.jpg)
基于强化学习的机器人在复杂工业环境中的自适应运动控制策略研究

许杰
广西科技师范学院
引言
机器人技术在工业生产中的应用愈加广泛,尤其在处理高精度、高效率和高安全性任务时,机器人的自适应能力成为一个重要的研究方向。在复杂的工业环境中,机器人需处理诸如环境变化、障碍物、复杂任务等问题。传统的控制方法通常依赖于预设 难以应对环境的动态变化。因此,如何使机器人在面对多变环境时仍能维持高效、精准的操作成为 究难题 强化学习(Reinforcement Learning,RL)作为一种模仿人类学习机制的算法,通过不断 调整策略来优化行为,展现出了巨大的潜力。本文将探讨基于强化学习的机器人自适应运动控制策略,研究其在复杂工业环境中的实现与应用。
一、基于强化学习的机器人运动控制的理论
1. 强化学习与机器人运动控制的基本原理
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,主要研究智能体如何在一个环境中通过与环境交互,依据奖励信号调整其行为,从而达到预定目标。在机器人运动控制中,强化学习被广泛应用于控制系统的优化、路径规划及任务执行等方面。基本的强化学习过程包括环境、智能体、状态、动作、奖励五个要素。智能体基于环境的状态信息,通过选择某个动作与环境交互,然后接收奖励信号来更新策略。机器人在执行运动控制任务时,首先需要感知环境状态,通过传感器获取当前的环境信息。机器人根据感知到的状态选择相应的动作,并执行该动作。执行结果产生一个奖励信号,智能体根据这一信号来调整其行为策略。强化学习中的核心部分是价值函数。价值函数用来评估在某一状态下采取特定动作的好坏。它的数学表示为:V(s)=E[Rt ∣St =s] 其中,V(s)V(s)V(s)表示状态 sss 的价值,RtR_tRt 是时间步 ttt 的奖励,StS_tSt 是当前状态。智能体通过最大化长期累积奖励来优化控制策略。针对机器人运动控制任务,常用的强化学习算法包括Q-learning、深度 Q 网络(DQN)等。
2. 机器人运动控制中的强化学习应用
在实际应用中,机器人运动控制的目标是通过强化学习算法优化机器人的轨迹规划、路径跟踪和姿态调整等任务。机器人通过对环境的感知,实时做出决策并执行动作。强化学习为此提供了一种通过反复试错来学习最优控制策略的方法。例如,在一个多自由度的机械臂运动控制中,机器人在每个时间步骤都会根据当前的状态(如关节角度、速度等)选择一个动作(如某个关节的转动角度)。机器人通过环境反馈的奖励信号来优化动作选择策略。假设奖励函数定义为:其中,xtx_txt 为机器人当前位置,xtargetx_{target}xtarget 为目标位置。该奖励函数表示机器人与目标位置之间的距离,距离越近奖励越大,距离越远奖励越小。机器人通过多次迭代来学习如何接近目标位置,从而实现精确的运动控制。深度强化学习算法(如DQN)可以将强化学习与深度神经网络结合,通过神经网络对状态和动作的关系进行建模,使得机器人能够在高维状态空间中有效地学习控制策略。在机械臂控制中,深度 Q 网络通过估计每个动作的 Q 值(即状态-动作值)来进行决策,公式为:Q(st ,at )=rt +γat+1 max Q(st+1 ,at+1 ) 其中,Q(st,at)Q(s_t, a_t)Q(st ,at )是当前状态 sts_tst 和动作ata_tat 的价值,rtr_trt 是当前时刻的奖励,γ\gammaγ是折扣因子,表示对未来奖励的重视程度。
3. 强化学习在机器人运动控制中的挑战与前景
尽管强化学习在机器人运动控制中有着广泛的应用前景,但其面临的挑战也不容忽视。首先,机器人在实际环境中的状态空间非常大,传统的 Q-learning 算法在大规模状态空间中往往难以应用。此时,深度强化学习成为一种有效的解决方案,通过使用深度神经网络对状态-动作对进行近似,可以解决大规模状态空间问题。机器人在复杂环境中进行运动控制时,环境的动态性和不确定性对强化学习过程产生了很大的影响。比如,机器人可能在执行任务过程中遇到未知的障碍物或者由于传感器误差导致状态感知不准确,这将直接影响到学习过程和策略的优化。因此,如何设计更加鲁棒的奖励函数、如何处理不确定性和动态环境成为强化学习在机器人控制中亟待解决的问题。针对这些问题,研究人员提出了多种方法来增强强化学习的稳定性和收敛速度。例如,基于模型的强化学习方法通过建立环境模型来预测未来的状态和奖励,进而提高学习效率。此外,基于多智能体的协同学习、迁移学习等方法,也在一定程度上提高了机器人在复杂任务中的学习能力。未来,随着强化学习算法的不断优化和计算能力的提升,机器人运动控制将更加精准和高效。尤其是在自动驾驶、智能制造等领域,基于强化学习的运动控制系统有望提供更高效、灵活的解决方案,提升机器人的智能化水平和自适应能力。强化学习为机器人运动控制提供了强有力的理论基础和应用方法。通过利用强化学习中的价值函数、奖励函数和深度学习方法,机器人可以实现高效的路径规划和运动控制。尽管面临着状态空间维度大、不确定性强等挑战,强化学习仍然在实际应用中展现出巨大的潜力和发展前景。
二、基于强化学习的机器人自适应运动控制
1. 自适应控制策略的理论基础与模型构建
自适应控制策略旨在根据外部环境的变化和系统自身状态的变化自动调整控制参数,从而保证机器人运动控制的稳定性和精确性。基于强化学习的自适应运动控制策略通过不断调整策略来优化机器人的运动表现,使其能够应对动态变化的环境和未知任务。自适应运动控制的核心是利用强化学习算法(如Q-learning、深度Q 网络(DQN)等),根据机器人实时反馈的环境信息自动调整控制策略。具体而言,机器人通过传感器实时采集环境状态信息,选择动作并根据执行结果接收奖励。强化学习的目标是通过最大化累积奖励来学习最优控制策略,从而提升机器人在复杂环境下的自适应能力。在自适应控制策略模型中,机器人通过强化学习过程不断优化控制策略。模型的构建可以通过以下几个步骤:状态空间定义,状态空间表示机器人在不同环境下的感知信息,如位置、速度、加速度等。状态空间的设计对控制策略的优化起着至关重要的作用。通过传感器获取机器人当前的状态,作为强化学习算法的输入。动作空间设计,动作空间表示机器人可以采取的所有可能动作。例如,在一个机械臂的控制中,动作空间可能包括每个关节的转动角度。动作的选择基于当前的状态,强化学习算法根据最大化奖励来决定最优动作。奖励函数用于评估机器人当前状态和动作的优劣。例如,可以设计一个奖励函数来惩罚机器人偏离目标路径,奖励其接近目标位置的行为。奖励函数通常依赖于机器人的目标任务和环境动态变化。基于以上理论基础,强化学习模型的构建采用了Q-learning 和深度Q 网络(DQN)等方法,具体的控制策略流程如图1 所示。
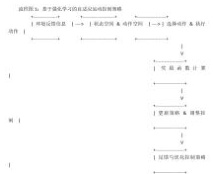
2. 基于强化学习的自适应运动控制策略应用实例
在机器人控制领域,强化学习的自适应控制策略已被应用于多个实际场景,下面以自动驾驶与机械臂运动控制为例,具体分析其控制策略及实施效果。在自动驾驶系统中,基于强化学习的自适应控制策略可以有效应对多变的路况环境。假设一个自动驾驶机器 人在复杂的城市道路上行驶, 机器人需要根据实时感知到的交通信息(如障碍物、交通信号、道路曲率等) 相应的行驶决策。为了优化运动控制,机器人会根据当前的感知状态(如车速、距离前车的距离、道路曲率等)选择适当的动作(如加速、减速、转弯等)。奖励函数的设计通常与车辆的安全性和行驶效率相关。例如:
Rt =-λ1 ∥xt −xtarget ∥2−λ2 ∥vt −vdesired ∥2
其中,RtR_tRt 是当前奖励,xtx_txt 为当前位置,xtargetx_{target}xtarget 为目标位置,vtv_tvt 为当前速度,vdesiredv_{desired}vdesired 为期望速度,λ1,λ2\lambda_1, \lambda_2λ1 ,λ2 为权重系数。该奖励函数结合了机器人与目标位置之间的距离和速度与期望速度之间的差异,优化了自动驾驶系统的运动控制。基于DQN算法,自动驾驶系统通过学习历史数据和实时反馈,不断优化驾驶策略,以提高安全性和行驶效率。通过训练,机器人能够适应不同路况并做出合适的决策。
3.机械臂控制中的自适应运动控制
在机械臂控制中,机器人通过感知当前关节角度和末端执行器的位置来进行运动控制。假设机械臂需要完成一个抓取物体的任务,通过基于强化学习的自适应控制策略,机器人可以根据当前的状态和任务要求自动调整运动轨迹。例如,机械臂的控制策略可以通过DQN 算法进行优化。在此应用中,状态空间可能包括机械臂的各个关节角度、速度和末端执行器的当前位置。动作空间则包括各个关节的转动角度。通过设置奖励函数,机器人将收到以下反馈:
Rt=−∥pt−ptarget∥2R_t = -\|p_t - p_{target}\|^2Rt  −ptarget ∥2
−ptarget ∥2
其中,ptp_tpt 为当前末端执行器的位置,ptargetp_{target}ptarget 为目标位置。奖励函数通过奖励机械臂接近目标位置,惩罚偏离目标的动作。机器人通过强化学习不断优化动作选择策略,最终学会完成抓取任务。机器人通过强化学习不断优化动作选择策略,最终学会完成抓取任务。在一个机械臂抓取任务的实例中,机器人需要根据物体的位置调整抓取策略。通过训练,机器人在不同环境下学会了根据感知信息(如物体的位置、夹爪的姿态等)选择最优的抓取动作。强化学习通过反馈调整机器人的运动轨迹,使机械臂能够在复杂环境中完成任务。具体而言,机器人通过DQN 算法不断探索状态-动作对的最优策略,从而能够在不同的抓取任务中适应变化并优化运动控制。
3. 强化学习的自适应控制策略面临的挑战与未来发展
尽管基于强化学习的自适应控制策略在多个领域取得了显著成果,但仍面临着一些挑战,尤其是在高维状态空间、动态环境及实时计算需求等方面。机器人在执行复杂任务时,状态空间往往是高维的,传统的Q-learning方法难以处理大规模状态空间。为此,深度强化学习(如 DQN、A3C 等)通过神经网络对状态-动作对进行逼近,成功解决了高维问题。机器人在实际应用中,常常面临复杂和不确定的环境。在自动驾驶和机械臂控制中,环境的动态变化对策略学习和运动控制提出了更高要求。为此,研究者们提出了基于模型的强化学习方法,通过建模环境来预测未来状态,从而提高策略学习的稳定性。计算资源与实时性要求:自适应控制策略通常需要大量的计算资源和实时的反馈。随着计算能力的提高,基于深度强化学习的自适应控制将变得更加高效。此外,边缘计算和分布式学习等技术的应用,将有助于解决实时计算的问题。基于强化学习的自适应运动控制策略通过不断优化控制策略,提高了机器人在复杂和动态环境下的自适应能力。在自动驾驶、机械臂控制等应用中,强化学习能够根据实时反馈自动调整运动控制策略,从而实现任务目标。尽管仍面临高维状态空间、环境动态变化等挑战,随着技术的发展,强化学习将在更多实际应用中展现巨大的潜力。
结论
强化学习通过智能体与环境的互动来学习最优控制策略。具体而言,机器人作为智能体,通过感知环境状态,选择动作并执行,从而获取奖励信号。通过多次与环境交互,机器人能够不断优化其控制策略,以实现任务目标。强化学习的核心目标是最大化长期累积奖励,这一过程通常通过状态空间建模、动作空间设计以及奖励函数构建来实现。在工业环境中,机器人需要根据不同的工作任务和环境变化自适应调整其行为。这要求机器人能够处理复杂的高维状态空间和实时决策问题。强化学习正是通过不断调整其行为策略,使机器人能够在动态变化的环境中执行各种任务,如自动化生产、装配、物料搬运等。通过算法的选择与优化、状态空间与动作空间的建模以及自适应控制策略的实现,机器人能够自动调整其运动轨迹,适应环境的变化。实验验证表明,强化学习不仅提升了机器人的任务完成效率,还增强了其在多任务、多变环境下的自适应能力。
参考文献
1]王强. (2020). 基于强化学习的工业机器人运动控制研究. 机械工程学报, 56(3), 145-153.
[2]陈杰. (2021). 深度强化学习在机器人路径规划中的应用. 自动化学报, 47(2), 321-330.
[3]周鹏飞. (2019). 强化学习算法优化及其在机器人运动控制中的应用研究. 机器人技术与应用, 39(4),57-65.
[4]张丽. (2022). 机器人自适应控制策略研究综述. 机器人技术与智能装备, 15(1), 72-80.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)