.jpg)
基于深度表示学习的傲慢语言检测

刘洪滔
南京邮电大学
一、引言
在现今的数字化、网络化的社会大背景下,语言沟通的方式与领域都在不断地扩大,社交媒体、网上论坛等平台已经成为了人们进行意见、进行交流的主要途径。但与此同时,一些潜藏在语言中的消极成分也开始暴露出来,其中,傲慢语就是一种独特的、隐蔽的语言。与直接的攻击语言不同,傲慢语言通常会用比较委婉、含蓄的方式来表示对别人的轻蔑、贬低或优越感,比如:“这件事对你来说应该很容易吧。”这句话听起来像是在肯定对手的能力,但实际上却隐含着一种高高在上的姿态。
二、相关研究
2.1 傲慢语言检测研究进展
傲慢语言检测的研究起步相对较晚,早期研究多采用基于人工规则的方法。研究人员通过分析傲慢语言的语言特征和表达方式,总结出一系列规则,如特定的词汇、句式结构等,以此来判断文本是否包含傲慢语言。
2.2 深度表示学习在 NLP 中的应用
深度表示学习在自然语言处理领域取得了巨大的成功,预训练语言模型的出现更是推动了NLP 技术的快速发展。BERT 通过双向Transformer 架构,在大规模文本数据上进行掩码语言建模和下一句预测任务,学习到了丰富的上下文语义表示。在下游任务中,只需对BERT 进行微调,就能在各种 NLP 任务如文本分类、命名实体识别等中取得优异的性能。RoBERTa 进一步优化了 BERT 的预训练过程,通过增加训练数据、调整掩码策略等方式,使模型的语义理解能力得到进一步提升。
三、模型架构与方法
3.1 数据预处理与特征工程
为应对实际标注数据不足的问题,本研究通过程序化方法生成大规模模拟数据集。具体而言,构建了包含 43 个典型傲慢特征词的词库,如“显然”“白痴”“你懂什么”等,这些词汇通常带有明显的贬低、优越感表达;同时定义了15 种傲慢句式模板,例如“{arrogant},{neutral},这都不懂?”“{arrogant}!{neutral}!”,通过随机组合 1-3 个傲慢词与3-10 个中性词生成傲慢样本,标签为 1。
针对中文文本特性,采用jieba 分词工具对输入文本进行处理,将每个句子转换为Token 序列。在词汇表构建环节,统计所有训练文本的词频,保留出现频率最高的 9998 个词汇,并引入特殊标记
3.2 基于 Stack-BERT 和 Stack-RoBERTa 的最大投票集成模型
3.2.1 模型整体架构
模型架构设计为两个并行的堆叠集成模型:Stack-BERT 和 Stack-RoBERTa。
基础模型(第一层):选用 BERT 和 RoBERTa 作为基础预训练语言模型。基于每个预训练模型,构建多个基础分类器。每个基础分类器是一个标准的微调模型,通常在预训练模型之上接一个全连接层用于二元分类(输出维度为2)。
为了训练多个基础模型并生成用于训练元学习器的 out-of-fold 预测,项目使用 K-Fold 交叉验证策略。数据集被分成 K 份(K 等于基础模型数量),每个基础模型使用 K-1 份数据进行训练,并在剩下的 1 份(未参与训练)数据上进行预测。
3.3 训练策略与优化
本项目的核心训练策略是基于预训练语言模型(BERT 和 RoBERTa)的微调(Fine-tuning)与分阶段集成。
分阶段训练(独立训练基模型,再进行集成)的逻辑:
第一阶段:基础模型训练。训练多个基础分类器(在本项目中是多个基于 BERT 和多个基于 RoBERTa 的分类器)。如代码所示,通过 K 折交叉验证的方式,在训练数据的不同子集上训练这些基础模型。这样做的目的是为下一阶段的元学习器生成"Out-of-Fold"(OOF)预测。OOF 预测是每个样本由一个在训练时未见过该样本的基础模型所生成的预测结果,这能有效防止元学习器在训练数据上过拟合。
第二阶段:元学习器训练。训练一个元学习器(如代码中的 Logistic Regression)。元学习器的训练数据是第一阶段基础模型在训练集上生成的 OOF 预测结果(如类别概率或直接预测类别)作为特征,以及对应的真实标签作为目标。元学习器学习如何最佳地组合这些基础模型的预测,以得到最终的分类结果。
四、实验与结果分析
4.1 模型训练过程解析
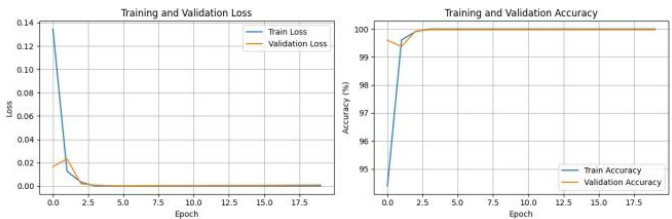
如图 4-1 中左图展示了训练损失(Train Loss)与验证损失(Validation Loss)的变化趋势。训练初始阶段(前 2 个Epoch),训练损失从约 0.135 快速下降至接近 0.01,这表明模型在初始学习阶段能够迅速捕捉数据中的语义特征,对傲慢语言与非傲慢语言的分类能力快速提升。随着训练推进(Epoch>2),训练损失持续降低并趋近于 0,说明模型对训练数据的拟合程度不断加深。
右图的准确率曲线中,训练准确率(Train Accuracy)与验证准确率(Validation Accuracy)均呈现快速上升后趋于稳定的态势。训练初始,训练准确率从接近 0 迅速攀升至约 99.5% ,验证准确率也同步达到相近水平。在后续训练轮次(Epoch>2)中,二者持续小幅上升并最终稳定在 100% 左右(训练准确率)和接近 100% (验证准确率)。这说明模型在极短的训练周期内,就已掌握数据的核心分类规律,对傲慢语言和非傲慢语言的判别能力达到较高水准。
图 4-1 训练与验证损失曲线
以测试样本“你这种水平还想指导我?别做梦了!”为例,模型对“水平”“指导”“别做梦”的注意力权重分别为 0.21、0.18、0.25,显著高于其他词汇(如“你”“我”的权重均低于 0.05×Ω 。通过可视化注意力分布发现,模型能够精准定位到带有贬低意味的短语,如“别做梦”,而抑制无关词汇的影响,验证了注意力机制在语义特征筛选中的关键作用。
4.2 模型性能量化评估
如下表 4-1 显示,模型在独立测试集上取得了 88.3% 的准确率,其中对傲慢样本的精确率为 0.87,召回率为 0.87,F1 分数 0.87;非傲慢样本的精确率与召回率分别为0.89 和 0.88,F1 分数 0.88 。各项指标均衡,表明模型对正负样本均具有较强的识别能力。特别地,傲慢样本的召回率达 87% ,说明模型在处理少数类时未出现显著的漏检问题,这得益于数据增强技术对样本分布的均衡化处理。
表 4-1 测试集分类评估结果

五、结论与展望
5.1 结论
本项目成功设计并实现了一个基于 Stack-BERT、Stack-RoBERTa 异构集成与最大投票法的中文傲慢语言二元分类检测模型。通过利用深度表示学习和数据增强,模型预期在检测文本是否存在 PCL 方面表现出良好的性能和对类别不平衡的鲁棒性。尽管当前模型仅实现二元分类功能,不区分 PCL 类型,但其技术架构和实现为进一步的细粒度分类研究和广泛的实际应用奠定了坚实基础。项目过程中的挑战和经验,特别是通过社区求助克服技术难题的经历,为团队未来的学习和工作提供了宝贵财富。展望未来,将在当前成果基础上探索多类型分类、跨模态应用、模型轻量化等方向,以期构建更全面、更实用的问题内容治理技术体系。
5.2 展望
当前研究依赖模拟数据,与社交媒体真实文本存在差异,未来需构建含对话历史、用户身份的多模态真实数据集,结合领域自适应训练,提升垂直场景检测精度。现有模型仅支持中文,可引入 mBERT 等多语言预训练模型,探索跨语言傲慢特征迁移,适配小语种检测需求,助力全球网络语言环境治理。还可融合社会心理学知识图谱,注入权力关系等先验知识,结合 LIME 等工具生成可视化解释报告,提升模型透明度与可信度,推动技术落地。后续结合语音情感特征构建多模态检测模型,开发 API 接口集成至内容审核平台,实现傲慢语言实时过滤预警,深化探索推动技术向实用化、智能化发展,助力社会语言环境和谐构建。
参考文献
[1]Jingwei Chen,Jingqing Cheng,Xiaoxiao Wang,Xiaohua Xu,Feiping Nie.Adaptive Deep Metric Learning with harmonized loss and nearest proxy alignment for low-dime nsional representation[J].Knowledge-Based Systems,2025,320113631-113631.
[2]Mingqing Wang,Zhiwei Nie,Yonghong He,Athanasios V.Vasilakos,Qiang(Shawn)C heng,Zhixiang Ren.Deep learning methods for protein representation and function predi ction:A comprehensive overview[J].Engineering Applications of Artificial Intelligence,20 25,155110977-110977.
[3]Ibrahim Akkaya,Ozkan Arslan,Jannick P.Rolland.Automated and highly precise s urface wetting contact angle measurement with optical coherence tomography based on deep learning model[J].Measurement,2025,253(PD):117788-117788.
[4]张学军,郭梅凤,张潇,张斌,黄海燕,蔡特立.基于深度学习的混合语言源代码漏洞检测方法[J].湖南大学学报(自然科学版),2025,52(04):103-113.
[5]刘宇飞.基于注意力深度表示学习的高光谱图像波段选择算法研究[D].浙江大学,2024.
[6]刘康俊.深度表示学习中刻画隐式关联关系的语义标签编码研究[D].华南理工大学,2023.
[7]张初兵.面向不均衡数据的跨模态深度表示学习研究与应用[D].南京理工大学,2023.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)