.jpg)
基于CNN-LSTM方法的人群密度估计与应用

郑利红 黄腾樟
武警工程大学信息工程学院,西安,710086
1.引言
随着经济的发展和社会的进步,各地举办体育赛事、商贸洽谈、节日庆典、明星演出等大型活动日益增多,许多公共场所如高铁站、机场、地铁出入口,以及大型活动现场等,经常会出现人群聚集的现象,由此引发了许多群体性事件,严重影响了社会公共秩序,甚至危及人民群众生命财产安全,如2014 年12 月31 日上海外滩事件、2022 年 10 月29 日韩国的梨泰院事件,受到了各级政府和各类安保力量的高度重视,也引发了众多学者的研究热情。
近几年,深度学习被广泛应用于计算机领域,使用深度学习进行人群特征的检测也取得了极大进展。它较传统的群体运动检测方法,具有检测速度快、准确率高等优势[1],在进行群体特征检测时,常用的深度神经网络类型,主要包括基于卷积神经网络、基于双流网络、基于循环神经网络和基于 Transformer 识别模型[2],如:Zhang 等人提出了一种深度卷积神经网络[3],通过交替训练不同的学习目标,求得局部最优解,并利用数据驱动方法来调整经过预训练的 CNN 模型,检测从未见过的目标场景,增强了未知场景下应用的准确性。李洪均等人通过双流网络架构里的行为特征[4],设计了一个新型的时序分割网络模型,用跟踪群体行为来获取其中的个体跟踪序列。Bagautdino 等全卷积网络和RNN 进行视频时序处理,来识别个人的行动和集体的行动[5]。Liang等人首次提出基于Transformer 的人群密度估计模型[6],利用VIT 作为模型的主干网络,最后通过全连接层作为回归头进行人群密度估计。
事实上,CNN 是一种强大的图像分析工具,适用于提取图像中的多层次空间特征,它能够识别个体和人群的各种特征。而LSTM 会输出时间序列的特征,可以分析一系列连续视频帧之间的时间关联,学习人群动态变化的模式。因此,本文所采用CNN-LSTM 相结合的方法更加适合应用于人群密度检测。
2.相关技术
2.1 卷积神经网络
卷积神经网络(CNN)作为一种主流的深度学习模型,已经在图像处理和分析领域拥有了显著的成果。CNN网络包括输入层、卷积层、汇聚层:
输入层:用于接受原始的图像数据,并将这些数据向后续层传递。为了更加适应不同的任务,一般来说输入层的尺寸需要与原始图像的尺寸相匹配,同时,为了增强模型的稳定性和广泛适应性,输入层也可以执行图像的标准化处理以及数据增强等预处理步骤。
卷积层:主要承担特征提取和变换的职责。它通过学习针对特定任务的特征表示,从而增强图像处理和视觉任务的表现。利用卷积核对输入数据执行卷积处理, 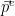 生的特征图展示了输入数据内部的局部特征信息。在数学中,两个函数(比如f, g:Rd→R)之间的“卷积”被定义为:
生的特征图展示了输入数据内部的局部特征信息。在数学中,两个函数(比如f, g:Rd→R)之间的“卷积”被定义为:
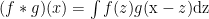
汇聚层:通过减小特征图的尺寸来提取更为显著的特征。CNN 中汇聚层的主要作用进行下采样,用来降低卷积层对位置信息的敏感性,常用的汇聚层操作是最大池化(如图1 所示),取输入特征图的某个邻域内的最大值作为输出特征图。还有一种比较常见的操作是平均池化。
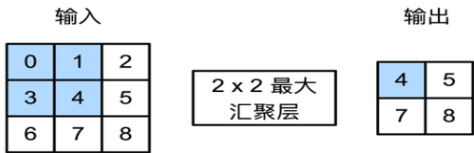
图1 最大池化操作
2.2 LSTM 长短期记忆网络
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种特殊类型,极其适用于分析和预测时间序列数据中时间间隔长和延迟的关键事件。LSTM 的核心是记忆单元(cell),它可以在长时间范围内保存状态信息。每个记忆单元由几个关键部分构成:输入门、遗忘门、输出门。这些“门”是通过训练数据学习到的一系列权重和偏置参数控制的非线性层,用Sigmoid 激活函数来决定门控单元打开或关闭的程度,以及用Tanh 激活函数来确定记忆单元和输出的状态。
相较于传统RNN,LSTM 有以下显著优势:避免梯度消失问题,灵活的记忆能力,因此LSTM 能够处理序列数据,并学习和记忆长时间序列的依赖性。
2.3 高斯核函数生成密度图
在密度图生成方法中的一个重要组成部分是模糊原理。本文采用二维高斯模糊技术,对于图像中的每个像素点,高斯模糊会根据其邻域内其他像素的强度加权平均,权重则由高斯函数决定,高斯函数在离中心像素越近的位置权重越大,而越远则权重越小。这样,中心像素附近的像素影响较大,较远像素的影响较小。假设高斯核的窗口大小为,高斯分布的标准差为,那么高斯核可以表示为矩阵的形式:

3.人群密度检测
3.1 人群密度检测原理
CNN-LSTM 人群密度检测原理如下:首先找到此次试验所需数据集。之后,对视频帧进行预处理以提高算法的性能,包括图像尺寸调整、格式化和归一化。CNN 的应用,预处理后的视频帧送入CNN,提取有助于人群密度预测的空间特征,并将这些特征输送给 LSTM 网络继续处理。通过 LSTM 的整合,接着将 CNN 提炼出的特征在时间上传递给LSTM 网络进行进一步分析。LSTM 能够学习视频帧中人员移动的时序模式,识别可能的趋势和规律。将CNN 提取的空间特征和LSTM 处理的时间序列特征合并,形成可以反映每个人群密度情况的综合特征。结合CNN和LSTM 的网络架构,CNN 和LSTM 获得的信息可以通过一个共同的框架整合起来,以提供对人群密度变化的准确预测。
在搭建好的 CNN-LSTM 神经网络模型基础上,以迭代的方式进行训练,每个迭代包含向前传播、损失计算、反向传播以及参数更新,得到训练权重,经过多次迭代,形成最后的神经网络模型,并将其用于测试数据的人群密度估计。
3.2 实验结果分析
本文选择包含了不同场景、不同人群密度的 ShanghaiTech 数据集,它包含两个数据集,数据集A 包含482张人群照片,由网络收集而来,每张图片都有不同的场景和分辨率,单张图片中尺寸最小的为 299³450,尺寸最大的为 1024×1024 。数据集B 从上海的闹市区拍摄而来,图像分辨率都是统一的,尺寸大小均为468³1024。同时为了增加训练的数据量,采用数据增强的方法增加训练图像的个数。对每张图片,随机选取 9 个有重合部分的图像区块进行裁剪,这些区块的大小是原始人群图片输入尺寸的一半,用作训练数据进行模型训练。
在实验中,所配置的实验环境为 python=3.7,pytorch=1.4,opencv-python=4.0,scipy=1.4.0,h5py=2.10,pillow=7.0.0,imageio=1.18,  。在模型训练过程中,参数设置为:模型训练的总轮次为 3000,每批处理的样本数为 16,裁剪尺寸为 256*256。学习率为 0.0001,权重衰减为 0.0005。使用所得训练模型,分别对ShanghaitechA 和 ShanghaitechB 中 2 张图像进行测试的结果如表 3-2 所示,其密度估计效果如图 2
。在模型训练过程中,参数设置为:模型训练的总轮次为 3000,每批处理的样本数为 16,裁剪尺寸为 256*256。学习率为 0.0001,权重衰减为 0.0005。使用所得训练模型,分别对ShanghaitechA 和 ShanghaitechB 中 2 张图像进行测试的结果如表 3-2 所示,其密度估计效果如图 2
图 2 CNN-LSTM 测试效果图
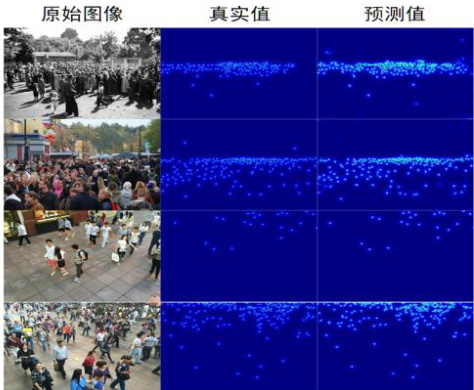
在相同条件下,采用训练模型对上海数据集 A 和上海数据集 B 进行了测试,所得测试误差如表 1 所示。上海数据集 B 的测试效果相比较于数据集 A 的效果更好, 原因由于数据集 A 图片主要来自于网络,图像鱼图像之间人群密度情况差异明显,并且密度变化巨大。数据集 B 主要来自于上海市街道不同位置,通过固定的摄像头采集的,环境更加一致,密度波动小于数据集A。
表 1 CNN-LSTM 测试误差

其中:MAE 计算预测值与真实值之间绝对差值的平均值。MSE 则表示预测值与真实值之间平方差的平均值。MAE 和MSE 值越小代表越接近真实值,假定表示样本总数,表示图像中的真实值,̂表示图像中预测值,计算方法为:
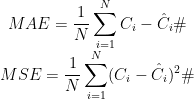
在进行视频人群密度检测时,首先从视频流中读取帧,调整帧大小并进行预处理,使用模型进行前向传播,得到预测结果,然后对模型输出进行处理,以计算检测到的人数并绘制关键点和 bounding boxes。同时使用cv2.putText 在图像上添加文本,并使用cv2.imwrite 将结果保存为图片作为视频帧,写入输出视频,形成检测结果视频。下图是采用CNN-LSTM 方法对一段地铁监控视频进行人群密度估计结果如图3 所示,其中左上图为视频中的某一帧,左下图为人群检测结果,右边两张图为不同背景颜色下的人群密度估计可视化展示图。

图3 原视频的可视化显示
4.人群密度检测应用分析
人群密度图可以直观展示当前人群的分布情况,同时利用视频分析也能反映出人群的动态变化,例如观察连续的密度分布变化,可以发现人群动态变化规律,及时找出可能存在的安全隐患,以此能够更好监控人群,提供相对安全的环境。
对视频监控进行智能化的研究,也是目前社会治安管理部门、学术界以及视频监控产业中的各个软件、硬件企业所关心的一个热点和难题。本文通过分析监控视频中的人群特征,自动识别视频中群体的异常特征,实现监控场景的危险预警,不仅可以有效提高监控设备的智能化水平,避免社会公共安全事件的发生,且极大地丰富了人工智能的理论研究和应用实践。
5.结束语
当前监控视频已经遍布城市的各个角落,通过监控视频可以查看现场情况,及时发现人群异常,有利于群体性事件前中期的干预、后续的救援以及疏导工作,从而为避免群体性事件发生或者降低人员伤亡提供可能。因此,如何利用新的技术,分析现场监控视频中的人群特征,实现活动区域态势智能化感知、安全事件及时预警和事后人员精确管控,对武警部队完成维护国家安全和社会稳定的职责使命,具有重要的理论价值和现实意义。
参考文献
[1]蔡涛. 基于深度学习的人群计数系统研究与实现[D].武汉:中南财经政法大学,2021.
[2]裴利沈,赵雪专.群体行为识别深度学习方法研究综述[J].计算机科学与探索,2022,16(04):775-790.
[3]Zhang C,Li H, X. Wang X, et al.Cross-scene crowd counting via deep convolutional neural networks[C],Computer Vision and Pattern Recognition (CVPR).IEEE,2015, 833-841.
[4] 李洪均, 丁宇鹏, 李超波等.基于特征融合时序分割网络的行为识别研究[J].计算机研究与发展,2020,57(01):145-158.
[5]Bagautdinov Alahi Fleuret t l.Social cene nderstanding: nd-to-End ulti-P Action Localization and Collective Activity Recognition.[J].CoRR,2016,abs/1611.09078
[6] iang , hen , u , t l. ranscrowd: eakly-supervised rowd ounting ith ransformer[J]. ar Xiv preprint ar Xiv:2104.09116, 2021
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)