.jpg)
变电站二次电缆数据的Spark-KNN并行模式识别技术

宁雪峰
广东电网有限责任公司东莞供电局 广东东莞 523000
1、引言
变电站二次电缆状态监测正在从单一参数监测向全方位、群设备监测发展,数据量成几何增长趋势。大规模海量监测数据将涌向远程电网设备监测中心,使之面临繁重的数据收集、处理、存储和分析任务。在极端天气或连锁式故障情况下,二次电缆监测设备或装置由于监测值越限而频繁向监测中心发送报警数据,将在短时间内骤增。当前数据若得不到快速识别和诊断,随着报警的陆续增加,会造成分析任务和数据的堆积,甚至数据丢失,这对监测系统的性能提出了更高要求。
传统的单机环境下,使用单任务方式,对小样本数据量适用,但遇到紧急或特殊情况,当样本数据量急剧增大后,对存储和运算要求突然提高,一般很难在有限的时间内处理完成,甚至出现无法处理宕机等情况 。而目前通用的 Hadoop MapReduce[2]技术,虽然可以有效处理大数据,但针对需要多次循环迭代的输变电设备状态评价计算分析任务,需要频繁的磁盘I\O 操作,无法在短时间内完成对大量的越限报警数据的分析和设备状态识别,实时性难以满足要求[3], 需要借助内存并行技术加快数据分析的速度。
Spark[4]是一款基于内存计算的大数据并行计算框架。Spark 基于内存计算,使用弹性分布式数据集 RDD(Resilient Distributed Datasets)作为数据载体,并基于RDD 提供了多种便捷的操作,相比MapReduce,可以大幅提高数据处理性能,同时保证髙容错性和高可扩展性。Spark与Hadoop 兼容并且支持多种计算模式,包括流、以图形为核心的操作、SQL 访问以及分布式机器学习等。
很多分类算法都可以用于变电站二次电缆数据的分类,本文选择KNN 算法的主要依据是:1)KNN 属于经典分类算法,应用广泛,被各领域所熟知。为了体现云计算平台处理电力大数据的优势,选择经典算法,而并非新的机器学习算法。2)KNN 算法本身适合利用Spark实现并行化。并非所有的机器学习算法都适合在 Spark 上实现。KNN 分类算法具有简洁、参数估计简单等特点[5],适合对稀有事件、多分类问题进行分类,广泛应用于电力系统数据分析中。
本文基于Spark 并行计算框架,开展二次电缆状态快速模式识别技术的研究,设计实现并行化的快速KNN 算法Spark-KNN,并以变电站二次电缆数据为例,实现二次电缆线路状态的快速类型识别。
2、基于Spark 的状态监测数据并行模式识别
2.1 监测数据在RDD 中的分布式存储
Spark 的数据处理是建立在统一抽象的RDD 之上,并以基本一致的方式应对各种数据处理场景,包括MapReduce,SQL 查询,流计算,机器学习以及图计算等。RDD 是一个容错的、并行的数据结构,可以显式地将数据存储到磁盘和内存中,并能控制数据的分区。相对于MapReduce 编程模式,RDD 通过提供包括 map、flatmap、filter、join、groupBy、reduceByKey 等算子来操作数据,使得编写并行程序更加容易。
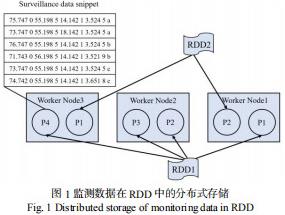
二次电缆装置监测的波形数据或者经特征提取之后的特征样本,在执行模式识别之前,以RDD 的方式分布式存储在Spark 集群的各数据节点中。RDD 可以被理解为一个大的数组,但这个数组是分布在集群上的。RDD 在逻辑上是由多个分区组成的。Partition 在物理上对应某个数据节点上的一个内存存储块。执行KNN 模式识别的过程,就是对RDD,使用一系列Spark 算子,进行转换,最终获得类别的过程。监测数据在RDD 中的存储如图1所示。
在图 1 中,RDD1 包含 4 个 Partition(P1、P2、P3、P4),分别存储在3个节点(Worker Node1、Worker Node2、Worker Node3)中。RDD2 包含 2 个 Partition(P1、P2)分别存储在2个节点(Worker Node3、Worker Node1)中。
2.2 Spark-KNN 快速模式识别算法
KNN 算法的基本思想是:如果一个样本在特征空间中的k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。由于KNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN 方法较其他方法更为适合。
模式的建立过程如下:建立并维护一个大小为 K 的、按距离由大到小的优先级队列,用于存储最近邻训练样本。随机从训练样本中选取K 个样本作为初始的最近邻样本,分别计算测试样本到这K 个样本的距离,将训练样本标号和距离存入优先级队列。遍历训练样本集,计算当前训练样本与测试样本的距离,将所得距离 L 与优先级队列中的最大距离 Lmax 进行比较。若 L>=Lmax,则舍弃该样本,遍历下一个样本。若L<Lmax,删除优先级队列中最大距离的样本,将当前训练样本存入优先级队列,直至遍历完成。
在优先级队列更新并确定后,计算优先级队列中K 个样本的多数类,并将其作为测试样本的类别,完成模式识别过程Spark-KNN 算法的输入、输出数据可以使用本地文件系统,或者HDFS;如果使用其他存储介质,如阿里云OSS 等,则需要自行编写输入和输出代码部分。
2.3 Spark-KNN 算法的 RDD 数据处理流程
Spark-KNN 算法的执行过程是建立在统一抽象的 RDD 之上的,是通过 RDD 的各类算子进行转换的过程。算法的数据处理流程如图 2所示。
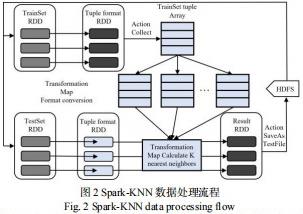
在图2 中,数据来源于HDFS,使用Spark Context 的textFile() 方法读取训练集和测试集文件,并将数据组织为RDD 的形式。格式转换操作通过map 算子完成。map 对RDD 中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD 中的元素在新RDD 中都有且只有一个元素与之对应。Collect 算子是Action 类型的算子,用于将分布式的RDD 返回到Driver 程序所在的节点,以scala Array 数组形式存储。broadcast 算子是 Action 类型的算子,用于将 Driver 节点上的数据广播到各个Worker 所在的节点;saveAsTextFile 算子用于将 RDD存储于 HDFS。
3、实验与结果分析
3.1 实验环境搭建
在阿里云云计算平台上,使用E-MapReduce 服务创建了包含5 台ECS 服务器的Spark 集群,部署方式采用目前流行的Spark on YARN模式,用于运行所设计的Spark-KNN 算法。硬件配置如下:
(1)Master 节点(1 个)
带宽:8M;CPU:4 核;内存:8G;硬盘类型:SSD 云盘;硬盘容量:40G;
(2)Core 节点(4 个)
带宽:8M;CPU:4 核;内存:8G;硬盘类型:SS 的云盘;硬盘容量:40G;
系统软件配置如下:
主版本:EMR 1.0.0
软件信息:hive 1.0.1;ganglia 3.7.2;Spark 1.4.1;yarn 2.6.0;pig 0.14.0;
上述软件部署之后,集群既可以运行Mapreduce 程序,又可以运行Spark 程序。其中的ganglia 3.7.2 程序主要用于集群硬件资源的利用率,依据其提供的CPU、内存利用率等监控数据,可以调整、优化并行任务配置参数,如根据CPU 利用率调整Spark 作业的number-exector的数量等,使集群性能充分发挥。
3.2 实验数据
实验数据来源于变电站二次电缆监测数据,并对数据进行了复制,以模拟产生出大规模的报警或者越限数据。
在数据规模上,本文模拟600 万个监测量(超过100 座变电站的监测量规模)的情形。通过设置设备的故障率(0-100%),模拟由于恶劣天气或设备故障发展阶段等情况下所产 时间内,需要 报警数据的规模在 0~600 万条范围内。本次实验中,仅使用了不同规模的二次电缆监测数据验证 Spark-KNN 的模式识别性能,暂未考虑对多源异构数据综合使用多种模式识别算法的情况。实验用数据集包括训练集和测试集,见表1。

3.3 Spark-KNN 性能测试
使用表 1 所示数据集对 Spark-KNN 算法进行性能测试。分别在单机环境下、Hadoop 集群环境下和 Spark 环境下,执行 KNN、MR-KNN和 Spark-KNN 程序,对比运行时间。其中,MR-KNN 和 Spark-KNN 运行的硬件环境相同。
3.3.1 单机环境下的KNN 处理性能测试
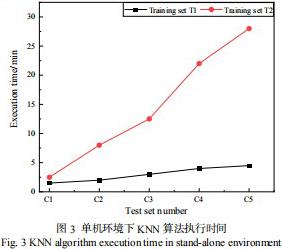
在单机环境下(4 核CPU,8GB 内存,40GB 高效云磁盘)执行KNN,算法运行时间随数据规模的变化如图3 所示。
从图3 中可以看出,在训练样集为T1(50 条样本)时,KNN 分类执行均可以控制在5 分钟以内,但当训练集为T2(500 条样本)时,KNN 执行时间明显增长,测试集为 C2 时,执行时间为8.8 分钟;当测试集为 C5(600 万条样本)时,执行时间接近半小时,工程实用性差;当训练集选择 T3 时,单机环境下运行时间过长,任务出现“假死”现象,在图 3 中未绘制 T3 曲线。上述实验结果表明,单机环境下无法胜任大规模报警数据的快速模式识别任务。
3.3.2 集群环境下并行化 KNN 性能测试
在所搭建的集群上,分别运行 Spark-KNN 和 MR-KNN,对不同数据规模情况下的运行时间进行对比,结果如图 4 所示。图 4(a)使用了训练集 T1,图 4(b)使用了训练集 T2,图 4(c)使用了训练集 T3。测试集均使用了 C1-C5。
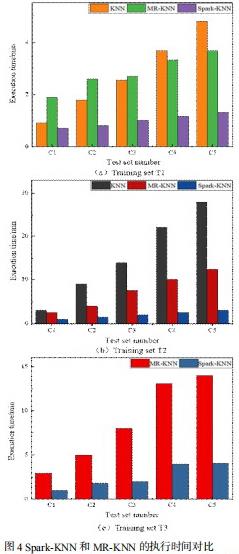
从图 4 中可以看出,使用不同规模的训练集,Spark-KNN 性能均优于 MR-KNN。在本次实验中,一次作业执行时,MR-KNN 与 Spark-KNN执行时间的比值,最大值可以达到 4.8,最小值为 2.3。Spark-KNN 的平均性能是 MR-KNN 的 2.97 倍。
在不同规模的训练集上(T1,T2,T3),Spark-KNN 的性能均优于单机环境,而 MR-KNN 在数据量较少时(图 4 中,T1C1、T2C2、T3C3),受磁盘读写、节点间通信开销影响,MR-KNN 执行速度慢于单机。Spark-KNN 高性能的主要原因在于,在程序执行之初,样本数据一次性加载至内存,并在之后的迭代计算中,始终保持在内存中,避免了 MR-KNN 过程中的反复磁盘读写,从而保证了数据的高效处理。
Spark-KNN 在不同数据集上的运行时间变化趋势如图 5 所示。
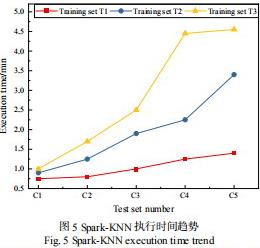
从图 5 中可以看出,随着测试集规模的增长,算法运行时间增长缓慢(远低于线性增长),对于不同规模的训练集,算法整体运行时间平稳,未出现大的波动。
Spark 程序运行时,使用 Spark on YARN 的运行模式,环境参数的配置至关重要,这些参数决定集群是否能够充分发挥其计算性能,会对程序执行性能有很大的影响。如果系统硬件配置发生变化,上述作业参数也需要及时调整。另外,还需要根据 ganglia 或者其他硬件监控程序提供的监测参数(CPU、内存利用率等),适当调整作业参数。
4、结论
本文研究了基于 Spark 内存计算技术的变电站二次电缆监测大数据实时模式识别方法,设计实现了 Spark-KNN 快速模式识别算法,用于海量二次电缆监测数据的快速模式识别。在阿里云 E-MapReduce 平台上搭建了实验环境,并完成了 Spark-KNN 和 MR-KNN 算法的性能测试。实验结果表明,Spark-KNN 的平均性能是MR-KNN 的2.97 倍,相比Hadoop MapReduce 更适合执行二次电缆设备监测大数据的实时处理任务。
参考文献
[1] Zhou Guoliang, Zhu Yongli, Wang Guilan, et al. Real Time Big Data Processing?Technology Application in the Field of State Monitoring[J]. TRANSACTIONS?OF CHINA ELECTROTECHNICAL?SOCIETY, 2014, 29(S1): 432-437.
[2] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM (S0001-0782), 2008,51(1): 107-113.
项目支撑:本论文来源于广东电网有限责任公司职工技术创新项目;项目名称:变电站二次回路判别和电缆识别装置研制;项目编号:031900KZ23030002
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)