.jpg)
基于人工智能的Python试题推荐系统设计研究

安益良
身份证号:410222198907190036
0 引言
本文旨在设计一个智能化的 Python 试题推荐系统。该系统通过构建学习者画像与试题画像,结合多种 AI算法,为不同层次的学习者提供自适应的练习路径,旨在提升学习效率、巩固知识体系,并最终实现因材施教的教育目标。
1 系统整体设计
1.1 系统架构设计
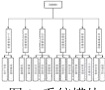
本系统采用四层架构,数据采集层通过MySQL 关系数据库实现用户信息、试题元数据及知识点拓扑的结构化存储,并借助 Redis 缓存数据库支持实时行为日志存取;智能算法层依托特征工程提取题目语义特征与学习者行为模式,结合协同过滤(CF)与内容推荐(CB)混合算法构建学习者能力画像及试题动态匹配模型;业务服务层基于Django 完成推荐计算、权限校验和数据传输等核心业务逻辑;显示交互层运用Vue 框架开发自适应前端界面,通过可视化组件实现试题推荐列表呈现、答题结果反馈及学习路径生成。系统架构设计,如下图所示。

图1 系统层级架构
1.2 功能模块设计
Python 试题推荐系统中,个人信息模块提供用户注册认证、资料动态维护及基于角色的权限控制;试题管理模块构建标准化试题资源库,支持多级知识点标签体系(如"数据结构/算法分析")及动态难度分级机制;行为采集模块基于事件驱动架构实时捕获用户交互数据,包括答题正确率、收藏偏好、页面停留时长等行为指标;画像构建模块运用增量学习算法,根据用户行为序列动态更新知识掌握度热力图与多维能力模型;智能推荐模块采用混合推荐策略,结合协同过滤与内容特征匹配,实时生成符合用户当前能力水平的个性化试题列表。
图2 系统模块
2 核心技术
2.1 核心算法流程
首先,系统依据存储的用户行为日志判定学习者是否为首次使用:若为首次使用,系统将启动基于学习者画像的内容型推荐(CB),通过匹配学习者注册阶段填写的 Python 学习兴趣标签(如 “Python 基础语法”“数据结构与算法”“Web 开发”)与初始测试映射的能力水平(如 “入门级”“进阶级”“精通级”),筛选出兴趣与难度双重适配的 Python 试题;若为非首次使用(存在历史行为数据),则采用协同过滤(CF)与内容型推荐(CB)的融合算法,一方面通过余弦相似度挖掘具有相似 Python 答题行为(如正确率、答题时长、错题类型)的用户群体偏好,提取群体验证的优质试题,另一方面基于 Python 试题画像(知识点模块、难度系数、题型)计算与学习者历史需求的相似度,筛选特征匹配的试题。随后,系统根据使用状态动态分配权重排序,最终按排序结果生成前 N 道题(默认 N=10)的 Python 试题推荐列表,实现 Python 学习场景下个性化与实用性兼具的试题推荐。
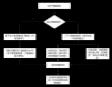
图3 核心算法流程
2.2 学习者画像与试题画像构建
学习者画像是系统实现个性化推荐服务的核心基础,主要涵盖三方面关键特征:一是知识图谱,系统构建以Python 知识点为节点、以知识点间 谱, 同时为每个用户生成专属知识掌握度向量,其中可用向量的元素代表用户对知 答题 正确率、答题时长、提交次数等交互行为动态计算更新,精准反映用 从 Pytho 学习的核心能力维度出发,综合评估用户的语法理解能力、算法应用能力、 率优化能力, 形成多维度能力评估矩阵;三是偏好特征,聚焦用户学习习惯,记录并分析其偏好的试题难度、题型及试题来源,为推荐内容适配性提供依据。
试题画像则围绕Python 试题内容与使用数据构建多维度特征体系,实现试题的精准描述与匹配:在内容征层面,从Python 试题的题干、选项及代码示例中提取关键词向量,捕捉试题的核心考查内容;在元数据特征层面,通过人工标注与规则匹配相结合的方式,明确试题所属Python 知识点模块、预设难度系数、题型分类及出题时间,形成标准化试题属性;在统计特征层面,基于系统历史使用数据,计算试题的历史答题正确率、平均答题时长及错误率较高的答题步骤,为后续推荐时的试题优先级排序与用户能力适配提供数据支撑。
2.3 混合推荐模型
为克服单一算法的局限性,系统采用混合推荐策略,系统采用三种协同互补的推荐算法策略,以适配不同用户场景与需求:基于内容的推荐(CB)适用于冷启动场景,核心是计算用户已练习 Python 试题的画像与候选试题画像的余弦相似度,筛选并推荐内容相似的试题;协同过滤推荐(CF)采用基于模型的 ALS 算法,先将用户 - 试题评分矩阵分解为用户隐因子矩阵和试题隐因子矩阵,再通过矩阵运算预测用户对未做 Python 试题的评分,进而推荐符合用户潜在需求的试题,助力用户发现尚未察觉的兴趣方向;最终推荐列表采用混合策略生成,通过权重融合两种算法的结果,其中权重参数会根据用户类型动态调整, 新用户因缺乏充足历史行为数据,侧重赋予基于内容推荐更高权重以保障基础适配性;老用户因积累了丰富的 Python 答题与交互数据,侧重赋予协同过滤推荐更高权重以挖掘潜在兴趣,从而平衡推荐结果的适配性与多样性。
3 系统实现
3.1 系统实现的技术
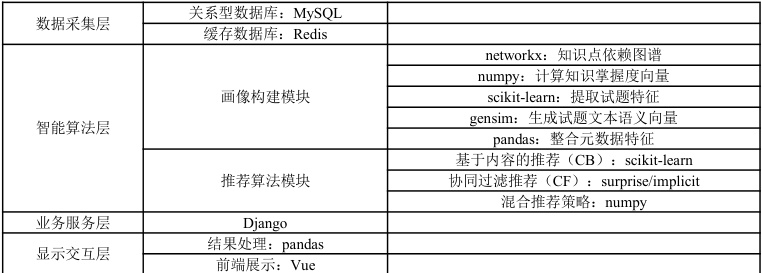
数据采集层通过用户行为数据(答题记录、收藏、停留时长)与试题基础数据(题干、知识点分类、题型)构建推荐基础,经清洗预处理后输入画像层,技术上常用 MySQL 与 Redis 实现数据存储;智能算法层先构建学习者画像(基于 networkx 构建 Python 知识点图谱,numpy 计算知识掌握度向量,pandas 生成能力模型与偏好特征)和试题画像(scikit-learn 提取 TF-IDF 特征、gensim 生成 Word2Vec 语义向量,pandas 整合元数据与统计特征),再通过 CB 算法(scikit-learn 计算余弦相似度适配冷启动)、CF 算法(surprise/implicit 实现ALS 挖掘潜在兴趣)及动态权重混合策略(numpy 加权融合)生成推荐;业务服务层采用 Python 的 Django 框架,以 MVT 架构为逻辑中枢,衔接前后端与数据存储,支撑系统业务运转。
表1 系统实现的技术
4 系统评估
对系统的评估主要有两方面,一是对系统本身性能等方面的评估, 是用户使用软件的效果进行评估。对系统本身性能等方面的评估可以对一 些性能指标进行检验,比如需 达到 B 冷启动场景相似度匹配率≥85%、CF 潜在兴趣挖掘准确率 ⩾80% 推荐 并发承载 ⩾100 ySQL 查询延迟 ⩽ 100ms 等标准。对软件使用效果的评估可以做对比实验,比如,为评估系统性能, 可邀请若干名具有不同Python 水平的学习者进行为期两周的试用。将用户随机分为两组:A 组使用系统的推荐功能进行练习,B 组自行在题库中选择题库练习。后测与前测之差作为教育效果的评价指标。
5 结语
本文设计并实现了一个基于人工智能的Python 试题个性化推荐系统。该系统通过构建学习者画像和试题画像,有效融合了基于内容与协同过滤的推荐算法,解决学习编程开辟了一条途径。
参考文献
[1]王峰,张旭阳.人工智能在高校体育教学中的应用探讨[J].文体用品与科技,2025,(13):173-176.
[2] 付 成 芳. 基 于 知识 图 谱 的 自适 应 学 习 推荐 系 统 的 构建 与 应 用 [J]. 湖 北 开放 职 业 学 院学报,2025,38(12):160-163.
[3]李博,莫先.大语言模型在推荐系统中的应用[J].计算机科学,2025,52(S1):19-25.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)