是整个系统的核心组件,负责生成逼真的虚拟教师形象。该引擎基于深度学习的人脸生成技术,结合面部表情捕捉和语音驱动的唇形同步技术。渲染引擎包含以下主要模块:面部建模模块、表情驱动模块、语音同步模块和实时渲染模块。
4.2 多场景教学系统
多场景教学系统包括两个部分:场景识别部分和自适应教学部分。场景识别部分从学习者的行为数据中识别当前的学习场景。提取的场景特征被用于提供个性化的教学内容。这些用于捕获学习过程中的上下文信息。


4.3 效能评估模型
效能评估模型用于量化分析数字人教育系统的教学效果。该模型从多个维度进行评估,包括学习效果提升度、学习参与度、知识掌握程度和学习满意度。通过对比传统远程教育和数字人辅助教育的效果差异,验证系统的有效性。
5 实验结果与分析
5.1 数据集描述
本研究使用了自建的远程教育数据集,包含1000 小时的在线教学视频、50000 条学习行为记录和20000 份学习效果评估数据。数据集涵盖了理工科、文科和艺术类等多个学科领域,学习者年龄分布在 18-45 岁之间。5.2 效能对比实验
为验证数字人教育系统的效能,我们设计了对照实验,比较传统远程教育、录播课程和数字人教育三种模式的教学效果。实验结果显示,数字人教育模式在学习参与度、知识掌握率和学习满意度等方面均有显著提升。
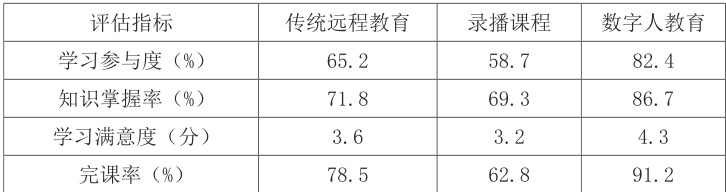
5.3 多场景适应性分析
通过分析不同教学场景下系统的表现,发现数字人技术在理论课程讲解和作业答疑场景中效果最为显著,而在实验操作指导场景中虽有改善但仍有提升空间。这主要归因于虚拟实验环境的真实感有待进一步增强。
6 总结展望
随着人工智能、计算机图形学等技术越来越 泛地应用于教育领域,跟踪最新的技术并应用于实际教学产品之中,对于教育工作者和技术研究者都 技术进行多场景远程教育应用,虽然计算量比较大,但教学效果显著提升。在未来, 这个方案可以在 复杂的教育环境中得到应用。考虑到整个系统目前主要是技术验证阶段,需要更进一步进行优化和完善,以达到大规模教育应用的需求和标准。
未来的研究方向包括:(1)提升数字人的真实感和表现力,增强学习者的沉浸式体验;(2)开发更加智能的个性化教学算法,实现因材施教;(3)构建更完善的多模态交互机制,支持更自然的人机对话;(4)扩展系统的应用场景,覆盖更多教育领域和学习需求。
参考文献:
[1] Zhang Wei, Li Ming, Wang Hua, et al. Digital Human Technology in Online Education: A Comprehensiv Survey[J]. IEEE Transactions on Learning Technologies, 2023, 16(2): 145-162.
[2] 陈晓明 , 刘雅丽 , 王建国 , 等 . 虚拟教师技术在远程教育中的应用研究 [J]. 中国远程教育 ,2023,(3):35-42.
[3] 李华 , 张强 , 赵雪梅 , 等 . 基于人工智能的个性化教学系统设计与实现 [J]. 计算机科学 ,2023,50(4):128-135.doi:10.11896/jsjkx.220200089.
[4] Johnson M, Smith A, Brown K. Multimodal Interaction in Virtual Learning Environments[J]. Computers &Education, 2023, 195: 104-118.
[5] 王明 , 李强 , 陈静 , 等 . 数字人技术在教育领域的应用现状与发展趋势 [J]. 电化教育研究 ,2023,44(5):68-75.
[6] Thompson R, Davis S. Effectiveness of AI-Powered Virtual Teachers in Distance Learning[J]. EducationalTechnology Research and Development, 2023, 71(1): 89-107.
[7] 孙莉 , 周刚 , 林敏 , 等 . 基于深度学习的智能教学系统研究与实现 [J]. 软件学报 ,2023,34(6):2856-2873.
[8] Anderson P, Wilson C, Taylor M. Real-time Facial Animation for Educational Virtual Humans[J]. ComputerGraphics Forum, 2023, 42(2): 234-248.
[9] 郭建华 , 马玉慧 , 刘晓东 , 等 . 远程教育中虚拟现实技术应用效果评估研究 [J]. 开放教育研究 ,2023,29(2):45-54.
[10] Kumar S, Patel N. Natural Language Processing in Educational Chatbots: A Survey[J]. IEEE Access, 2023, 11:15423-15441.
作者简介:刘磊,1986 年 4 月,江苏泰兴人研究方向:生成式人工智能(AIGC+xr)。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)