.jpg)
基于机器学习的诈骗网站检测模型研究

周荣垚 杨千芸 林楷 刘志民
重庆科技大学计算机科学与工程学院重庆401331
Abstract:In recent years, online fraud has become increasingly rampant, and it is not uncommon for fraudsters to commit fraud by building risky websites such as gambling, brushing orders, and loans. Since the majority of the public lack the ability to effectively identify fraudulent websites, this poses a serious threat to personal information and property security. Therefore, it is urgent to design an efficient and accurate fraud website detection model. A fraud website detection model is proposed based on extracting basic features from URLs and integrating four machine learning algorithms: decision tree, random forest, SVM, and AdaBoost. By integrating the advantages of different algorithms, a detection system covering feature screening and pattern recognition is constructed to accurately identify fraudulent websites and help users prevent online fraud.
Key words: Fraudulent websites, Website detection, Machine learning, Feature fusion
1引言
随着互联网的不断发展,网络诈骗日益猖獗,一些不法分子通过搭建博彩、刷单、贷款等风险网站实行诈骗。由于绝大部分民众缺乏对于诈骗网站的辨别性,对涉诈网址进行访问并且在其中进行消费,被诈骗网站团伙盯上,从而被骗走钱财和银行卡信息导致不可估量的财产损失。
2024 年6 月25 日公安部公布十大高发电信网络诈骗类型。数据显示,刷单返利、虚假网络投资理财、虚假购物服务、冒充电商物流客服、虚假征信等10 种常见的电信网络诈骗类型发案占比近 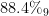 。其中,刷单返利诈骗不仅发案数量居于首位,同时也是造成经济损失最为严重的诈骗形式。虚假网络投资理财类案件虽然发案量相对较少,但单案涉案金额普遍较高。虚假购物服务类诈骗案件数量增长显著,目前已经上升到第三位。其他常见诈骗类型还包括冒充电商物流客服、虚假征信等[1]。为满足民众和公安部门等的反诈需求,准确识别诈骗网站,对预防各类诈骗和信息泄露具有重要的现实意义。
。其中,刷单返利诈骗不仅发案数量居于首位,同时也是造成经济损失最为严重的诈骗形式。虚假网络投资理财类案件虽然发案量相对较少,但单案涉案金额普遍较高。虚假购物服务类诈骗案件数量增长显著,目前已经上升到第三位。其他常见诈骗类型还包括冒充电商物流客服、虚假征信等[1]。为满足民众和公安部门等的反诈需求,准确识别诈骗网站,对预防各类诈骗和信息泄露具有重要的现实意义。
2电信诈骗网站特征
2.1 刷单返利类诈骗网站特征
络刷单返利类诈骗正逐渐演变为变种频次高、迭代速度快的主要诈骗类型,其不仅是虚假投资理财、贷款等复合型诈骗的核心引流手段,也成为网络赌博、网络色情等违法犯罪活动的重要获客途径[2],是发案量最大和造成损失最多的诈骗类型。其本质是利用“低成本高回报” 的心理诱饵,通过伪造虚假交易场景实施诈骗。这类诈骗网站通常具有3 种典型特征:(1)以极低的加入门槛和极高的返利或佣金吸引受害者,初期进行小额返利降低受害者的防备心;(2)当受害者尝试金额更大的任务时,网站要求用户先垫付资金才能完成任务;(3)用户想要提现时,网站会以操作失误、账户被冻结等多种理由搪塞用户,并且诱骗用户继续进行大额转账。
2.2 虚假网络投资理财类诈骗网站特征
虚假网络投资理财类诈骗是电信网络诈骗中个案损失金额最大的类型,诈骗分子通过伪造“高收益、低风险”的投资场景,用虚假网站诱导受害人投入资金[3]。这类诈骗网站一般具有 3 种特征:(1)诈骗分子通过社交平台、短信等发布虚假投资信息,用“保本高息”的虚假宣传吸引受害者;(2)诈骗分子冒充理财导师、股票分析师等专业人士,通过社交平台授课,向受害者灌输投资经验,进一步获得受害者的信任;(3)伪造投资平台,向消费者发送虚假链接,诱导消费者登录网站进行投资,用小额返利做诱饵,制造时间紧迫感以及资源稀缺感,不断引导消费者加大资金投入。这类诈骗严重扰乱金融市场秩序,削弱人们对合法投资的信任,让人们对真正合规的投资产生怀疑。
2.3 虚假购物服务类诈骗网站特征
随着互联网的不断发展,网络购物越来越方便,网购用户也不断增多,虚假购物服务类诈骗发案量也明显上升。诈骗分子用“超低价好物”、“跨境直邮”等做诱饵,伪造消费场景和交易信任链,引诱受害者掉进购物陷阱。这类诈骗网站通常具有2 种特征:(1)诈骗分子通过各种渠道发布“打折优惠”、“海外代购”等有吸引力的商品信息,配上伪造的商品实拍图,吸引受害者主动联系;(2)诈骗分子搭建和正规平台一样的虚假网站,让受害人提供银行卡号或者进行转账汇款,用“已发货”等虚假进度拖延时间。当受害者要求退款时,他们会用各种理由拒绝,甚至引诱受害者二次转账解冻账户。
3诈骗网站检测模型
设计的诈骗网站检测模型包含数据预处理、WHOIS 特征提取、单词级特征提取、字符级特征提取、特征输出等步骤。模型总体架构如图1 所示。

3.1 特征提取
3.1.1 数据预处理
设计的模型在检测中融合了URL 特征信息、WHOIS 特征信息、文本特征信息。其中,后两项特征信息需要在线从被探测网站获得,因而,模型需要首先对输入的URL 信息进行预处理,判断URL 是否存活。如URL处于存活状态,则进行WHOIS 特征信息、文本特征信息的提取,否则只依据URL 信息信息判别。
3.1.2WHOIS 特征提取
提取 WHOIS 特征时,用 python 的 whois.whois(url)函数获取包含 WHOIS 信息的字典,通过 key 提取字典中需要的信息--creation_date,通过与2024-12-31 日期的运算得到创建以来的存在时间是否超过半年,以及for 循环遍历字典得到有效信息的条数,作为WHOIS 特征。
3.1.3 单词级特征提取
在提取单词级特征时设计了Embedding_word 函数,首先初始化了 tokenizer 和 BERT 的预训练模型,然后先用 tokenizer 对 URL 进行分词,用 tokenizer.convert_tokens _to_ids 转换成 ids 后,将 ids 转成 tensor 类型输入到BERT 模型中,得到12 个隐藏层,对最后 4 个隐藏层求和得到一个高维词向量矩阵。利用nn.Linear 全连接层对高维词向量矩阵进行降维,得到一个低维词向量矩阵。
3.1.4 字符级特征提取
提取字符级特征时设计了Embedding_char 函数,主要是逐字符访问URL,统计字频后用sorted 函数排序,进行编号,然后设定一个最大长度后,对URL 进行重编码。接着用 Embedding 层对 URL 进行独热编码、字符嵌入,并同时将稀疏矩阵进行降维得到稠密矩阵。
3.1.5 深度特征提取
将字符级特征的稠密矩阵和单词级特征的低维词向量矩阵分别输入TextCNN 中进一步聚合,提高特征的表征能力,TextCNN 中共包含了3 个不同的卷积运算,卷积核大小分别为2,3,4,特征矩阵分别进行三个卷积运算后,用Relu 激活后,用最大池化Maxpool1d 降维后,将三个经过卷积、激活、池化后的结果用 torch.hstack 进行拼接,再用nn.Flatten 展平,降维后输出,即得到最终的字符级特征矩阵和单词级特征矩阵。
3.2 特征判别
将提取的特征输入模型进行判别,采用多分类任务识别每一个特征的分类。这里采用了四个模型,然后采用加权赋分方式进行最终判别。
3.2.1 决策树
通过调用python 中的scikit-learn 库中的决策树分类器来实现决策树算法。选择信息增益的方式进行分类,可以确保每次划分都能最大程度地减少数据集的混乱度,从而提高分类效果。使用GridSearch 网格搜索法,选择最优参数,评估器 estimator 为 DecisionTreeClassifer。
3.2.2 随机森林
调用scikit-learn 机器学习算法集成库的随机森林分类器,使用网格搜索法选择最优参数协助完成随机森林的选择特征。评估器 estimator 为 RandomForestClassifer,通过 fit 函数拟合训练集后输出最优分类器,再输入测试集url 和测试集label 测试最终效果。
3.2.3SVM
通过调用 scikit-learn 库中的 SVM.SVC 分类器,并通过 GridSearch 网格搜索法来选择最优参数,进而更好的实现随机森林分类这一功能。通过参数字典garam_dict 来设置网格搜索的范围,以GridSearchCV 定义网格搜索器,调用fit 函数拟合训练集后输出最优分类器。
3.2.4AdaBoost
通过调用scikit-learn 集成库中的Adaboost 分类器,自适应调整权重提升分类准确性。
4模型测试
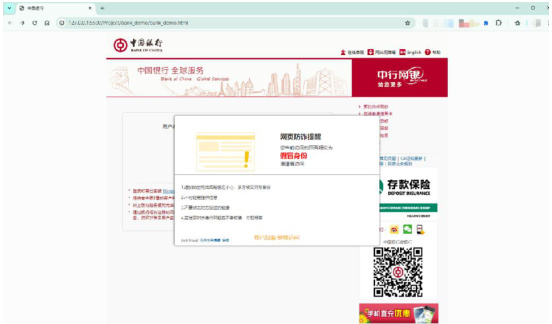
在Chrome 浏览器上安装诈骗网站检测模型插件,然后输入恶意网站的网址进行测试。测试结果如图2 所示。该模型能正确检测恶意网站,并弹出提示信息帮助用户快速识别。
5结束语
通过分析不同诈骗网站特征,设计了一种高效、准确的诈骗网址检测模型。该模型通过对网站数据进行全面的特征提取,包括URL 的字符级、单词级以及WHOIS 等多方面信息,结合TextCNN 网络聚合特征,有效捕捉网站中的潜在风险信号。整合决策树、随机森林、SVM、AdaBoost 四种机器学习算法,构建起多算法联合决策机制,攻克传统单一算法在诈骗网址检测中的局限性。实验结果表明,该模型具有较好的准确行,能帮助用户辨别诈骗网站。
参考文献:
[1]中华人民共和国公安部. 公安部公布十大高发电信网络诈骗类型[EB/OL]. https://www.mps.gov.cn/n2253534/n2253535/c9629527/content.html.
[2]彭景晖.打好反电诈持久战守护群众“钱袋子”[N].光明日报,2024-07-20(005).
[3]刘永灵. 基于生成对抗网络的信用卡交易欺诈检测[J]. 现代商贸工业. 2024 ,45 (17): 266-268.
.jpg)
.jpg)
.jpg)
.jpg)