.jpg)
文本驱动三维模型生成实验研究与工程实现

李沛林
广州工商学院 广东广州 510800
近年来,伴随生成式人工智能(Generative AI)的快速发展,基于自然语言描述自动生成三维模型(Text-to-3D)的研究成为人工智能与计算机图形学领域的研究热点。相比传统的 3D 建模方法,文本驱动的建模方式具备操作门槛低、表达能力强和通用性好的优势,广泛应用于游戏、虚拟现实、工业设计等多个领域。通过研究文生 3D 模型在中低显存设备下的运行状况,探究其在教学与工程实践上的可行性。
一、相关技术概念
(一)扩散模型(Diffusion Model)。扩散模型是一类基于随机过程进行生成建模的深度生成方法,近年来在图像生成领域取得突破性进展。其中,Stable Diffusion 作为一种高效的潜在空间扩散模型[1],在保证生成质量的同时大幅降低了对显存的占用,并支持丰富的文本输入模式。
(二)Gaussian Splatting。Gaussian Splatting(高斯溅射)是一种新型的三维场景表示方法,其核心思想是使用一组在空间中分布的可微高斯点(3D Gaussians)来近似真实场景的几何与纹理信息 [2]。与 NeRF[3] 相比,该方法在渲染速度、训练效率和资源使用方面表现出显著优势。
(三)Text-to-3D 生成框架。Text-to-3D 技术致力于将自然语言描述直接转化为可视化的三维模型。主流方法可分为两个阶段:首先通过文本驱动生成高质量的中间图像表示(如多视角渲染图),然后利用这些图像信息进行三维形状重建。本研究选取的生成框架为GaussianDreamer[4],其结合 Gaussian Splatting 表示与 Stable Diffusion,引入基于高斯场的三维建模策略,显著提升了训练效率与生成质量。
(四)CLIP[5]。CLIP(ContrastiveLanguage–ImagePretraining,对比语言 - 图像预训练)是由 OpenAI 在 2021 年提出的一种多模态(Multimodal)深度学习模型。它的核心思想是让计算机同时理解图像和文本之间的关联,从而实现更智能的跨模态检索、生成和分类任务。
二、实验环境与流程
(一)实验硬件与软件环境。为了验证 GaussianDreamer 模型的实际可运行性与工程适配性,本文基于个人工作站构建完整实验环境,相关配置如表1 所示。
表1 实验环境与配置
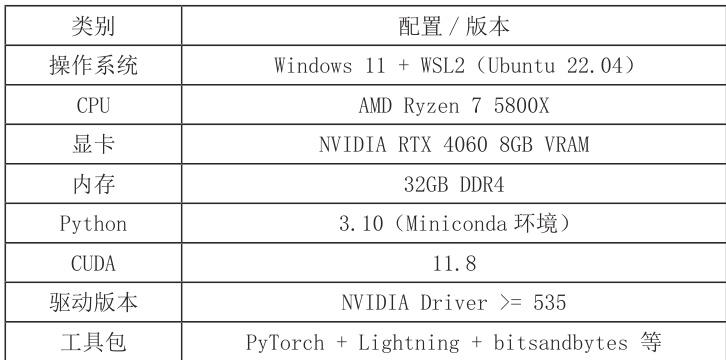
模型运行于 WSL2 中的 Ubuntu 系统,使用 miniconda 构建名为 GaussianDreamer 的独立虚拟环境,以确保依赖隔离与版本一致性。
(二)模型配置与运行流程。实验使用官方提供的配置文件 Gaussiandreamer-sd.yaml,并基于实际硬件情况作了如下调整 : 显存控制参数如 train.max_steps 与 train.batch_size 适配8GB 显存;每个prompt 单独配置输出路径,避免模型输出重写;默认使用stable-diffusion-2-1-base 模型作为文生图基础。系统将根据修改后的 yaml 文件与对应的 prompt自动生成图像,再通过多视角重建实现3D 表面建模。
三、实验设计与工程实现
为系统评估 GaussianDreamer 模型在多样化文本输入下的三维建模能力,并验证其在中端硬件设备上的工程可行性,本文设计了包括 Prompt 样本构建、训练流程配置、运行效率优化和输出结果管理在内的完整实验流程,现总结如下:
(一)Prompt 样本设计策略。实验共设计10 组英文提示词(prompt),具体提示词见表2。涵盖静物、交通工具、虚拟角色等多个类别,重点考察模型在不同语义结构和视觉风格下的泛化能力。
表 2 提示词(Prompt)示例


(二)参数适配。为展现 GaussianDreamer 在中低显存设备下的训练效果,调整实验配置的部分参数,如将 batch_size 设置为 2,图像分辨率设置为 512*512,max_steps 设置为1000 等,以及对训练过程中出现的部分问题,进行针对性优化。
四、结果评估
(一)效果评估。表 3 为生成 3D 模型的相关指标,均使用 GaussianDreamer 第 1000 次生成的 0 号图作为评估样本。其中生成效果使用 CLIP[5] 模型为 ViT-B/32 的 CLIPScore 进行评估,除了生成效果指标外,还计入了提示词类别、最大显存占用与任务时长作为附属指标。
表3 生成模型指标
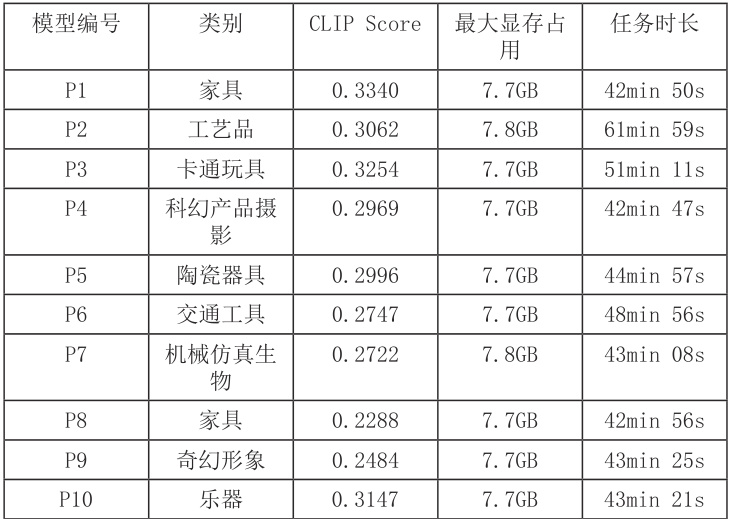
可以看到,经过调整的 GaussianDreamer 生成任务,CLIPScore 分值在 0. 22~0 .34 之间,符合 3D 模型渲染图的经典区间,且除部分任务外,最大显存占用与任务时长相对稳定。最后尝试对 P2 模型进行重新训练,修改其 max_steps 参数为 3000,最终其生成时长延长为135 分 42 秒,CLIP Score 为 0.3311,时间成本投入较大,但改进有限。
五、总结
随着生成式人工智能技术的不断发展,文本驱动的三维内容生成逐渐成为计算机视觉与图形学领域的重要研究方向。本文基于最新提出的 GaussianDreamer 模型,围绕文本到 3D点云表达的自动建模流程,完成了 10 个典型英文 prompt 的实验训练,深入探索了基于高斯表示的三维生成机制在语义驱动建模中的工程实现效果。在资源开销方面,实验结果表明GaussianDreamer 在消费级 GPU(如 RTX4060)上也能完成稳定训练任务,单个 prompt 平均训练时间约为 46 分钟,最大显存占用在 7.7GB 左右,且符合 3D 模型渲染图的经典区间,具备良好的工程可落地性。
参考文献:
[1]RombachR,BlattmannA,LorenzD,etal.High-resolutionimagesynthesiswithlatentd iffusionmodels[C]//ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpatternr ecognition.2022:10684-10695.
[2]WuT,YuanYJ,ZhangLX,etal.Recentadvancesin3dgaussiansplatting[J].Computatio nalVisualMedia,2024,10(4):613-642. [ 3 ] R e m o n d i n o F , K a r a m i A , Y a n Z , e t a l . A c r i t i c a l a n a l y s i s o f N e R F - based3Dreconstruction[J].RemoteSensing,2023,15(14):3585.
[4]YiT,FangJ,WangJ,etal.Gaussiandreamer:Fastgenerationfromtextto3dgaussiansb ybridging2dand3ddiffusionmodels[C]//ProceedingsoftheIEEE/CVFConferenceonComputer VisionandPatternRecognition.2024:6796-6807.
[5] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PmLR, 2021: 8748-8763.
作者简介:李沛林(1996. 07-) ,男,汉,广东潮州人,中级工程师,硕士,研究方向:计算机应用
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)