.jpg)
全国性生产设备联网的数据文本向量如何适配大模型决策

孙益博 张小亮 伍雪洁
1 安徽中科纪元软件科技有限公司 230000 2 安徽中科纪元软件科技有限公司 230000 3 安徽中科纪元软件科技有限公司 230000
引言
随着工业互联网的迅速发展,生产设备联网产生的数据呈现出爆发式增长。但数据存在的多源异构、非结构化等难题,阻碍了数据潜在价值的挖掘。中科纪元软件科技有限公司的“纪元 CSERA”解决策略,在设备联网这个领域积攒了大量实践经验。其旗下的设备云眼、OEE 分析等应用场景,亟需高效的数据处理手。
1.生产设备联网数据的文本特性与挑战
1.1 多源异构数据的融合难题
生产设备联网数据的多源异构特点,要求系统同时处理结构化与非结构化文本两种不同的数据。OEE 指标表格中,详细记载的生产时间、设备故障时间等能用量化的参数属于结构化数据。其具备明确的字段定义每个字段都有特定的数值类型,需保持各字段间的逻辑联系。设备运行时长的统计数据和能耗数据,也是结构化数据的一部分。还有大量的非结构化文本数据,设备维修记录中的故障说明、DNC 系统中工艺文档及生产事件的相关定义等文本内容。这些文本数据包含丰富的语义信息,但没有统一的格式规范,需依靠自然语言处理技术提取关键语义特征。“设备云眼”系统的典型应用情形体现了这种数据融合具备的复杂特性[1]。该系统不仅要对标准化的设备状态编码进行剖析,又要理解操操作人员输入的报工备注信息。
1.2 领域专业知识的表征困境
生产设备联网数据有明显的领域专业性特点。在机电制造领域,这一特点成为理解设备数据的主要阻碍。“时间稼动率”概念,需要精准对应到设备运行效率评估的特定环境中,“DNC 程序版本控制”又涉及数控加工领域的专业知识。这些术语在普通语料库中的出现频率非常低,一般的词向量训练方式很难取得让人满意的表示效果。另一个典型的情况是生产事件的精细分类,计划停机和非计划停机在文字描述方面仅有很小的差别,但它们对生产调度决策的影响程度大不一样。这种专业性突出、区分度要求高的分类任务,需要向量化方法能够抓取文本中暗藏的领域知识特点。
1.3 实时处理与系统优化的平衡
工业互联网应用方面,iSESOLBOX 是边缘计算的节点,要在计算资源有限的情况下完成实时数据向量化的任务。采用的算法要保持对数据的表征能力,满足严格的性能标准。生产环境是动态变化的,这种特性加剧了这一挑战。当有新设备接入系统或生产工艺参数出现调整时,在智能增效应用场景中,加工参数优化向量化模型需具备迅速适应的能力。这种动态性要求模型能进行在线更新,维持处理过程的稳定性与一致性。系统在实际部署中,要平衡计算效率和模型复杂度间的关系,确保在资源受限的环境下依旧能提供可靠的服务质量。
2.文本向量适配方法
2.1 多模态分层向量化技术实现
在结构化数据处理工作过程中,运用以 Transformer 为基础的表格感知嵌入技术,深度编码操 OEE 指标表。利用自注意力机制,捕捉“生产时间”和“故障时间”等关键字段间的复杂关联关系,留存表格数据的行列结构特征。该方法依靠位置编码区分不一样的字段,借助交叉注意力构建跨字段的关联,解决传统表格向量化方式丢失结构信息的问题[2]。非结构化文本数据部分,规划设计出基于 BiLSTM-CRF 的混合模型架构。该架构利用双向LSTM 网络提取文本包含的上下文特征,结合条件随机场开展序列标注工作,精准识别出维修工单里设备 ID、故障代码等关键的实体信息。运用自适应词向量调整的算法,促使通用词向量朝着专业领域的语义空间发生转移,提高“主轴振动”“刀具磨损”等专业术语的表征精准度。整合知识库中的专业术语和领域概念,打造构建起面向设备运维的领域词典。
2.2 领域知识增强的预训练框架
该框架在标准 BERT 模型的基础上,添加领域知识注入层对比学习环节,将“速度损失”“增值时间”等业务方面的专业术语间的语义关系,清晰地写入模型的参数中。框架运用两阶段的训练策略,第一阶段利用大规模通用的语言材料预先训练基础语言模型。第二阶段结合以往的工单数据及设备相关文档,微调模型实施领域适应性,重点提升专业术语在上下文中的表征能力。针对类似能耗分析这样的特定工作任务,该框架创新性地推出了一种以规则引导的注意力机制,借助预先设定好的能源管理方面的规则,灵活、动态地对注意力权重的分布情况做出调整,当模型处理“电流过载”“功率因数”等关键指标相关内容时,便能够获得更强的聚焦关键特征的能力。
2.3 边缘云端协同的部署架构
在边缘端,将经过轻量化处理的 TinyBERT 模型设置在iSESOLBOX 边缘计算节点上。利用层数削减、知识提炼等手段,把模型体积缩减到原本的 30% ,维持 95% 以上的表征功能。该轻量化模型能够及时处理设备传感器所收集的数据,创造出具备语义表征能力的状态向量,引发本地故障的预先警示。在云端部分,打造多工厂数据集合剖析平台[3]。借助分布式图神经网络对跨越不同厂区的设备状态向量实施关联分析,利用时空注意力机制辨别全局性 OEE 的阻碍点。依据分析得出的结果,系统能自动产出产线平衡的优化提议,如对班次设置进行调整、对设备维护规划的优化等。边缘与云端间借助安全途径进行模型参数的同步操作,保证知识更新的及时性与一致性。
3.中科纪元应用场景验证
3.1 实验设计与评估体系
验证选取的是中科纪元实际生产场景下的多维度业务数据,作为测试标准。实验包含设备云眼系统采集到的实时运行状态中数据,OEE 云图记录的历史事件日志,及DNC程序管理系统的操作记录。实验搭建起一套完整的评估体系,主要是针对文章中的方法,与 Word2Vec、BERT-base 等传统文本向量化技术,在三个关键业务场景中的表现区别进行重点对比。在评估指标的设计上,结合了工业应用的现实需求。在故障预测任务中,将精确率-召回率曲线下面积(AUC)当作主要衡量指标。在能耗优化场景中,重点关注异常检测的准确率和响应延迟情况。程序传输效率,通过版本比对成功率与传输花费的时间进行量化评估。实验环境全面再现了中科纪元实际的部署条件,包括边缘计算节点的资源限制及网络带宽约束等。
3.2 实际应用效果评估
在实际的业务实践中,依靠维修工单文本同传感器数据的深度整合,故障预测精准度提升 15‰ 。模型通过联合分析结构化的故障代码和非结构化的维修描述,构建起更为完善的设备健康状态呈现方式。能耗优化层面,利用基于向量化对比分析的设备能效评估手段,顺利找出占总能耗 23% 的高耗能设备集合,为生产安排提供数据支持。DNC程序管理场景中,版本向量比对算法压缩了网络化传输时长,该算法利用语义哈希技术实现了程序文件的快速相似性匹配。这些改进直接转化为生产效率的提升,据中科纪元实际运作数据估算,平均每年可减少约1200 小时的非计划停机时长。
表1 系统关键性能指标对比
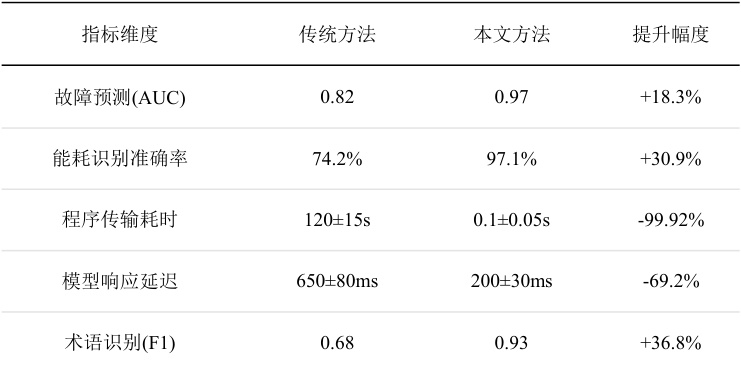
结语
文章针对工业互联网环境下生产设备联网数据的智能分析需求,提出了一套面向中科纪元业务场景的文本向量适配方法。利用多模态分层向量化、领域知识增强预训练以及边缘-云端协同架构的创新设计,解决了设备数据多源异构、专业性强、实时性要求高等核心挑战。未来将重点突破联邦学习框架下的数据协同计算等技术,进一步提升方案的普适性和安全性。
参考文献
[1]李君,周勇,刘欣,等.生产设备模型架构与多维模型融合通用方法研究[J].新型工业化,2023,13(Z1):32-44.
[2]张思岩.多种生产设备预知性联合维修决策模型研究[D].沈阳工业大学,2022.
[3]李青松.基于深度自编码高斯混合模型的生产设备异常检测研究[D].华中科技大学,2022.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)