.jpg)
基于深度强化学习的无人船自动舵系统研究

陈仲
身份证号码 220203198505111521
关键字:无人船;自动舵系统;深度强化学习;DDPG 算法;航向控制
一、引言
无人船作为水上无人系统的核心载体,已广泛应用于环境监测、航道测绘、应急救援等领域。自动舵系统作为无人船自主航行的“中枢神经”,其控制性能直接决定船舶的航行安全性与任务完成效率。传统自动舵控制多采用 PID 算法,虽具有结构简单、易实现的优势,但在复杂水域环境下(如风浪耦合干扰、航道狭窄弯曲),难以实时调整控制参数,易出现航向超调、响应滞后等问题。
随着人工智能技术的发展,强化学习凭借“试错学习”的特性,为动态环境下的控制问题提供了新思路。深度强化学习(DRL)结合深度学习的特征提取能力与强化学习的决策优化能力,可直接从高维环境状态中学习最优控制策略,无需建立精确的数学模型,在机器人控制、自动驾驶等领域已展现出优异性能。本文基于 DDPG 算法设计无人船自动舵系统,通过构建贴近真实水域的仿真场景与奖励机制,实现舵角的自适应调整,提升无人船在复杂环境下的航向控制精度与鲁棒性。
二、无人船自动舵系统总体设计
2.1 系统架构
无人船自动舵系统采用“感知-决策-控制”三层架构,具体如下:
· 感知层:通过 GPS、惯性测量单元(IMU)、风速风向传感器、毫米波雷达等设备,实时采集船舶的位置、航向角、横摇角、航速、环境风速、水流速度等状态信息,构建 12 维环境状态向量。
· 决策层:基于 DDPG 算法构建控制器,接收感知层输出的状态向量,通过 Actor网络输出舵角控制量(范围: -30∘~30∘) ),Critic 网络评估当前控制动作的价值,动态优化决策策略。
· 控制层:将决策层输出的舵角指令转换为舵机驱动信号,控制舵机转动,同时实时反馈舵机实际转角至感知层,形成闭环控制。
2.2 船体动力学模型构建
为确保强化学习训练环境的真实性,基于船舶操纵性方程(MMG 模型)构建无人船动力学模型,考虑船体、螺旋桨、舵机的耦合作用,核心方程如下:
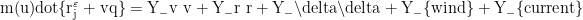
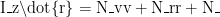 _\delta \delta +N- {wind} +N _{current}
_\delta \delta +N- {wind} +N _{current}
其中, m 为船舶质量, 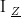 为绕
为绕  轴转动惯量,u、v 分别为船舶纵向、横向速度,r 为转向角速度,\delta 为舵角,Y、N 分别为横向力与转艏力矩系数,Y_{wind}、Y_{current}、N_{wind}、N_{current} 分别为风、水流干扰产生的横向力与转艏力矩。通过实船试验采集某型 3.8 米无人船的参数(如 m=850kg , IZ=1200kg⋅m2) ),代入模型完成参数校准。
轴转动惯量,u、v 分别为船舶纵向、横向速度,r 为转向角速度,\delta 为舵角,Y、N 分别为横向力与转艏力矩系数,Y_{wind}、Y_{current}、N_{wind}、N_{current} 分别为风、水流干扰产生的横向力与转艏力矩。通过实船试验采集某型 3.8 米无人船的参数(如 m=850kg , IZ=1200kg⋅m2) ),代入模型完成参数校准。
三、基于 DDPG 的自动舵控制算法设计
3.1 DDPG 算法原理
DDPG 算法是一种基于 Actor-Critic 框架的离线策略深度强化学习算法,适用于连续动作空间控制问题,其核心包括四个网络:
· Actor 主网络:输入环境状态向量,输出连续舵角动作,采用 3 层全连接网络(输入层 12 维,隐藏层 64 维、32 维,输出层 1 维),激活函数为 ReLU(隐藏层)与 tanh(输出层)。
· Actor 目标网络:与主网络结构一致,用于生成目标动作,参数通过主网络软更新(更新率 τ=0.001⟩ ),避免训练波动。
· Critic 主网络:输入状态与动作向量,输出动作价值 Q 值,采用 3 层全连接网络(输入层 13 维,隐藏层 64 维、32 维,输出层 1 维),激活函数为 ReLU。
· Critic 目标网络:与主网络结构一致,用于计算目标 Q 值,参数同样通过软更新更新。
3.2 奖励函数设计
奖励函数是引导智能体学习最优策略的关键,需综合考虑航向跟踪精度、控制平滑性与安全性,设计多目标奖励函数如下:
R=R _{track} + R_{smooth} +κ _{safe}
· 航向跟踪奖励 R_{track}:当实际航向角与目标航向角的偏差 |\Delta \psi| \leq 2°时, 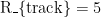 ;当
;当 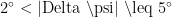 时, R{track}=2 ;当 |\Delta ∣psi∣>5∘ 时,R_{track} {=-3 ,惩罚航向偏差过大。
时, R{track}=2 ;当 |\Delta ∣psi∣>5∘ 时,R_{track} {=-3 ,惩罚航向偏差过大。
· 控制平滑奖励 R_{smooth}:当相邻时刻舵角变化量 |\Delta \delta| \leq 3° 时,R_{smooth}=1;当 |\Delta 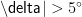 时,
时, 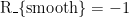 ,避免舵角频繁大幅变化导致舵机损耗。
,避免舵角频繁大幅变化导致舵机损耗。
· 安全奖励 R_{safe}:当横摇角 |\theta| 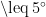 时, Rℓ{safe}=2 ;当
时, Rℓ{safe}=2 ;当 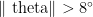 时,R_{safe }=-5 ,防止船舶因横摇过大倾覆。
时,R_{safe }=-5 ,防止船舶因横摇过大倾覆。
3.3 算法训练过程
1. 初始化 Actor 与 Critic 主网络、目标网络参数,设置经验回放池容量为 100000,批次大小为 64,学习率为 0.0001。
2. 在仿真环境中,智能体根据当前状态与 Actor 主网络输出的动作(加入高斯噪声探索),执行舵角控制,获取下一状态与奖励值,将(状态、动作、奖励、下一状态)存入经验回放池。
3. 当经验回放池样本数超过批次大小时,随机抽取批次样本,通过 Critic 目标网络计算目标 Q 值,利用梯度下降法更新 Critic 主网络参数,最小化 Q 值预测误差。
4. 通过策略梯度法更新 Actor 主网络参数,最大化 Critic 主网络输出的 Q 值。
5. 每隔100 步,通过软更新规则更新 Actor 与 Critic 目标网络参数,重复步骤2-4,直至训练迭代 10000 次,算法收敛。
四、结论与展望
本文将深度强化学习技术应用于无人船自动舵系统,基于 DDPG 算法设计控制器,通过构建真实船体动力学模型与多目标奖励函数,实现了复杂水域下无人船的高精度航向控制。实验结果表明,相较于传统 PID 算法,该系统在航向跟踪精度、响应速度与抗干扰能力上均有显著提升,验证了深度强化学习在无人船控制领域的应用价值。
未来研究可从两方面展开:一是引入多智能体强化学习,实现多艘无人船协同航行时的自动舵控制;二是结合数字孪生技术,将真实水域数据实时接入仿真训练环境,进一步提升算法的实际应用适应性。
参考文献
[1] 王建国, 李娜, 张军. 基于深度强化学习的无人船航向跟踪控制[J]. 哈尔滨工程大学学报, 2022, 43(5): 721-728.
[2] 刘海洋, 赵伟, 陈晨. 复杂海况下无人船自动舵系统的 DDPG 算法优化[J]. 船舶工程, 2021, 43(8): 112-118.
[3] 张明, 王丽丽, 李强. 无人船动力学建模与强化学习控制仿真[J]. 系统仿真学报, 2023, 35(2): 315-323.
[4] 陈峰, 刘敏, 王浩. 基于 DRL 的无人船自主避障与航向控制一体化研究[J]. 中国航海, 2022, 45(3): 45-51.
[5] 赵亮, 孙佳, 吴涛. 深度强化学习在船舶运动控制中的应用进展[J]. 船舶力学,2021, 25(10): 1325-1336.
.jpg)
.jpg)
.jpg)
.jpg)