.jpg)
基于自编码器的慢病患者用药异常模式检测研究

叶金良 赵晓娟 余镕鑫 石勇 邹萱
湖南人文科技学院 417000
1. 引言
慢性病共病的情况在老年群体中较为常见,数据显示,我国 42% 的老年人同时患有两种及以上疾病,以高血压、糖尿病、冠心病、脑卒中、慢性呼吸系统疾病组合最为常见。多病共存不可避免多重用药,但是,多药联合治疗可能增加药物相互作用的机会,导致药物不良反应率增加。最近发表在《柳叶刀·精神病学》上的一篇综合性文报告了不同患者群体和地区抗精神病药物多药联用的流行程度和趋势。研究将抗精神病药物多药联用与不良反应风险的增加相关联,与单一抗精神病药物治疗相比,多药并用与复发风险增加、精神病住院率增加、整体功能下降以及不良事件增多相关。当前,针对慢病患者的多药联用风险,临床指南与既有研究多依赖于人工经验总结或基于规则的药物冲突数据库(如 DrugBank、LiverTox)进行风险预警。然而,面对动态变化的用药组合、复杂的药物 - 疾病 - 患者交互关系,传统方法在隐性风险模式挖掘与大规模用药方案筛查中面临显著局限:其一,人工规则难以覆盖非线性、高维的药物相互作用;其二,静态数据库无法实时适配个体化治疗场景中的动态变量(如肝肾功能波动、基因多态性)。为此,亟需引入智能化技术实现用药风险的主动感知与动态预警。本研究提出基于深度自编码器(Autoencoder)的用药异常检测框架,旨在从海量模拟用药数据中自动识别潜在风险模式(如重复用药、禁忌配伍、剂量冲突)。通过构建编码 - 解码网络,模型将学习用药方案的低维表征,并以重构误差为指标量化数据偏离正常分布的程度,从而定位异常用药组合,为临床提供可解释的风险预警依据。
2. 方法
尽管多药联用风险预警的智能化技术已取得一定进展,现有研究仍面临两大瓶颈:其一,真实临床数据的稀疏性与隐私限制导致模型训练样本不足;其二,多数算法依赖标注完备的异常样本,难以适配现实中未知风险模式的动态涌现。针对上述挑战,本研究聚焦于可控模拟环境下的用药异常检测方法验证,通过构建高仿真用药数据集与轻量化自编码架构,探索无监督学习在隐性风险感知中的泛化潜力。研究首先设计涵盖 5 类慢病药物的多维度模拟数据(如用药时序、健康指标动态关联),并嵌入两类可解释异常(重复用药与禁忌组合),以模拟真实场景中规则外风险。在此基础上,采用非稀疏自编码器提取药物组合的低维本质特征,通过重构误差的分布特性区分常规方案与潜在冲突,避免对先验标签的依赖。该方法不仅为有限真实数据条件下的风险预警模型开发提供了低成本验证路径,其轻量化设计亦可支撑临床实时决策场景的应用需求。下文将详细阐述数据生成逻辑、模型拓扑优化策略及异常判定的自适应阈值机制。
2.1 数据生成
为评估所提方法在慢性病用药监测中的有效性,本研究采用模拟数据生成策略构建了一个包含 1 000 条患者用药记录的虚拟数据集。具体生成流程如下:
1. 药物名称:从五种常见慢性病治疗药物(以下简称 A、B、C、D、E)中随机抽取,每条记录仅对应一种药物。药物分布按均匀分布随机赋值,以保证各药物出现频率大致相等。2. 用药时间:假定每日用药次数在 1–3 次之间,根据离散均匀分布为每位“患者”随机生成用药次数,并在同一日的 06:00-22:00 之间等距随机分配具体用药时刻。
3. 健康指标:对于血压,根据降压药 A、C、E 的药理作用,分别为“患者”生成收缩压和舒张压。其中,未服药时的基线血压按正态分布 N(140, 152 )/N(90,10 2 ) 生成;服药后血压在基线基础上按药物平均降幅(A: -10/-7 mmHg、C: -12/-8 mmHg、E: -8/- 5 mmHg)加上 ±5 mmHg 的小幅随机扰动。对于血糖值:对于降糖药 B、D,基线血糖值按N(8.0,1.5 2) mmol/L 生成;服药后血糖下降均值分别为 B: −1.2 mmol/L、D: -1.5mmol/L ,扰动范围 ±0.5mmol/L 。
4. 异常样本插入:为模拟临床数据中常见的异常情况,专门插入两类错误记录,第一类是重复用药,在同一“患者”同一日内,故意重复记录相同药物的多次用药条目,以模拟未识别的重复处方或记录错误;第二类是药物冲突,随机选取药物 C 与 D、或 B 与 E 的已知禁忌组合,在同一日同时出现,模拟潜在的不良药物相互作用。
5. 实现细节:数据生成脚本基于 Python(NumPy、Pandas)实现,并设定固定随机种子以保证结果可复现。全部生成步骤在预处理阶段完成,生成数据用于后续模型训练与评估。
2.2 模型构建
本文采用标准自编码器对药物组合数据进行无监督特征学习与异常检测。模型结构和训练流程描述如下。
首先,输入表示设计将五种候选药物的使用情况编码为 5 维二值向量 x∈{0,1} ,其中第 i 位为 1 表示该样本在该时刻使用了第 i 种药物,0 则表示未使用。模型网络结构主要包括两层:编码器(Encoder)和解码器(Decoder)。其中,编码器由全连接层组成,将输入层线性映射在隐藏层,激活函数选用 ReLU,隐层神经元数设置为 10 ;解码器同样采用全连接层将潜在表示映射回原始空间,激活函数选择 Sigmoid,用于输出 0–1 之间的重构概率。模型的损失函数设计为重构误差的均方误差(MSE)
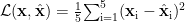
训练流程中设计了异常检测准则,即训练完成后,将每条样本的重构误差作为异常评分。通过在验证集上分析误差分布,选择合适阈值——当 ISE(x,x∧)>0.20 时,将该记录标记为异常。阈值的确定兼顾了漏报率与误报率,通过绘制 ROC 曲线并取 Youden's J 指数最大值对应的误差值。
3. 实验与结果
3.1 实验设置
1) 实验环境与工具
本实验在常规工作站(Intel i5 四核 CPU,16 GB RAM)上完成,无需 GPU 加速。所有代码均使用 Python 3.8 实现,深度学习框架采用 Keras 2.4.3(TensorFlow 2.3.0 后端)。依赖库还包括 NumPy、Pandas 和 Matplotlib。
2) 数据集划分
模拟数据集共计 1000 条患者用药记录,其中 80%(800 条)用于模型训练,20%(200条)用于测试评估。测试集中预先插入 10% 的异常样本(20 条),包括重复用药和药物冲突两类,以衡量模型的异常检测能力。
3) 模型训练
输入与批量采用 5 维 One-Hot 药物组合向量作为输入,批量大小设为 64。优化配置:使用 Adam 优化器,初始学习率 0.001 ;训练回合(Epoch)为 50 ;损失函数为重构均方误差(MSE)。使用 10% 验证集监控重构误差,如验证误差在连续 5 个 Epoch 内无改善,则提前停止。
4) 评价指标
本文的评价指标包括三个部分,一是对每条样本计算 MSE,即重构误差(ReconstructionError);二是设计检测阈值,即根据验证集误差分布,选取 Youden’s J 指数最高时对应的阈值(本实验取 0.20)作为异常判定的临界值;三是选择三个性能度量指标使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数评估异常检测效果。
3.2 实验结果
训练过程中模型的损失曲线如图 1 所示。可以看到,训练损失与验证损失在前 20 个epoch 内快速下降,并在 30 epoch 后趋于平稳,验证损失未出现明显过拟合。在测试集上计算所有样本的重构误差,并绘制柱状图,如图 2 所示。正常样本的误差集中在 0.05–0.15之间,而异常样本的误差主要分布在 0.20 以上,可清晰区分两类样本。
训练集和验证集损失
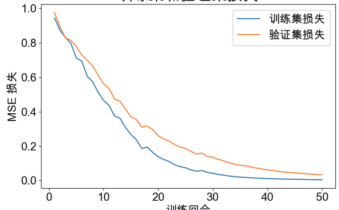
图1 训练/ 验证损失曲线
测试集重构误差分布
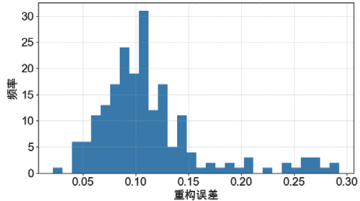
图2 测试集样本重构误差分布
表 1 展示了几条典型的异常检测结果,包括输入的药物组合、真实标签、重构误差以及模型判定。由表中可见,冲突用药组合 A+C (样本 105)和 B+D(样本 256)的重构误差分别为 0.28 和 0.31,远高于阈值 0.20,均被正确判定为异常;单纯使用药物 C(样本412)时误差仅 0.10,模型也准确识别为正常。对于重复用药案例 A(样本 589),重构误差 0.25 同样触发异常检测,说明自编码器能够有效区分正常用药与冲突或重复用药的异常模式。
表 1 异常检测典型样本

4. 系统应用
在项目系统中,可以将训练好的自编码器模型部署为一个实时服务,所有新增或修改的用药记录会通过 API 发往后端,由模型计算重构误差并判断是否异常。一旦检测到异常组合(如药物 C 与 D 同时使用),前端立即弹出预警窗口,提示用户“检测到药物 C 与 D可能冲突,请及时确认”;同时在用药记录列表中,以红色高亮标注该条记录,并在旁边显示“异常”标签。用户可点击预警窗口或列表中的“详情”按钮,查看冲突原因和建议操作(如咨询医师或调整用药方案)。整个流程要求低延迟、高可靠性:前端定时拉取或通过WebSocket 推送后端检测结果;后端则定期拉取最新记录或监听数据库变更,并在模型检测完成后立即推送。系统还会记录预警历史,用于后续审计和模型性能评估。
5. 结论与展望
自编码器作为一种无监督学习模型,能够自动从大规模模拟用药数据中提取潜在特征,并在不依赖人工预定义规则的前提下,精准识别出重复用药、药物冲突等异常模式。本文通过对药物组合的 One‐Hot 编码进行压缩重构,自编码器成功将正常用药模式映射到低维潜在空间,并对偏离该空间的异常样本产生显著较高的重构误差。实验结果表明,即使在仅有1000 条模拟记录、且未使用 GPU 加速的条件下,标准自编码器也能在训练时间和计算资源消耗方面保持极低开销,为慢病管理系统提供了一种低成本、高效能的异常检测解决方案。此外,自编码器不依赖于完备的药物交互数据库,避免了手工维护规则库的繁琐与易错特性。在实际部署时,可将模型嵌入到医疗应用或体检随访平台,实时监控患者用药记录,当检测到异常组合时,通过 APP 推送或医院内部告警系统及时提醒医护人员与患者,降低潜在用药风险。
展望未来,模型的鲁棒性和识别能力仍有进一步提升空间。一方面,可将自编码器与时序模型(如 LSTM、GRU)相结合,建模用药前后血压、血糖等指标的时间依赖关系,从而捕捉连续多天或阶段性用药行为中的微妙异常信号;另一方面,应考虑在模型输出基础上,灵活接入简单的药学规则库,对于已知的重大药物相互作用或剂量超标情况,二次校验并提供可解释性更强的预警提示。此种“数据驱动 + 规则驱动”混合策略,既保留了深度学习方法的自适应优势,又兼顾了临床药学的专业知识,为未来智能化慢病管理系统的安全性与可靠性提供坚实支撑。
参考文献:
[1] 黎艳娜 , 王艺桥 . 我国老年人慢性病共病现状及模式研究 [J]. 中国全科医学 ,2021, 24(31): 3955-3962.
[2] Højlund, Mikkel et al. Prevalence, correlates, tolerability-related outcomes, and efficacy-related outcomes of antipsychotic polypharmacy: a systematic review and meta-analysis[J]. The Lancet Psychiatry, 2024,11(12):975 - 989.
[3] Rumelhart, D. E., Hinton, G. E., & Williams, R. J.Learning internal representations by error propagation[J]. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition,1986,1:318–362.
[4] Baldi, P., & Hornik, K.. Neural networks and principal component analysis: Learning from examples without local minima[J]. Neural Networks,1989,2(1):53–58.
课题:2024 年度湖南省大学生创新训练 S202410553044
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)