.jpg)
生物启发计算在解决复杂软件工程问题中的应用前景探讨

高晨阳
中材智能科技(成都)有限公司 210000
生物启发计算是模仿自然界生物行为和机制来解决问题的一种方法,它涉及多个领域,如人工智能、计算机科学和生物学。随着信息技术的迅速发展,软件工程领域面临着越来越多的复杂问题,例如大规模系统的优化设计、自动代码生成、软件质量保证等。这些问题的解决不仅需要高效的算法支持,还要求算法具备一定的智能化水平。因此,生物启发计算在软件工程领域的应用显得尤为重要。
生物启发计算通过模仿自然界中某些生物的行为特征,比如蚂蚁的觅食行为、鸟群的迁徙模式、鱼群的群体行为等,开发出一系列智能优化算法。这些算法以其独特的求解方式,在处理软件工程中的复杂问题时展现出了极大的潜力。
一、生物启发计算在解决复杂软件工程问题中的应用(1)复杂问题与智能优化算法
在软件工程领域,复杂问题的解决往往涉及到大规模的数据处理、资源分配以及系统优化等任务。这些问题通常具有高度的非线性、多目标和动态变化的特点,传统的计算方法难以有效应对。因此,智能优化算法应运而生,成为解决这类复杂问题的有效工具。
智能优化算法主要包括遗传算法、神经网络、机器学习等,它们模仿生物进化、神经系统或人类学习机制,通过迭代搜索来寻找最优解。这些算法的核心优势在于其强大的全局搜索能力和适应复杂环境的能力。
以遗传算法为例,它模拟自然选择和遗传学原理,通过选择、交叉和变异等操作逐步优化种群中的个体。算法的基本流程可以表示为:
f(x)=minx∈S
其中, f(x) 是需要最小化的函数, x 是决策变量, 是定义域。
(2)生物启发计算的原理
生物启发计算是一种模拟自然界生物行为和机制的计算方法,旨在解决复杂问题。其核心原理基于对生物系统中优化、适应和学习过程的模仿。这些生物系统包括但不限于遗传进化、群体行为、神经网络结构和学习机制等。
在生物启发计算中,一个基本的概念是“适应度”,它衡量了个体(解决方案)在特定环境中的性能。适应度函数 f(x) 通常定义为 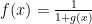 ,其中 g(x) 是目标函数,表示需要最小化或最大化的量。通过不断迭代,算法寻找使 f(x) 最大化(或最小化)的 x 值,即最优解。
,其中 g(x) 是目标函数,表示需要最小化或最大化的量。通过不断迭代,算法寻找使 f(x) 最大化(或最小化)的 x 值,即最优解。
生物启发算法通常包含几个关键步骤:初始化种群、评估适应度、选择操作、变异和交叉(或称为重组)。例如,在遗传算法中,种群由多个个体组成,每个个体代表一个问题的潜在解决方案。通过选择适应度高的个体进行繁殖,结合变异和交叉操作,生成新的种群,逐步逼近最优解。
此外,生物启发计算还借鉴了自然界中的其他现象,如蚂蚁觅食路径的最短路径问题,蜂群搜索食物源的策略,以及神经元之间的信号传递机制等。这些自然现象为设计高效的算法提供了灵感,使得生物启发计算能够处理传统算法难以解决的复杂问题。
二、生物启发计算在解决复杂软件工程问题中应用面临的挑战
(1)算法效率与性能
在生物启发计算领域,算法效率与性能是衡量其在解决复杂软件工程问题中应用价值的关键指标。算法效率通常指算法执行所需的时间和资源消耗,而性能则侧重于算法解决问题的能力和质量。对于生物启发计算而言,这两者之间的平衡尤为关键,因为高效率的算法往往难以保证高性能,反之亦然。
算法效率可以通过时间复杂度和空间复杂度来量化。时间复杂度描述了算法运行时间随输入规模增长的变化趋势,而空间复杂度则描述了算法运行过程中所需内存空间的增长趋势。例如,遗传算法的时间复杂度通常为 O(n2) ,其中 n 代表种群大小,这表明随着种群规模的增加,算法的运行时间将显著增加。
性能评估则需要考虑多个维度,包括但不限于解的质量、收敛速度和稳定性等。解的质量直接关系到算法能否找到最优或近似最优解,而收敛速度和稳定性则影响算法的实用性和可靠性。
(2)可解释性与透明度
在生物启发计算应用于复杂软件工程问题的解决过程中,可解释性与透明度是两个不可忽视的重要方面。随着算法的不断优化和应用范围的扩大,如何确保算法的决策过程对用户来说是透明的,以及算法的输出结果能够被理解和信任,成为了研究的重点。
生物启发计算,如遗传算法、神经网络和机器学习等,虽然在处理复杂问题上展现出强大的能力,但它们的“黑箱”特性使得其内部机制难以被理解。这种不透明性不仅影响了用户的信任度,也限制了这些技术在某些需要高度可靠性的领域的应用。
为了解决这一问题,研究者们正在探索多种方法来提高生物启发计算的可解释性与透明度。例如,通过开发新的算法框架,使算法的决策过程更加直观易懂;利用可视化工具帮助用户理解算法的运行过程和结果;以及采用模型简化技术,减少算法的复杂度,从而提高其透明度。
此外,加强算法设计时的可解释性考量,比如在算法设计之初就考虑到后续的解释需求,也是提升生物启发计算可解释性与透明度的有效途径之一。通过这些措施,可以逐步提高生物启发计算在软件工程领域中的应用价值,使其成为解决复杂问题的有力工具。
(3)模型的泛化能力
在生物启发计算应用于复杂软件工程问题时,模型的泛化能力是衡量其性能的关键指标之一。泛化能力指的是模型在未见过的数据上表现的能力,即模型能够将从训练数据中学到的知识应用到新的、未见过的数据上的能力。对于软件工程领域而言,这意味着算法不仅需要在特定项目或问题上有效,还应能适应不同的开发环境和需求。
评估模型泛化能力的一个常用方法是通过交叉验证。具体来说,可以将数据集分为多个子集,依次使用每个子集作为测试集,其余作为训练集,从而得到多个模型的性能评估结果。这种方法有助于减少因数据划分不同而导致的偏差。
模型的泛化能力可以通过以下公式进行量化:
泛化误差 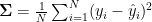
其中, N 是测试集中的样本数量, yi 是第 个样本的真实值, 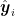 是模型预测的值。
是模型预测的值。
(4)系统的稳定性与鲁棒性
在生物启发计算应用于复杂软件工程问题的过程中,系统的稳定性与鲁棒性是评估算法性能的重要指标。稳定性指的是系统在面对外部干扰或内部参数变化时,能够保持其功能和性能不发生显著变化的能力。鲁棒性则强调系统在存在不确定性和异常情况时,仍能正常运行并达到预期目标的能力。
对于生物启发计算而言,提高系统的稳定性和鲁棒性是实现高效、可靠软件解决方案的关键。这不仅涉及到算法设计本身,还包括算法的实现细节、测试方法以及应用场景的适应性等方面。
结论
生物启发计算作为一种有效的智能优化手段,在解决复杂软件工程问题中展现出了巨大的潜力。本文通过探讨生物启发计算在软件工程中的应用,分析了遗传算法、神经网络以及机器学习等技术如何有效地针对复杂问题进行求解,并对这些方法的挑战进行了详细的分析。
然而,生物启发计算在实际应用中也面临着多方面的挑战。算法效率与性能需要进一步提升,以适应更高复杂度的软件工程问题。可解释性与透明度的问题也是研究和应用过程中不可忽视的一环,特别是在关键的决策支持系统中。此外,模型的泛化能力及系统的稳定性与鲁棒性对于确保生物启发计算方法能够在不同环境和条件下可靠运行至关重要。
参考文献:
[1] 白保琦. 计算机软件开发应用及其未来发展趋势探析[J]. 电脑知识与技术,2021,(17):53-54.
[2]周喜红.培养软件工程专业本科生解决复杂工程问题能力的探讨[J].产业与科技论坛,2020,(23):145-146.
[3]陈庆.关于自动化专业领域复杂工程问题的研究[J].科技风,2020,(07):257.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)