.jpg)
地面气象站网监测数据采集质量保障系统:架构与数据处理机制

孙意博 刘广强 田野 赵晓钰
大连市气象装备保障中心 辽宁大连 116001;大连市普兰店区气象局 辽宁大连 116299
地面气象站网监测数据采集质量保障系统是提升气象灾害监测预警能力的关键支撑,能够有效弥补局地性、突发性气象灾害监测的“ 盲区” 。作为自动气象站的配套系统,其通过对接天元、天擎系统提取设备状态信息,结合气象数据与数据中心状态,综合分析全网设备运行状态并生成报告,为保障人员提供前瞻性故障信息,确保站网稳定运行。
1 系统架构与技术路线
系统采用分层架构设计,各层级协同实现数据从采集到应用的全流程管理,核心在于通过模块化设计提升系统的兼容性与高效性,具体系统架构与技术路线如图 1 所示。
图1 系统架构与技术路线
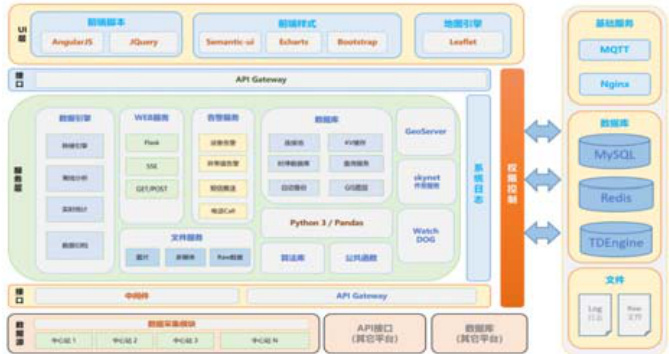
1.1 三层架构设计
系统的基础架构分为数据采集层、后台服务层与Web 前端层,三层职责明确且紧密衔接:
数据采集层:负责实时采集全国地面气象站的多维度数据(温度、压力、湿度、降雨量等),支持MQTT、HTTP 等多种通信协议及JSON、XML 等数据格式,确保对不同型号、不同地域气象站的r 泛兼容。
后台服务层:作为系统核心,承担数据处理、存储、分析、异常检测与报警等核心功能。依托高性能计算技术,实现海量数据的实时处理;通过分布式存储方案,保障数据的高效读写与安全存储。
Web 前端层:面向用户提供可视化交互界面,支持地图展示(气象站点分布与状态)、数据报表(统计指标与趋势)、报警信息(异常事件与处理状态)等功能,通过丰富的交互设计提升用户操作效率。
核心数据引擎是后台服务层的“ 神经中枢” ,包括:
数据转储引擎:实现数据的高效持久化存储,支持每秒数万条数据的写入与读取,适配大规模气象数据的增长需求;
离线数据分析引擎:对历史数据进行批量处理,支持复杂统计(如月度降水分布)与数据挖掘(如气候异常模式),为长期气象研究提供支撑;
实时统计引擎:实时计算关键指标(如温度骤升幅度),生成秒级反馈,满足灾害预警的时效性要求;
数据归档引擎:对过期数据进行压缩、备份与恢复管理,平衡存储资源占用与历史数据可追溯性。
1.2 微服务与响应式架构
为提升系统的可扩展性与灵活性,采用事件驱动的微服务架构:将数据采集、处理、异常检测等功能拆分为独立服务,服务间通过轻量级通信协议(如 RESTful API)交互。这种设计的优势在于:单服务可独立开发、部署与升级(如仅更新数据采集服务无需重启整个系统),大幅降低维护对全局的影响;同时支持根据业务需求动态扩展服务实例(如灾害多发期增加异常检测服务节点)。
后台服务层采用响应式编程模型(基于 ReactiveX 框架),通过非阻塞方式处理异步数据流。例如,当同时接收数千个气象站的实时数据时,系统可并行处理数据校验与存储请求,避免传统阻塞式编程的性能瓶颈,提升吞吐量与响应速度。
1.3 前端架构设计
前端采用浏览器/服务器(B/S)架构,基于 MVC(模型-视图-控制器)模式实现功能解耦:
模型(Model):负责处理数据逻辑,如将原始气象数据转换为统计指标(如日均温);
视图(View):通过网页界面展示数据,包括地图图层(气象站点标记)、图表(数据趋势曲线)等;
控制器(Controller):接收用户操作(如查询某站点历史数据),协调模型与视图的交互(如触发模型计算并更新视图展示)。
这种架构的优势在于:分离数据处理与界面展示,便于前端开发人员与数据分析师分工协作;同时支持跨设备访问(PC 端、移动端),提升系统的易用性。
2 开发技术与数据处理
系统的高效运行依赖于适配气象数据特性的开发技术与数据处理流程,核心是平衡数据处理的速度与精度。
2.1 编程语言与框架
后端开发以 Python 3 为核心,利用其生态优势实现高效开发与性能优化,编程语言框架如图2 所示。
借助异步编程(如 asyncio 库)实现非阻塞 I/O 操作,提升并发处理能力(如同时处理数百个站点的数据上传请求);
通过类型注解增强代码可读性,支持静态类型检查(如 mypy 工具),降低大型项目的维护成本;
结合 Pandas(数据清洗)、NumPy(数值计算)、SciPy(科学分析)等库,简化气象数据的统计与分析流程(如计算区域降水标准差);
针对计算密集型任务(如复杂气象模型运算),通过 Cython 将 Python 代码转换为 C 语言编译,执行速度提升 3-10 倍。
Web 服务采用Flask 框架构建 RESTful API,支持前后端分离开发。Flask 的轻量级特性使其可灵活适配业务需求,其依赖的Jinja2 模板引擎、Werkzeug WSGI 工具等,确保接口的稳定性与可扩展性。
图 2 编程语言与框架
2.2 数据处理全流程
数据处理包括预处理、存储与分析三个阶段,每个阶段均以“ 提升数据质量” 为核心目标:
数据预处理:首先通过清洗剔除缺失值(如用插值法填补传感器故障导致的空缺)、异常值(如
超出物理合理范围的温度值)与重复数据;再将不同格式数据(如 CSV、二进制)转换为系统标准格
式;最后通过校验规则(如湿度值需在 0.10% 范围内)过滤无效数据,确保进入存储环节的数据合规。数据存储:采用混合数据库架构适配不同类型数据的存储需求:
时序数据库(TDEngine):存储实时采集的时序数据(如每 5 分钟一次的温度记录),支持高并发写入(每秒 10 万+点)与时间范围查询(如查询某站点 24 小时降水数据);
关系型数据库(MySQL):存储业务数据(用户信息、权限配置)、元数据(站点编号、传感器型号)等,支持事务处理与复杂关联查询(如查询某区域所有站点的维护记录);
缓存数据库(Redis):缓存热点数据(如实时报警信息)与会话信息,将数据访问延迟从毫秒级降至微秒级,提升前端响应速度。
数据分析:通过统计分析(计算平均值、最大值等指标)、趋势分析(拟合降水变化曲线)、机器学习挖掘(识别异常气象模式)等方式,将原始数据转化为有价值的信息;最终生成日/周/月度报表,通过可视化界面辅助决策(如判断某区域是否存在干旱风险)。
3.数据存储优化与可视化
针对气象数据“海量、时序、地理关联”的特性,系统通过存储优化与地理可视化提升数据的可用性。
3.1时序数据库与混合存储优化
TDEngine作为时序数据存储核心,通过以下机制适配气象数据特性:
支持“超级表”模型:将同类型站点数据(如所有气温传感器)抽象为超级表,子表对应单个站点,便于批量管理与查询(如查询全国所有站点的气温最大值);
分布式扩展:预留集群扩展方案,可通过增加节点实现存储容量与处理能力的线性扩展,适配未来气象站网扩容需求;
存储策略:通过高效压缩算法(如Delta编码)降低存储占用(压缩率可达10:1);设置数据保留期限(如原始数据保留1年,压缩后保留10年),自动归档过期数据,平衡存储成本与数据追潮需求。
混合存储架构(MySQL+Redis)通过协同机制保障数据一致性: ⋅∘ 双写策略:写人MySQL时同步更新Redis缓存,确保用户查询的是最新数据;
缓存失效机制:数据更新时自动清除旧缓存,避免“脏读”(如传感器校准后及时更新缓存中的阈值);
数据同步:通过定时任务与binlog同步确保MySQL  Redis的数据一致,应对缓存服务器故障等异常情况。
Redis的数据一致,应对缓存服务器故障等异常情况。
3.2地理信息可视化
Web前端采用Leaflet地图引擎实现气象数据的地理关联展示,核心功能包括:
站点标记:用不同颇色/图标表示站点状态(正常、故障、维护中),鼠标悬停显示实时数据(如“温度25℃,湿度60%”);
空间分析:通过线条绘制等值线(如气温20℃等值线),多边形标记灾害风险区域(如暴雨预警区);
交互功能:支持地图缩放、平移、图层切换(矢量图/影像图),结合天地图服务提供高精度地理底图,提升数据的空间解读能力。
可视化设计的核心目标是:将抽象的气象数据转化为直观的空间信息,帮助保障人员快速定位异常站点(如某区域多个站点同时报警),辅助决策人员判断气象灾害的影响范围。
4 小结
本文阐述了地面气象站网监测数据采集质量保障系统的架构设计、开发技术与数据处理机制。通过三层架构与微服务设计,系统实现了对海量气象数据的兼容与高效处理;借助混合存储与优化策略,平衡了数据存储的性能与成本;通过地理可视化,提升了数据的可读性与应用价值。这些设计为气象数据质量保障提供了底层技术支撑,是系统实现“ 精准监测、及时预警” 的基础。
作者简介:孙意博(1999-),女,吉林长春人,硕士研究生,助理工程师,从事大气科学工作。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)