.jpg)
基于人工智能的混凝土强度早期预测模型构建与验证

颜碧雪 夏小兵
海南工商职业学院 海南海口 570203;中洲建为(海南)工程技术有限公司 海南海口 570203
引言
混凝土作为建筑工程的核心材料,其强度的早期预测对工程安全与施工管理至关重要。传统的强度检测方法通常需较长养护时间,难以满足现代工程对快速反馈的需求。随着人工智能技术的快速发展,基于数据驱动的预测模型展现出强大的学习能力和泛化性能,能够有效捕捉混凝土强度与其成分及环境因素之间的复杂关系。引入人工智能进行混凝土强度的早期预测,不仅提高了预测效率,还为施工现场的实时决策提供了科学依据,推动了建筑材料检测技术的创新与进步。
1 混凝土强度早期预测的现状与挑战分析
混凝土强度的早期预测作为建筑工程质量控制中的关键环节,长期以来一直是土木工程领域的研究热点。传统的强度评估主要依赖于标准养护期后的物理检测方法,如抗压强度试验,这些方法虽然准确但耗时较长,无法满足现代施工过程中对快速反馈的需求。混凝土在早期养护阶段的物理性能受多种因素影响,包括水胶比、掺合料种类、养护温湿度条件等,其内在的非线性关系使得预测变得复杂。实际工程中混凝土配比的多样性和环境条件的变化进一步增加了强度预测的难度,使得传统基于经验公式或线性回归的方法难以实现高精度的早期强度预测。
随着信息技术的发展,尤其是人工智能和大数据技术的兴起,为混凝土强度早期预测提供了新的思路。人工智能通过深度学习、支持向量机、随机森林等机器学习算法,能够从大量实验数据中提取隐藏的特征,建立更加精准的预测模型。这些方法克服了传统统计学方法在处理高维非线性数据时的局限,具备更强的自适应能力和泛化性能。人工智能模型的构建也面临诸多挑战。数据的质量和数量直接影响模型的训练效果,而混凝土强度数据通常受实验条件限制且样本分布不均匀,导致模型在实际应用中的鲁棒性不足。如何选择合适的特征参数和优化模型结构以避免过拟合,提升模型的解释性
和实用性,仍是研究的难点。
混凝土强度早期预测的实际应用还需兼顾模型的计算效率与现场操作的便利性。复杂的深度学习模型虽然在精度上表现优异,但往往计算量大,难以快速反馈现场结果,限制了其实时应用的可能性。工程现场环境复杂多变,模型需要具备一定的抗干扰能力,能够适应不同配比和养护条件下的强度变化。实现人工智能技术与现场实际需求的有效融合,构建高效且实用的预测系统,是当前行业和学术界亟需攻克的关键问题。
2 基于人工智能的混凝土强度预测模型构建方法
混凝土强度的早期预测依赖于对多维度数据的综合分析,而人工智能技术的引入为建立高效且精准的预测模型提供了新的方法论基础。构建混凝土强度预测模型的关键在于选择合适的输入特征,这些特征通常包括水胶比、掺合料比例、骨料种类、养护温湿度以及固化时间等参数。通过合理的数据预处理和特征工程,能够提高模型对关键影响因素的敏感性,从而增强预测的准确度。数据集的完整性与质量直接决定模型训练的效果,通常需进行缺失值处理、异常值检测和归一化操作,确保输入数据具有良好的分布特性。
模型构建阶段,常用的机器学习算法包括支持向量机(SVM)、随机森林(RF)、人工神经网络(ANN)以及近年来兴起的深度学习方法如卷积神经网络(CNN)和长短时记忆网络(LSTM)(见图1)。这些算法能够针对混凝土强度数据的非线性特征进行深度挖掘和建模。支持向量机通过构造最大间隔的超平面,实现高维空间中的分类与回归,适用于中小规模数据集;随机森林利用多棵决策树的集成学习思想,有效防止过拟合且解释性较好;神经网络及深度学习模型则能够捕捉更复杂的隐含关系,但对数据量和计算资源的需求较高。
图 1:混凝土强度预测模型构建算法选择流程图
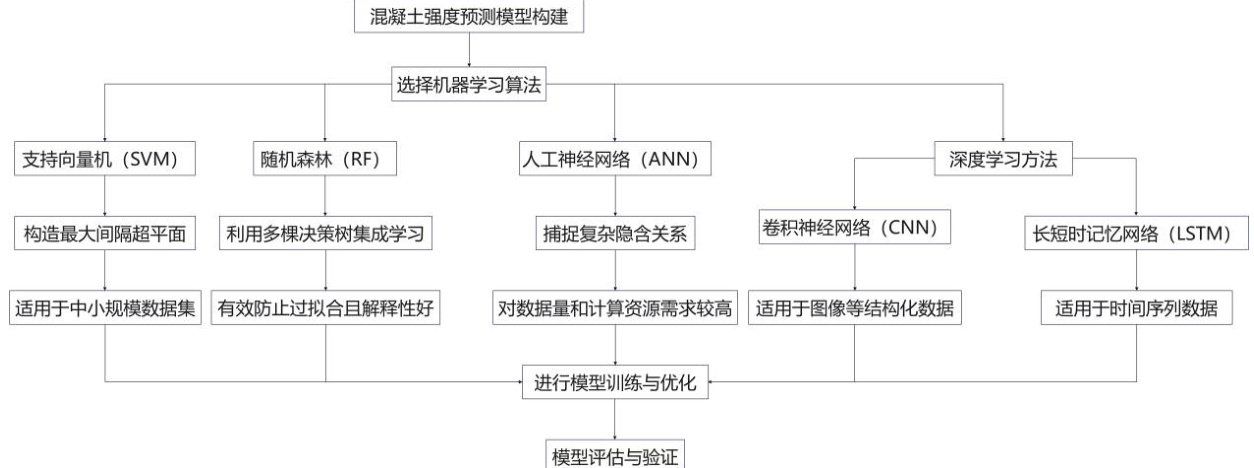
验证模型的有效性同样不可忽视,通过交叉验证和测试集评估模型在未见数据上的表现是衡量模型泛化能力的关键环节。采用均方误差(MSE)、决定系数(R²)等评价指标能够全面反映预测精度。结合多模型对比分析,可以筛选出最优的预测方案。模型的可解释性也逐渐受到重视,应用特征重要性分析和敏感性分析,有助于理解各输入参数对混凝土强度预测的影响机制,从而为施工工艺优化和质量控制提供理论支持。
3 模型性能验证及应用效果评估
在混凝土强度早期预测模型构建完成后,验证其性能是评估其实际应用价值的重要环节。通过选取独立的测试集对模型进行评估,可以全面了解其在未见数据上的预测能力。常用的评价指标包括均方误差(MSE)、平均绝对误差(MAE)以及决定系数(R²),这些指标能够从不同角度反映模型预测的准确性和稳定性。例如,有研究显示,基于 CNN 的混凝土抗压强度预测模型在测试集上的 MSE为 0.0023,MAE 为 0.0340,R²达到 0.8662 。高精度的模型不仅在数值误差上表现出色,还需具备良好的泛化能力,能够适应不同配比、养护环境和施工条件下混凝土强度的变化。为保证模型的稳健性,往往需要进行多轮交叉验证,避免因数据分布偏差带来的误差影响。
在实际工程应用中,模型的运行效率和实时性极为关键。复杂的深度学习模型虽能精准捕捉非线性特征,但计算成本高,难以满足现场快速反馈需求。为解决这一问题,研究者常采用多种技术优化模型。例如,通过模型压缩,可将参数量从 100 万减少到 50 万,使预测速度提升约 2 倍。此外,量化技术可将模型中的 32 位浮点参数转换为低精度表示,如 16 位或 8 位,进一步提升推理速度。结合云计算平台或边缘计算设备,实现模型的远程部署和快速响应,能实时支持施工决策。模型的应用效果不仅体现在数值预测的准确性上,更在于为工程项目提供科学依据、优化施工方案和保障结构安全。
实际案例表明,基于人工智能的预测模型可将养护时间从 7 天缩短到 5 天,显著提高施工效率。同时,返工次数从平均每月 5 次降低到 2 次。这些优化措施不仅提升了模型的实用性,还推动了建筑工程质量控制向智能化、精细化方向发展。
为了深入理解模型预测结果,开展特征重要性分析是必要环节。通过分析输入变量对输出结果的贡献度,可以识别出影响混凝土强度的关键因素。例如,在某项研究中,水泥含量(Cement)对混凝土抗压强度的贡献度为 0.28,龄期(Age)为 0.22,水(Water)为 0.15 。这些数据表明水泥含量和龄期是影响混凝土强度的关键因素。敏感性分析则有助于评估模型对环境变化的适应能力,确保模型在多变工况下依然保持较高的预测精度。综合性能验证和应用效果评估显示,基于人工智能的混凝土强度早期预测模型,不仅提升了预测水平,还推动了建筑工程质量控制向智能化、精细化方向发展,极大地促进了现代施工技术的进步。
结语:
基于人工智能的混凝土强度早期预测模型构建与验证,为建筑工程质量控制提供了有力技术支持。通过多种机器学习算法,模型有效捕捉了混凝土强度与多因素间的复杂非线性关系,显著提升了预测精度与稳定性。未来,随着技术进步,模型将更高效、精准,进一步推动建筑工程质量控制智能化、精细化发展,助力现代施工技术不断进步。
参考文献:
[1]李强,王斌.基于机器学习的混凝土强度预测方法研究[J].建筑科学,2020,36(4):55-62.
[2]赵明,陈晓华.人工智能在建筑材料性能预测中的应用进展[J].土木工程学报,2021,54(1):87-94.
[3]刘芳,张宇.混凝土早期强度影响因素及预测模型综述[J].工程材料与力学,2019,41(6):112-118.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)