.jpg)
基于迁移学习的中马神经机器翻译模型

韦松岳 蒋玉桂
广西民族大学 广西南宁 530000
中图分类号:TP3 文献标志码:A
引言
近几年,神经机器翻译(neural machine translation,NMT)模型相比于传统的机器翻译模型翻译效果上得到了很大的提高,并且在自然语言处理领域成为了主流的研究方向。NMT 通常使用编码器(encoder)-解码器(decoder)框架。例如,基于递归神经网络(RNN)的 NMT 模型[1-2]通常使用 RNN或其变体结构如长短期记忆模型循环神经网络(LSTM)模型[3],将连续的源句子编码成为向量,然后再将向量解码为连续的目标句子,这一类模型也被称为序列到序列(seq2seq)模型。seq2seq 通过上下文向量初始化解码器,并生成变化后的输出序列。
当前迁移学习是解决低语料资源的 NMT 性能较差的有效方法之一。Zoph[4]等将迁移学习应用于提高低资源 NMT 性能,通过在语料资源丰富的语言上训练得到的模型参数,用于对低语料资源的模型的参数进行初始化[4]。中马 NMT 属于典型的低语料资源的 NMT,可用的语料数据较为稀缺,而中英、英马的平行语料数据集存在较多,所以可使用迁移学习方法解决由于预料匮乏导致翻译性能较差的问题。
本文提出基于迁移学习的中马 NMT(NMT-CM)模型,通过迁移学习的思想融入中马 NMT 模型的训练。首先通过中英、英马平行语料数据分别训练编码器和解码器,将模型参数保存,而后将该参数载入中马神经机器翻译模型的编码器和解码器用于参数初始化,最后通过小规模的中马平行语料对该模型微调训练,提高中-马机器翻译的性能。本文训练采用 RNN、Bi-LSTM[5]模型与 Transformer[6]模型作为基本模型,其中 RNN 与 Bi-LSTM 模型采用传统注意力机制,在解码目标单词时有助于捕捉解码器局部联系性。而 Transformer 模型采用全局注意力机制,通过并行方式处理数据,能够更好地学习单词之间存在的依赖关系。
1 相关技术
1.1 迁移学习
迁移学习,即通过迁移在一个或多个源任务中学到的知识来改进传统机器学习,并使用它来改进相关目标任务中的学习[7]。迁移学习通过已有的丰富数据训练模型,并将模型学习到的参数权重迁移至数据匮乏的模型当中,以此来提高数据匮乏模型的性能。迁移学习属于机器学习中的一个分支。在本文中,中马 NMT 采用基于模型的迁移,又称基于参数迁移,即通过共享模型的权重与参数。基于参数迁移学习方法,具体为对源领域进行模型训练,保存性能好的模型参数,并将模型参数迁移至目标领域,目标领域再进行微调训练学习成新的模型。由于存在不常用语言平行语料资源缺少的问题,在没有足够的数据训练情况下,通过迁移学习的引入可有效缓解这一类问题。
1.2 结合迁移学习的神经机器翻译模型
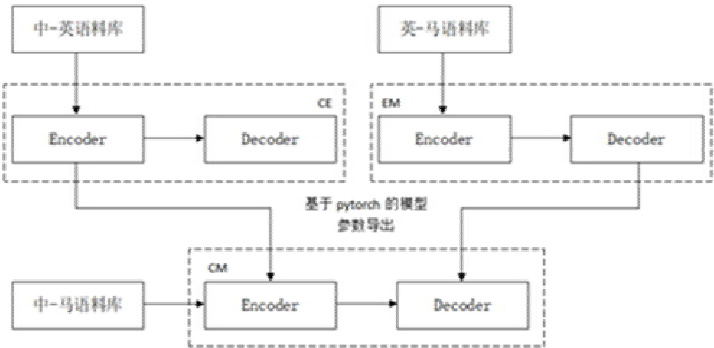
基于 seq2seq 模型通常包括以下几个步骤:在给定源句子在进入编码器前,为了能使用模型对文本进行分析,通过词嵌入法将句子转换成数字的词向量形式。编码器(encoder)将输入词向量序列压缩成指定长度的语义向量,解码器(decoder)则将由编码器得到的固定长度的向量再还原成对应的序列数据,解码器一般使用和编码器同样的结构。本文以不同 NMT 为基础模型进行训练,训练流程如图所示。首先通过大规模的中英平行语料与英马平行语料训练并保存两个预训练模型(CE 和 EM)。接着,使用中英模型的编码器参数初始化尚未开始训练的中马模型的编码器参数,使用英马模型的解码器参数初始化中马模型的解码器参数。最后,采用中马平行语料对已经初始化参数的模型进行微调训练,保存最优模型(CM)。
训练流程如图 3 所示,本文对中马机器翻译模型的 Encoder 和 Decoder 的参数,使用中-英机器翻译模型的中文端 Enocder 与英马机器翻译模型的马来语端 Decoder 的参数用于初始化,最后在使用中马平行语料进行训练。
图 1 中-马迁移学习训练流程图
2 实验结果分析
2.1 实验数据
中英平行语料数据集本文使用 Tatoeba 在线语料数据库,该中英数据集由 20 万对句子组成,我们将该数据集分成两个部分,分别用于训练(19.5 万个句子对)、和测试(0.5 万个句子对)。英马平行语料数据集我们使用了 OPUS 在线开源语料数据库,该数据集由 15 万对句子组成,分别用于训练(14.5 万个句子对)、和测试(0.5 万个句子对)。而中马平行语料数据集我们采用了来自 Tatoeba 和OPUS 数据库的数据集,其中 OPUS 数据库共有 7.5 万句子对,其中用于训练(7 万个句子对)、和测试(0.5 万个句子对)。Tatoeba 数据库共有 4 万句子对,其中用于训练(3.5 万个句子对)、和测试(0.5 万个句子对)。在训练前对数据集进行预处理(过滤乱码与分词),其中中文分词我们采用 jieba分词工具,英文分词采用 nltk 所提供的分词器,而马来语分词我们采用由 tensorflow 提供的马来西亚语的自然语言工具包库。本文通过两个自动指标来评估翻译结果:所有翻译结果不区分大小写的 BLEU评分与 METEOR 评分。BLEU 评分是机器翻译中广泛使用的独立语言度量标准,它核心思想是比较候选译文和参考译文里的 n-gram 的重合程度。Meteor 和 BLEU 不同,METEOR 同时考虑了基于整个语料库上的准确率和召回率,而最终得出测度。
2.2 实验结果分析
本文模式基于 Pytorch 框架对模型进行训练,并采用 BLEU 值与 Meteor 值作为模型测评指标。如表 1 给出的是基线模型与添加迁移学习模块在 Tatoeba 与 OPUS 数据库的中马语料上模型的测评对比值,其中 NMT-CM 为基于迁移学习的模型。
表 1 不同模型翻译结果对比
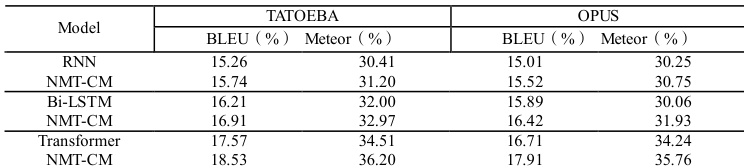
通过实验结果可看出基于迁移学习的 NMT 模型效果均优于基线模型。对于 Tatoeba 库的中马平行语料,NMT-CM 在 RNN 模型上 BLEU 值得到 0.48 个百分点提升,Meteor 值得到 0.79 个百分点提升。NMT-CM 在 OPUS 库的数据集上 BLEU 值得到 0.51 个百分点提升,Meteor 值得到 0.50 个百分点提升。NMT-CM 在 Bi-LSTM 模型上,BLEU 值得到 0.70 个百分点提升,Meteor 值得到 0.97 个百分点提升。在 OPUS 库的数据集上 NMT-CM 的 BLEU 值得到 0.53 个百分点提升,Meteor 值得到 1.87 个百分点提升。NMT-CM 在 Transformer 模型上,BLEU 值得到 0.96 个百分点提升,Meteor 值得到 1.69 个百分点提升。在 OPUS 库的数据集上 NMT-CM 的 BLEU 值得到 1.20 个百分点提升,Meteor 值得到 1.52 个百分点提升。
3 结语
目前在自然语言处理领域对于大语种的研究逐渐趋于成熟,如中英、英法等机器翻译,得到很好的效果。而对于如马来语、印尼语等小语种而言,目前所掌握的平行语料库资源较为匮乏,这也限制了中马机器翻译的发展。本文提出了 NMT-CM 的方法,即利用语料更为充足的中英和英马的数据集训练 NMT 的编码器与解码器,并利用中英 NMT 的编码器与英马 NMT 的解码器参数作为中马 NMT模型初始化参数,再通过小规模中马平行语料进行微调训练获得中马 NMT 模型。同时为了提高翻译效果,使用专门的马来语分词处理工具对语料进行更细致的预处理,一定程度上提高中马词向量的表达能力。通过该方法可提高语料数据匮乏的情况下中马 NMT 模型的性能,实验证明,引入迁移学习对中马机器翻译效果有一定的提升效果(BLEU 值与 Meteor 值)。
虽然迁移学习能够在一定程度上缓解该问题,但提升也较为有限,下一步的工作将考虑利用迁移学习结合生成对抗与强化学习的方式对中马神经机器翻译研究,进一步提高模型性能。
参 考 文 献
[1]Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio,
Y.(2014).Learning phrase representations using RNN encoder-decoder for statistical machine
translation.arXiv preprint arXiv:1406.1078. [2]Sutskever I, Vinyals O, Le Q V.Sequence to sequence learning with neural networks[C]//Advances in
neural information processing systems.2014: 3104-3112. [3]Hochreiter S, Schmidhuber J.Long short-term memory[J].Neural computation, 1997, 9(8):
1735-1780. [4]ZOPH B,YURET D,MAY J,et al.Transfer learning for low-resource neural []machine
translation[EB/OL].[2019-08-01].https : // arxiv.org/ pdf/1604.02201. 作者简介: 1、韦松岳,(1997),男,广西主要从事人工智能、自然语言处理研究。 2、蒋玉桂 (1997),男,广西主要从事人工智能,智能算法研究
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)