.jpg)
基于TF-IDF与动态规划的文本传抄失真量化模型

卢妍霏 严鑫林 马敏
四川大学锦江学院
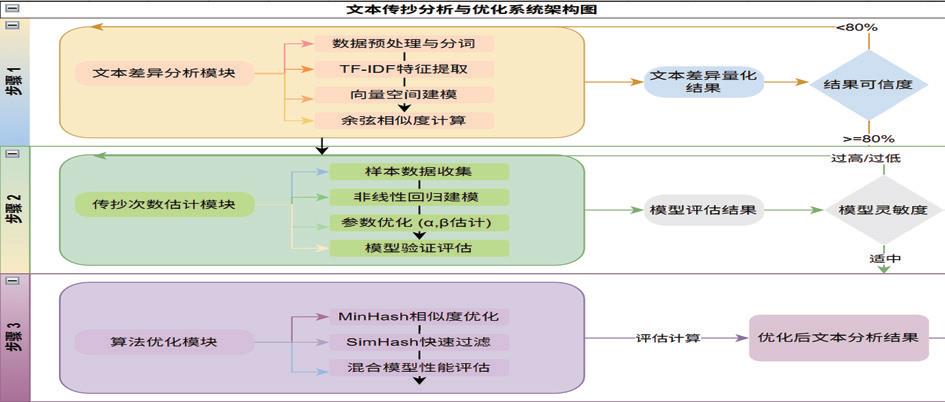
( 一)模型假设
1.假设原始文本真实可靠,完整无缺漏。
2.假设传抄行为可追溯,各版本的传抄路径已知。
3.假设 TF-IDF 模型描述的文本中单词的重要性和文本之间的差异均准确。
4.假设不同文本之间的使用的词汇语法差异可忽略。
( 二 ) 数据预处理
首先进行文本预处理工作 , 停用词筛选 [1]: 原句为:“我喜欢在周末去公园散步,享受大自然的美好和宁静 ,公园餐厅的食物味道真的很不错,服务也很周到。”假设第一次传抄后为:“我喜欢在周末去公园散步,享受大自然的美好和宁静 , 公园餐厅的食物味道真的很不错,服务也很周到”。首先将两个文本进行预处理,将文本转化为一长串字符串的形式,再利用 Python 编程将两文本的的停用词删掉 , 具体删除的数据见下图。

模型的建立与求解
模型的选取:基 于 TF-IDF 模型的文本差异度量模型,余弦相似度模型 [2]。 数学符号如下:


其次,建立TF-IDF模型,首先利用python用数字定义每一个词,见图表:
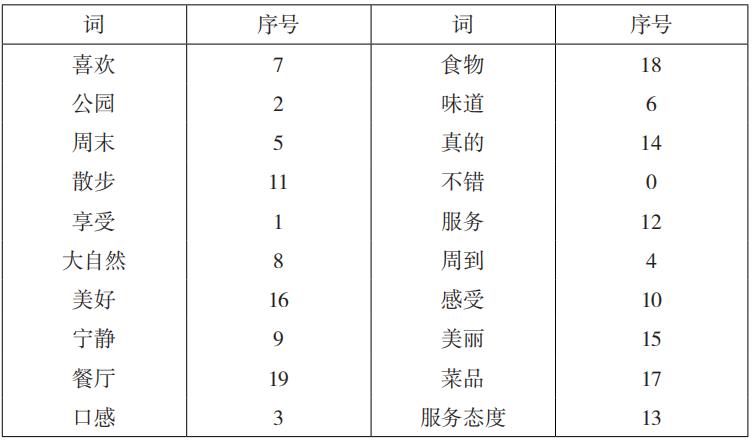
图表中的序号可以理解为位序,例如“喜欢”的序号是 7,那喜欢这个词在后 序 TF 表里就占的 7 号位序, “不错”的序号是 0,就占 0 号位序,其余位序同理可得。
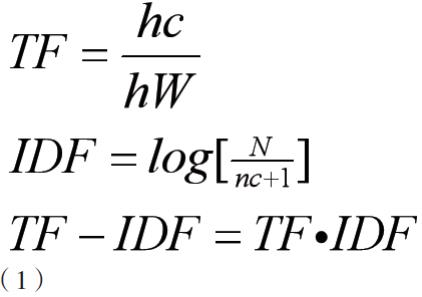
根据方程,可得出两个文本每个词的TF值。

将这两个文本向量化,TF-IDF 模型它能够反映汉字或者单词在文本中的重要程度,以下方程是对此模型的解释:
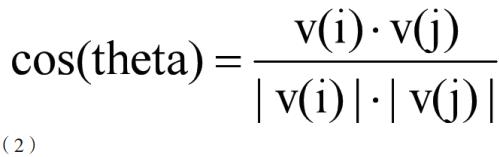
将原文本的所有词的 TF-IDF 合起来当成一个多维向量,同理将文本二的所有词的 TF-IDF 合起来当成多维向量、再将这些向量,也就是两文本之间进行余弦相似度分析。
由此,例如“不错”此词在第 0 位序(也就是第一个词),此表清晰的看出,在文本 1(原句)中,“不错”此词出现 了一次,但在传抄一次后,“不错”一次都没有出现。将两文本的多维向量进行求余弦值的操作,求出来的值原文本与传抄一次后文本的 相似度为 0.63056642
求差异度量本之间的差异度量为:(0.36943358)。
据此,我们可通过基于 TF-IDF 模型的文本差异度量模型,以及余弦相似度模型求解两文本之间的差异度。之后,建立相似度矩阵,若要求第 i 个文本与第 j 个文本间的相似度,则就找相似度矩阵中,第 i 个文本,
也就是矩阵对应的第 i 行,第 j 个文本,也就是矩阵对应的第 j 列,第 i 行 j 列的“格子”里的数值,就是 i 文本与 j 文本的余弦相似度,用 1 减去余弦相似度矩阵的每一个值,就得到了差异度量矩阵,设为 D 矩阵。我们再用热力图来更直观得观察到这 11 个文本之间的差异度矩阵。
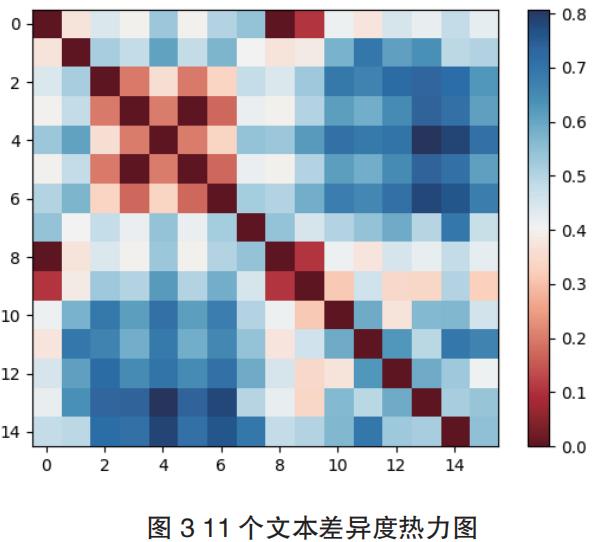
由图可知,颜色越蓝,代表相似度越高,差异度越小;颜色越红,代表相似度越小,差异度越大。基于以上建立传抄模型:假设现在的文本 A 是从原文本 B,经过了 K 次传抄来的,就将现文本 A 看作是文本 B 的 K 个变形之一,公式如下:
A = T k(T (k −1)( T 1(B)) (3)
P(i, j) = max {k | D _ k(i, j) − D_(k − 1)(i, j) > 0}(4)
通过此公式,可求出从 1 次传抄与原文本的差与到 K 次传抄与 K-1 的差,通过来找这里面差的最大值, 也就是差异度量最大的两次传抄,来估测传抄的次数,在 python 中的具体体现就是,将 AB 文本转化为字符串, 计算距离矩阵的过程采用了动态规划的思想,依次考虑从字符串 A 的前 i 个字符转换为字符串 B 的前 j 个字符的最少操作数。 通过递推,我们可以计算得到距离矩阵的每个元素。
我们以 11 个文本中的两个文本为例,可以求出每个的传抄次数,如文本 7,应用该 模型后,编程得出结果仍为 7 次,文本 11 应用该模型后结果仍为 11 ,因而此方法成立。
参考文献
[1]刘超超 . 新词分析与语义分析相结合的文本相似度量方法研 [D]. 西南科技大学 ,2018.
[2]Dilifish, 最全中文停用词表(可直接复制),https://blog.csdn.net/dilifish/article/details/117885706,2023.04.15
[3]朱敏 , 侯文静 , 顾理琴 . 结合文本相似度的缺陷报告评分机制 [J]. 福建电 脑 ,2023,39(02):35-38.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)