.jpg)
大型语言模型对泌尿外科临床教学的应用价值研究

何崇源
达州市达州区人民医院(达州市第三人民医院) 四川省达州市 635000
关键词:大型语言模型;人工智能;泌尿外科教学
泌尿系统医学临床教育需整合解剖学、生物力学及临床实践,但传统教学模式面临显著挑战 [1]。以 ChatGPT-4o (4o) 为代表的大型语言模型 (LLM),展现出弥补教育短板的潜力 [2]。DeepSeek-V3 (V3) 是深度求索公司研发的垂直领域大模型,支持知识点解析及个性化学习路径规划。目前还未有研究报道二者谁更适合辅助医学生学习。本研究通过队列观察研究设计,系统评估 4o 和 V3在泌尿系统教育中的有效性及潜在风险,填补该领域研究空白。
1. 资料和方法
本研究于 2025 年 1 月至 2025 年 5 月在我院泌尿外科招募实习生共 60 例。分组: ① 4o 组:使用4o 进行辅助学习复习; ② V3 组:使用V3 进行辅助学习复习。本研究的核心目标包括观察医学生在泌尿系统教育中自然使用 4o/V3 的模式,分析其使用特征与学业表现的相关性。本研究结局指标:学生测试 / 期末成绩差异(均值差异(Mean ±SD )及其统计学差异(P 值)表述)。本研究采用SPSS 27.0 进行统计分析。统计学显著性阈值设定为 P<0. 05. 。
2.结果
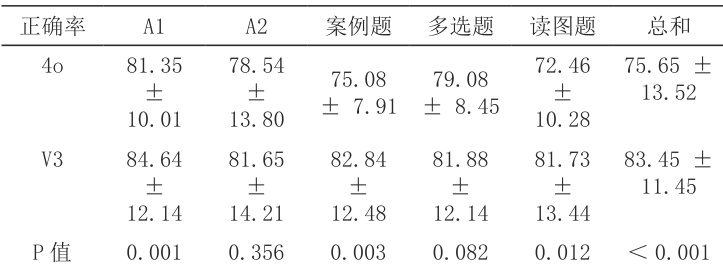
本研究共对 60 名符合条件的学生进行了评估参与,在 LLM 学习后的测试中,V3 组的通常能够回答 83.45(SD 11.45) % 的问题,而4o 组的人只能回答75.65(SD 13.52)% 的问题( ΔP<0.001Δ) 。在A1( (P=0,001) ),案例分析( (P=0.003) ,读图题 (P=0.012 )上,V3 组的准确率明显高于4o 组(表1)。
表一 应用大型语言模型辅助学习后测试正确率
应用大型语言模型辅助学习后,参与者期末考试的成绩见表三。我们惊喜地发现,V3 辅助的参与者在期末考试中得分更高,包括外科学( (P=0,017) ),和儿科学( (P=0.003) ),尽管妇产科学 (P=0.502⋅ )、内科学( (P=0.648 )和传染病学 (P=0,082 )无统计学意义,但V3 组的成绩均稍高于4o 组(表2)。
表二 应用大型语言模型辅助学习后期末考试成绩


3. 讨论
这是首次针对使用 4o/V3 作为干预手段对医学生进行教学的研究。本研究发现 V3 辅助学习后的实习生在回答泌尿外科相关的选择题时准确率很高,并且使用 V3 的学生不仅对泌尿外科知识有了更深入的理解,而且在其他学科的期末考试中表现也更加出色。这些结果为医学生利用 V3 作为辅助学习工具提供了坚实的基础。
医学教育的目标是帮助学生建立坚实的医学理论基础和基本的临床技能。选择题测试已成为评估医学理论知识最常用的工具之一 [3]。研究发现,使用LLM 作为学习工具可能提高获取泌尿外科相关信息的有效性,并提升测试成绩。使用 V3 作为辅助学习工具的学生在学期末的大多数科目评估中表现更佳,这表明V3 用户可能愿意调整学习策略,将4o 纳入日常学习工具。
值得注意的是,作为辅助工具,V3 能够帮助用户更高效地收集所需信息,从而提升工作和学习效率。随着社会、科学和技术的发展,学生主动适应并结合自身学习方式与学习媒体及辅助学习工具的更新迭代,这一趋势不可逆转。因此,社会应对教学方法、教学内容和学生评估提出更高的要求。
参考文献:
[1]Gunes YC, Cesur T, Camur E, et al. Textual Proficiency and Visual Deficiency: A Comparative Study of Large Language Models and Radiologists in MRI Artifact Detection and Correction. Academic radiology. 2025 Feb 11.
[2]Kambhampati S, Stechly K, Valmeekam K. (How) Do reasoning models reason? Annals of the New York Academy of Sciences. 2025 Apr 12.
[3]DeSantis M, McKean TA. Efficient validation of teaching and learning using multiple-choice exams. Adv Physiol Educ. 2003 Dec;27(1-4):3–14.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)