.jpg)
基于深度强化学习的模拟多区域协同交通信号控制系统的设计与实现

白一冰 宋文荣 邓凯
北京物资学院信息学院
1.引言
截至2025 年6 月,全国机动车保有量达 4.6 亿辆。36 个主要城市高峰期平均运行速度仅 20.3km/h ,总体处于中度拥堵状态。交通拥堵不仅降低出行效率,还加剧能源消耗和环境污染,制约城市经济发展。
传统交通信号控制系统存在显著局限:固定配时无法适应动态交通流变化,自适应控制虽能响应实时流量但成本高昂。近年来,深度强化学习在复杂决策问题中展现出显著优势,为交通信号控制带来新的可能。
目前基于强化学习的交通信号控制研究主要集中在单路口优化,对大规模城市交通网络的区域协同控制研究相对较少。本研究提出五区域协同控制架构,构建多维度奖励函数,开发自动化训练机制,实现了对传统方法的突破创新。
2. 系统设计与方法
2.1 系统整体架构
系统采用分层架构,包括数据采集层、智能决策层、控制执行层和监控管理层。将交通网络划分为中心、北部、南部、东部、西部五个区域,每个区域作为协调单元进行统一控制,能更好地捕捉区域间交通关联性。
2.2 核心理论架构
系统采用马尔可夫决策过程(Markov Decision Process, MDP),定义一个五元组(S,A,P,R,γ ⟩其中参数意义如下:
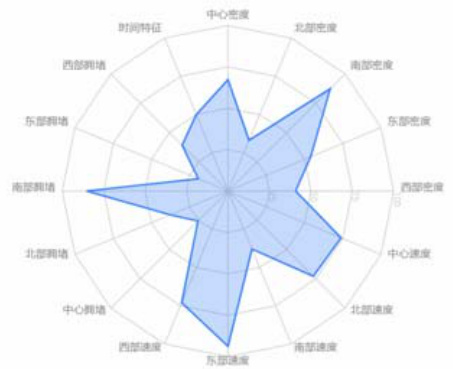
·S:状态空间,表示环境的所有可能状态·A:动作空间,表示智能体可以执行的所有动作·P:状态转移概率,P(s'|s,a)表示在状态s 执行动作a 后转移到状态s'的概率·R:奖励函数,R(s,a, 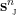 )表示在状态 s 执行动作a 转移到 s′ 时获得的即时奖励
)表示在状态 s 执行动作a 转移到 s′ 时获得的即时奖励
·γ :折扣因子, y∈[0 ,1],用于平衡即时奖励和未来奖励
2.2.1 状态空间设计
本研究设计了一个 16 维的状态向量,可以全面反映当前交通环境的特征信息。状态向量的构成包括了各区域车辆数量分布、各区域平均速度、区域拥堵程度(共15 维)和时间特征(1 维)。
时间特征的加入是为了使系统能够学习到不同时段的交通规律,提高控制策略的时效性和准确性。通过将当前小时数除以24 等对所有数据进行归一化处理,可以得到能够清晰表现所有特征的 16 维状态向量雷达图,将为区域协调提供很大便利。
图1 16 维状态向量雷达示意图
2.2.2 动作空间定义
本系统定义了四种基本控制动作,对应不同的交通控制策略[表 2.1] 。其中智能优化动作基于当前交通状态和历史经验进行概率性决策,在 40% 的概率下选择切换相位,体现了系统的自适应学习能力。
表1 四种交通控制动作对照表

2.2.3 奖励函数设计
奖励函数的设计直接决定了智能体的学习目标和优化方向,因此,本研究构建了多目标加权奖励函数,做到综合考虑交通系统的多个性能维度。
流动性奖励 (50%) :
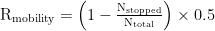
效率奖励 (30%) :
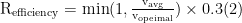
速度奖励 (15%) :
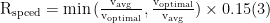
动作奖励占 5% ,对不同控制动作给予差异化的奖励或惩罚[表 2.1]
这种多维度加权设计确保了系统在优化交通效率的同时,兼顾交通安全和控制策略的合理性,避免了单一目标优化可能带来的负面效应。
2.3 深度强化学习算法实现
本系统采用改进的DQN 算法,网络结构包含两个128 神经元的隐藏层,使用ReLU 激活函数和经验回放机制(缓冲区容量10000),采用软更新策略(更新率0.005)和ε -贪婪探索策略(初始ε =0.5 ,最小ε =0.01 ,衰减率 0.995),确保探索与利用的良好平衡。
3. 实验设计与结果分析
3.1 实验环境配置
实验基于 CARLA0.9.13 版本进行,选择 Town10 地图作为测试环境。系统生成指定数量的自动驾驶车辆,采用随机分布点,确保交通流的多样性和真实性。为了模拟真实交通环境的复杂性,实验中涵盖了自行车,消防车等不同车型。
3.2 对比实验结果
为验证所提方法的有效性,实验设置了四种对比方案:固定配时控制、传统自适应控制、标准 DQN 方法和本研究提出的多区域协同 DQN 方法。每种方法在相同的交通环境下模拟运行500 回合。
实验结果显示,本研究提出的方法在所有关键指标上都取得了显著改善。车辆平均等待时间相比固定配时方法减少大于 33% ,相比自适应控制方法减少大于 25% ,相比标准DQN 方法减少大于 10% 。交通流动性指标提升幅度分别大于122% 、 80% 和 43‰ 。系统效率的改善程度为 133%~150% 、 90% ~110%和 8%~20% 。这些数据虽然在多次实验中波动较大,但整体符合后优于前,足以表明多区域协同控制策略和改进的奖励函数设计确实能够带来显著的性能提升。
4. 结论与展望
实验结果表明,所提方法在平均等待时间、交通流动性和系统效率等关键指标上都实现了显著改善,验证了方法的有效性。特别是在复杂交通环境下的良好适应性,为该方法的实际应用提供了有力支撑。
然而,本研究仍存在一些局限性。首先,本系统没有为每个区域设置独立的智能体,五个区域之间仅通过各区域的平均数据和全局考虑的奖励函数进行协同。其次,实验主要在仿真环境中进行,与真实交通环境可能存在差异。
未来的研究可以尝试扩展到更大规模的城市交通网络,或者集成多模态交通,处理包含行人和非机动车的复杂交通场景,获得更多、更可信的数据。最后还需要经历实际交通环境的部署测试,验证方法的实用性。通过这些改进和扩展,期望该研究能够为智能交通系统的发展做出更大贡献。
本项目由2025 年北京物资学院大学生创新创业项目支持
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)