.jpg)
A review of natural language processing based on Transformer model

Zhang Kaiqiang Wang Zhenhui Gao Qian
College of Engineering and Technology Xi' an Fanyi University Shaanxi Xi' an 710105; Xi' an iFLYTEK
Abstract:The emergence ChatGPT marks the pinnacle techno ns in the field Natural Lguage Processing(NLP). It is a deep learning based model archi d solve problems more conveniently. It c achieve natural lguage dialogue gTernersfatoiromn,era,nwdhciacnh ibse ahpeplbiaesdis nfrieilmdsplseumchenatsinqguemsatijonr oarnascwle imnogdseyls esumcsh, adisalGoPgTu,e BroEbRotTs, Tin5t.elTlihge netmceursgteonmce osferTvriacnes.foDremeper eharsnitrnig giseraed eaepretvhoelourtiyoon tihfiecifiael idntoefl iNgeLnP.ceI,tssed fN-aLttPenist o imepcohratnainstmd made NLP tas epffliecairenitnga.ndThaeccmuroastte,famndoucshdaindfleuesnetqiaulenmcoedseolf ntyhe efinegltdh(ocfhaNrLacP eisr saenqdudeencmeosn,sit.rea. tedx.t). Its parallel proces efficien ssing larg ale data. By reviewing the development history NLP, com dels, the ad ced ideas importt position Trsformer models c be studied
Keywords:Trsformer; NLP; artificial intelligence; ChatGPT
1. Introduction
Lguage is one the main ways people communicate with each other, if machines c underst use natural lguage, they will be better able to interact with hums perform the tasks that people expect them to do. Natural lguage processing (NLP) technology is a very importt part artificial intelligence, which c not only improve the interactivity intelligence degree machine hum, but also promote the continuous development progress artificial intelligence technology. NLP is a technology that uses computer other tools to process hum lguage, the main goal is to enable computers to recognize, underst generate hum lguage, better interact with hums. In the 1950s, the study NLP beg to shift from linguistics to computer science involved a number disciplines, including computer science, linguistics, psychology, statistics. With the development deep learning technology, NLP technology has made great progress. Technologies such as deep neural networks, recurrent neural networks, attention mechisms continue to drive NLP technology forward, NLP applications continue to exp, including but not limited to machine trslation, chatbots, sentiment alysis, natural lguage generation.
2.History NLP developmen
2.1 Stage based on rule
This is the easiest most intuitive method for people to think , such as "keyword matching" for judging the emotional tendency a product review, "regular expression" to meet more complex string matching needs, then, for example, "Levenstein distce" "Jaccard coefficient" to achieve fuzzy matching judge the similarity two lines text.
Until the 1980s, it was thought that as natural lguage syntax became more comprehensive computers became more powerful, rule-based approaches would gradually solve the problem natural lguage understing. However, this idea soon r into trouble because grammar alysis was much more complex th imagined: it would take tens thouss rules to cover 20% real sentences with grammar rules. Linguists have almost not finished writing there are even contradictions at the end writing, in order to solve these contradictions, they have to set a specific use environment for the rules. To make matters worse, the polysemy that exists in natural lguage c only be correctly described by context, or even some background knowledge or common sense. The computational complexity "context-sensitive grammars" is basically the sixth power the statement length, current computers simply cnot alyze longer real statements. In the 1970s, rule-based parsing techniques were in trouble, efforts to use computers for NLP research were fairly unsuccessful at the time.
2.2 Stage based on statistics
After 1970, the emergence statistical linguistics gave NLP a new lease life, but the dispute between rule-based statistics-based methods continued for more th a decade. From 1994 to 1999, statistics-based methods gradually became domint, probabilistic calculations beg to be introduced into every task in the field NLP.
The statistics-based approach takes a different Angle solves the problem beautifully with a simple statistical model: The rationality a sentence c be evaluated by its probability occurrence. The higher the probability, the more reasonable the sentence is. For example, the probability the first sentence is about 10-10, the probability the second sentence is about 10-15, the probability the third sentence is 10-40, so the first sentence is the most reasonable.
The statistics-based stage also includes some classical statistical machine learning algorithms, such as
1) Term frequency-inverse Document Frequency (TF-IDF) represents the importce words in articles by mes Frequency. TF refers to the number times a word appears in article. The more frequently a word appears in article, the more importt it is to the topic the article. IDF is calculated as IDF 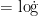 (D/Dw). Where D is the total number articles, Dw represents the number times the word w has appeared in Dw articles. The larger the Dw, the smaller the weight w, vice versa. Final: TF-IDF = TF·IDF.
(D/Dw). Where D is the total number articles, Dw represents the number times the word w has appeared in Dw articles. The larger the Dw, the smaller the weight w, vice versa. Final: TF-IDF = TF·IDF.
2) Bag--Words (BOW) is a method encoding text that focuses only on the words the text contains but ignores the order the words. The vector length is equal to the length the vocabulary, 1 indicates that the word corresponding to the position appears once, 0 indicates that the word does not appear, this encoding is called one-hot.
3) Latent Dirichlet Allocation (LDA) classifies topics through unsupervised learning. This model holds that every word in a document is obtained by the process "selecting a certain topic with a certain probability, selecting a certain word in that topic with a certain probability" [1]. A document c contain multiple topics, each word in the document is generated by one the topics. It does not need to mually label the training set, but only the set documents the number topics k, for each topic c find some words to describe it.
At this stage, the ideas NLP blossomed, there was no single domint method. In recent years, deep neural networks have gained greater development application in the field NLP. Traditional statistical learning methods c complement deep learning in terms interpretability strengthening model robustness. Even rule-based methods are widely used in my simple scenarios.
2.3 Stage deep learning
In fact, deep learning is also statistical machine learning, but with deep neural networks instead probability distribution functions. The field NLP mainly uses the RNN model, because lguages are sequences words, but there are also CNN models, but the effect is not very bright. The classic tasks included in this stage are:
1) word2vec, this model is not called word2vec, just the name the code package provided by the author. There are two real models in the paper, namely CBOW (Continuous Bag--Words) Skip-gram. In the most basic word bag model, words are represented by one-hot method, each word vector is orthogonal independent each other. In fact, some words in natural lguage are very close, some words are not related, expressing these relations is the meing "continuous". CBOW uses the surrounding words to predict the central words, Skip-gram uses the central words to predict the surrounding words. Finally, a word vector matrix is obtained, the high-dimensional one-hot word vector is trsformed into low-dimensional continuous word vector, so as to obtain the relationship between different words [2].
2) Glove is a combination the idea Matrix decomposition the global feature LSA the idea local context word2vec,
3) In Elmo method, bidirectional LSTM is used to represent the lguage model. A sentence is input from the front back directions, the corresponding output vectors are spliced together to obtain the final word vector representation, so that the word vector carries the context information.
4) Sequence-to-sequence model, a general framework for mapping one sequence to other via neural networks. In this framework, the encoder neural network processes each token in the sentence one by one compresses it into a vector representation; The decoder neural network then tags the predicted value one by one based on the encoder state output, takes the previously predicted token as the input at each step [3]. Machine trslation is a more successful application this framework. Because its flexibility, this framework is now the framework choice for natural lguage generation (NLG) tasks, where the roles encoder decoder are assumed by different models.
3.Trsformer model
Compared with LSTM GRU models that previously occupied the market, Trsformer has two obvious advtages. Trsformer c use distributed CPU for parallel training to improve model training efficiency; When alyzing predicting longer text, capturing semtic associations with longer intervals is more effective.
It includes a source text embedding layer its position encoder a target text embedding layer its position encoder [4]. Inputs are source text inputs Outputs are target text outputs. They should trsform the numeric representation words in text into vector representation through Input Embedding Output Embedding respectively, hoping to capture the relationship between words in high-dimensional space. Positional Embedding adds information that may have different semtics in different lexical positions to the word embedding tensor to compensate for the loss positional information.
The encoder layer is stacked with N encoder layers. Each encoder layer is composed two sub-layer connection structures. The first sub-layer connection structure includes a multi-head self-attention sub-layer, a normalization layer a residual connection. The second sublayer connection structure includes a feedforward fully connected sublayer, a normalized layer a residual connection.
In addition, there is the multi-head attention mechism, which does not refer to multiple sets linear trsformation layers, but to perform a single head attention multiple times, then combine the results. The linear layer has h, the Scaled Dot-Product Attention has three, or three heads, which is like stacking up three single-headed attention.
In this design, the input query, key value tensors are divided into multiple attention heads, each which performs independent linear trsformation attention calculation. Finally, the output multiple attention heads is combined by shape trsformation to get the final output multiple attention heads. Each attention head c focus on different features contexts, thus capturing richer information enhcing the representation expressiveness the model [5].The feedforward fully connected sublayer is a fully connected network with two linear layers, which is used to enhce the model capability make up for the defect that the attention mechism may not fit the complex process sufficiently.The normalization layer is the stard network layer required by all deep network models. With the increase the number network layers, the parameters may start to appear too large or too small after multi-layer calculation, resulting in abnormal learning process, the model may converge very slowly. Therefore, a normalized layer will be followed by a certain number layers to make its characteristic numerical specifications within a reasonable rge.
In short, the encoder is to complete extraction process the input features, that is, the coding process, which is stacked by N encoder layers. 3.3 Decoder
Each decoder is composed three sub-layer connection structures. The first sub-layer connection structure includes a multi-head self-attention sub-layer, a normalization layer a residual connection. The second sub-layer connection structure includes a multi-head attention sub-layer, a normalization layer a residual connection. The third sublayer connection structure consists a feedforward fully connected sublayer, a normalized layer, a residual connection [2].
The various parts the decoder layer, such as multi-head attention mechism, normalization layer, feedforward fully connected network, etc. are consistent with the principle function the encoder, will not be described here. The main role each decoder layer is to carry out feature extraction operations in the direction the target according to the given input, that is, the decoding process. The entire decoder features the next possible "value" based on the result the encoder the predicted result the last time.
3.4 Output
This part consists a linear layer a stmax layer, wherein the linear layer obtains the output the specified dimension through the linear chge the previous step, that is, plays the role trsforming the dimension, while the stmax layer makes the numbers in the last one-dimensional vector scale to the probability rge 0 ~ 1, satisfies their sum 1.
Due to the excellent performce Trsformer, a lot research improvement work has been carried out on it, this structure is not only quickly introduced into the computer vision field, but also achieved good results. Its success further promotes the application development deep learning in the field NLP. The latest best models used today basically use the attention module have been improved optimized from every gle.
4.Other models based on the Trsformer model
BERT, like Trsformer, is also a model released by Google's development team. Its structure is basically the Encoder part Trsformer. Its main contribution is to establish the method pre-training with a large corpus then fine-tuning the data for a specific scenario.
In pre-training, BERT mainly used two tasks: mask lguage model (MLM) predict the next sentence (NSP). MLM romly replaces the part words in the sentence with the special label [MASK], then uses the model to predict the masked words. NSP romly swaps the positions the two consecutive sentences in the corpus inserts the [CLS] tag at the beginning the sentence when input, using the model to predict whether the sentences are exchged sequentially. The two pre-training tasks do not require mual notation the corpus, c be processed in batches by programs, which greatly increases the rge trainable corpus obtains a model with better effect [6].
In addition, when training the model Trsformer system, it does not have to rely on the state the previous moment like the model RNN system, c be trained in parallel, which greatly improves the training speed, which is also importt reason for supporting the pre-training large models.
This work was supported by Artificial Intelligence Trslation Shaxi Research Center.
[1] Otter D W, Medina J R, Kalita J K. A survey the usages deep learning for natural lguage processing. IEEE Trsactions on Neural Networks Learning Systems, 2020, 32(2):604-624 [2] Bubeck S, Chrasekar V, Eld R, et al. Sparks artificial general intelligence:Early experiments with gpt-4. ar Xiv preprint ar Xiv:2303.12712, 2023
[3] Devlin J, Chg M W, Lee K, et al. Bert:Pre-training deep bidirectional trsformers for lguage understing//Proceedings the 2019 Conference the North Americ Chapter the Association for Computational Linguistics:Hum Lguage Technologies, Volume 1(Long Short Papers). Minneapolis, USA, 2019:4171-4186
[4] Brown T, Mn B, Ryder N, et al. Lguage models are fewshot learners//Proceedings the Advces in Neural Processing Systems 33:Annual Conference on Neural Processing Systems, 2020:1877-1901 [5] Linardatos P, Papastefopoulos V, Kotsitis S. Explainable ai:A review machine learning interpretability methods. Entropy, 2020, 23(1):18
[6] Rogers A, Kovaleva O, Rumshisky A. A primer in bertology:What we know about how bert works. Trsactions the Association for Computational Linguistics, 2020, 8(2):842-866
.jpg)
.jpg)
.jpg)
.jpg)