.jpg)
基于深度学习的中文语法纠错方法研究

王辉 潘俊辉 王浩畅 张强 李荟
(东北石油大学 计算机与信息技术学院 黑龙江 大庆 163318)
1 引言
中文语法纠错作为自然语言处理领域极其复杂的任务之一,近些年的研究效果也始终提升不高[1]。每年举办的中文语法错误诊断比赛(Chinese Grammatical Error Diagnosis,CGED)[2]比赛虽然不断刷新中文语法纠错的效果,然而实际场景中往往很难从批量的文本数据中标识准确的错误文本及给出修改意见。同时,CGED 为研究者提供了大量的标注数据,最初的文本纠错以拼写纠错为主,也多采用基于统计语言模型的方法[3]。而后随着深度学习的兴起,神经网络模型也逐渐作为构建中文语法纠错的基本架构,取得了相比于以前更好的效果。鉴于此,本文在对 NLPCC 2018 GEC 和中文维基语料数据集预处理的基础上,建立了多通道融合中文文本修正模型,旨在更精准地捕捉和纠正中文文本中的复杂错误。
2 实验数据采集与预处理
2.1 NLPCC 2018 GEC 训练集和数据处理
NLPCC 2018 GEC 训练集来自于 NLPCC 2018 GEC 共享任务测评。针对每一项原始文本输入,其校对信息展现为单行形式。如果初始文本无误,则该行可包含零个元素,其余情况则包括单一修正后的句子,或是多个并列的修正句案例;构成每一行的是四个通过制表符分隔的区域,每一个区域表示特定的含义。
对NLPCC 2018 GEC 的训练数据进行预处理,主要由以下步骤组成:
(1)去除原训练资料中的重复线。
(2)消除 NLPCC 中的空白部分。
(3)将原形式的训练样本转换成并行的语句对。
(4)当 num_correct 域为 0 时,将产生一个与源端相等的语句对,通过试验证明,添加一个恒等映射可以提高系统的性能。
(5)基于目标语句的数量产生多个并行对,以解决直接语句与纠错语句数量不一致的问题。
(6)如果译文语句中含有“无需修正”这一词语,那么将产生译文语句对,该语句的译文与源语句相等。
(7)汉字,英文字母,数字,中英两种标点符号都不能使用,其它不合法的符号也不能使用。
(8)将繁体中文转换成简体中文。
(9)通过利用jieba 分割工具对切分粒度进行控制,或将其分割成单词序列。
(10)将产生的并联句对中的重复行删除
2.2 维基百科中文语料与预处理
本文从维基网站下载中文维基百科语料,XML 文件中的 text 标签内部即为文章内容,需对其进行必要的处理与清洗,主要包括:
(1)对中文维基百科语料实现XML 和 json 格式的转换。
(2)对 json 字符串进行解析,并从中抽取出词汇名称和内容(3)对汉字,英文字母,数字,中文标点,其它不合法的标志,一律予以删除。
(4)繁体中文转换成简体中文。
(5)通过利用 jieba 分割工具对单词进行切分或者分割成单词的顺序,来控制切分粒度。
处理中文维基语料,指定切分等级为字即可,处理完的维基语料用于训练中文字向量和字级别的语言模型。
3 基于深度学习的中文语法纠错模型构建
3.1 错误词检测器(Detector)
当进行错词检测的时候,先拿到实例化后的对象,然后调用 detect 类方法进行检测。detect 类方法中,入参为待检测文本,然后将依次序进行如下处理:1.空字符判断;2.初始化;3.编码统一;4.文本归一化;5.长句切分为短句。对于每个短句进行错词检测,
依次对短文本进行错词搜索。与词层面相比,字级别检索无需进行词语分割,直接处理。最终,综合三种情况构建候选集,若属于自定义的混淆集内,直接修改为正确值。
在词与字场景内,如果缺少正确值,参考模型从候选集中筛选。
3.2 KenLM 模型
Kenlm 模型需要在 Linux 环境下进行配置和训练。更新 Boost 和 zlib 软件包至 1.36.0版本,更新 gcc 版本需要是 4.8.2 及以上。在 Linux 环境下前往 KenLM 官网下载KenLM.tar.gz 工具包,在相应路径下解压工具包,并进行编译。再将模型压缩保存为二进制,方便模型快速加载。当 n 值增大时,为下一个词的出现提供了更丰富的上下文约束信息和更强的区分能力,然而这会导致数据变得更加稀疏,且n 元模型的总数急剧增长至 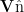 (其中 V 代表词汇表的容量),使得计算复杂度增加;相反,若n 值减小,则模型在训练语料中出现的频率更高,统计结果更为稳定可靠,但牺牲了上下文的约束性和辨识度。本文由于数据量足够大,因此将 n 设置为 5,会牺牲训练时间和系数程度以达到更准确的判别效果。
(其中 V 代表词汇表的容量),使得计算复杂度增加;相反,若n 值减小,则模型在训练语料中出现的频率更高,统计结果更为稳定可靠,但牺牲了上下文的约束性和辨识度。本文由于数据量足够大,因此将 n 设置为 5,会牺牲训练时间和系数程度以达到更准确的判别效果。
3.3 seq2seq 模型
本项目以 ConvSeqtoSeq 为基础,建立了中文校正模型,并对基线模型进行了详细设定。
(1)输入端与输出端的词嵌入维度均设置为 500,而解码器的输出层次也设置成500 以获取更多的词汇。
(2)构建包含7 层编码层和7 层解码层的深层网络,每层的隐藏状态维度为1024,增强模型的表达能力。此外,采用宽度为3 的卷积窗口来提取局部特征。
(3)采用 Nesterov Accelerated Gradient(NAG)优化算法,其动量参数设定为 0.99,初始学习率为0.25,并以 0.1 的比例逐步衰减学习率,以平衡学习速度与收敛精度。
(4)设置梯度裁剪阈值为 0.1,防止训练过程中梯度爆炸问题。
(5)每个训练批次最大包含 60 个句子。
(6)词嵌入矩阵采用随机初始化方式。统一设定随机数种子为1。
4 实验结果对比与分析
虽然 KenLM 语言模型在训练维基百科中文语料时所需的时间较短,但在 NLPCC2018 GEC 语料数据上的句级别预测效果并不理想。KenLM 的准确率(acc)为0.5409,虽然精确率(precision)较高,达到了 0.6532,但召回率(recall)仅为 0.1492,导致F1 得分偏低,仅为 0.2429。这表明 KenLM 在预测句子时,虽然能较准确地预测出部分正确结果,但遗漏了许多应该预测出的正确句子。相比之下,seq2seq 模型的训练时间较长,但它在句级别预测效果上表现更佳。尽管其准确率和精确率低于 KenLM,但其召回率与 KenLM 相同,均为 0.1492,且 F1 得分达到了 0.1947,高于 KenLM。这说明seq2seq 模型在预测时能更好地覆盖所有可能的正确句子,尽管其中可能包含一些误报。因此,虽然 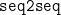 的训练时间较长,但其更全面的预测能力使得它在某些场景下可能更为适用。
的训练时间较长,但其更全面的预测能力使得它在某些场景下可能更为适用。
4 结束语
本文聚焦于中文文本的拼写检查和语法检查两大核心,深入探讨了这两个任务的理论框架与实践方法,为后续语法错误诊断任务的研究奠定了坚实的基础。在未来的工作中,将进一步研究预训练和真实的语法错误分布不完全一致问题,考虑如何构建更大规模的训练集,使用数据增强方法,提高平行语料的数据质量,从而显著提升模型性能。
参考文献
[1]陈婉玉.面向视觉处理的 Transformer 模型压缩算法研究及实现[D].北京邮电大学,2023.
[2]王海.基于深度学习的中文语法错误诊断研究[D].辽宁科技大学,2022.
[3]高印权.基于深度学习的文本语法自动纠错模型研究与实现[D]:硕士学位论文.电子科技大学,2020.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)