.jpg)
基于 MTCNN 和 FaceNet 的智能打卡系统设计

吕轩
浙江衢州衢州学院 324000
1.研究背景和目的
1.1 研究背景
过去的考勤方法,比如刷卡、输入密码或使用证件,不但效率低,而且容易被他人代替,设备也不方便管理。而基于定位的移动考勤虽然更方便,却有侵犯隐私的风险,会让员工有抵触情绪。相比之下,用生物特征识别来打卡,凭借它在安全性和使用便捷性方面的优势,成了研究的重点方向。但人脸识别因为不需要接触,体验更好,而且识别速度快,所以在很多身份验证场景中都被采用。我们的系统用的是动态人脸识别技术,这种技术不但让打卡过程更自动化,也提高了数据采集的效率和安全性。
1.2 研究目的
本系统能从视频中实时提取人脸并进行比对。员工只需要在摄像头前停留几秒钟,就能完成打卡。系统后台还能查询和导出考勤记录。在保证识别准确的前提下,这个系统能减少人力成本,提高打卡效率。我们还对人脸识别的算法进行了优化,使识别的准确性、兼容性和稳定性都有所提升,逐步实现了低成本、高效率的智能打卡方案。
2.相关理论与技术研究
2.1 OpenCV 技术
OpenCV 是由 Intel 开发并开源维护的计算机跨平台视觉库,支持 C++, 、Python、Java 等常见编程语言的接口,并广泛应用于图像识别、机器视觉和深度学习等领域。其内置的视频分析、图像处理、特征提取、机器学习等模块特别适合在需要快速处理实时图像的场合。
系统调用 OpenCV 自带的 cv2.VideoCapture直接调用人脸识别设备。实时视频流的读取按照顺序读取每一帧,并使用 MTCNN 检测器检测图像中是否是人脸区域,若是人脸区域,则将人脸区域截取下来并进行保存,以用于人脸注册或者识别。
2.2 MTCNN 技术
MTCNN 是由深度卷积神经网络驱动的串联式人脸检测器,其基本思想是在面部识别和精准人脸关键点定位任务上作为协调优化的多目标学习,以提高检测准确率和精度。MTCNN 有三个 CNN 子网络,它们级联堆叠在一起,分别为 P-Net、R-Net 和O-Net,三个子网络具有不一样的作用,他们的复杂度依次递增,将依次筛除没有有效人脸的候选人脸框,使用MTCNN 实现人脸面部检测一共有四个步骤,具体如下:
第一阶段是图像预处理,提取输入网络层数据。图像在预处理后才能达到网络输入要求,一方面是为了减少人脸目标大小对识别的影响,另一方面是因为 P-Net 只能接受输入 12× 12 规格的图像,对原本的图像需要进行缩放处理。在图像处理中,为检测不同长宽的目标,进行了缩放处理,即对图像大小进行控制,使得缩放后的图像不小于预设的尺寸,并由此构建图像金字塔,以实现对检测目标尺寸的多样性适应,保证性能的最优。
第二阶段是进入 P-Net。 P-Net 网络是以全卷积的方式构建的,主要用来对原始的特征图进行人脸候选区域的前期特征提取与快速生成候选窗口。该阶段的 P-Net 接收人脸候选区域生成的边界修正结果,采用非最大值抑制(Non-MagnificatorSuppress,NMS)对候选窗口进行整合。 P-Net 网络结构如图 1 所示,需要输入一张长宽为 12× 12px 的 RGB 彩色图像,其中“ 3” 通道为颜色通道,最终将输出三个特征图,分别为是否存在人脸、人脸边界框坐标与左眼坐标、右眼坐标、鼻孔坐标、左嘴角坐标与右嘴角坐标。
2.3 FaceNet 算法
FaceNet 算法把人脸映射到欧氏空间,将欧氏空间中的距离与人脸之间的相似性相关联,一旦生成映射,可以很方便地用来识别人脸。FaceNet 算法使用训练好的深层卷积网络直接输出嵌入向量,而不是像传统方法那样,需要额外的中间瓶颈层。为了提高训练效率,该方法采用了在线三连体提取技术来生成大量与原始图像相近的匹配面部小块的三连体。然后,在生成三连体时,为每个三连体分配对应的原始图像,这样能够提高识别的准确率,因为它能以极高的效率处理每个向量,每个向量只使用 128维向量空间。
FaceNet 大多采用 Inception-ResNet 或 MobileNet 作为骨干网络,再通过若干个卷积、归一化、全连接层等操作,输出 128 或 512 维的特征向量用于计算不同人脸之间的相似性,常见的计算方法如下。
(1)欧式距离:用最常用的,通过距离判断是否为同一个人。
(2)余弦相似度:用于相对值比较,在高维空间中也常见。
由于 FaceNet 的输出是固定长度的向量,非常适用于需要快速身份比对和聚类的情况,FaceNet 采用卷积神经网络构建,其网络架构如图 4 所示。前部网络采用常规的卷积神经网络,这里采用Google 团队推出的GoogLeNet 网络模型,它是谷歌专门用来应对批量的滑人脸图像识别问题而设计的。网络中的后段没有采用 Softmax 作为损失函数,而是采用了L2 嵌入层,将全连接层输出特征向量的二范数进行标准化。
Google 提出在 DeepID2 模型中替换分类层 Triplet Loss,以提高特征学习能力,从而改善模型对人脸表示的学习能力。当类别数量增加至十万时,使用 Softmax 分类层会使得模型变得非常大,而Triplet Loss 能够很好的解决这一问题,使得学习过程更加高效。
三元组是由三张图片组成,包含了A、P、N,其中A 是样本 Anchor,即参考点;P 是同一人的图片,称为正例;N 是不同人的图片,称为负例。任意一张图片都可以作为基准点 A,基准点的同类人图片作为正例 P,不同类的人图片作为负例 N 在学习的过程中,通过神经网络使得样例 A 和其同类样本的欧氏距离缩小,使其与不同类别的样本的欧式距离增大,使得其与同类样本的距离不断缩小(类内距离),而与其他类别的图片的距离不断增大(类间距离),最终目的是提高人脸图片识别的准确度。
3.打卡系统设计
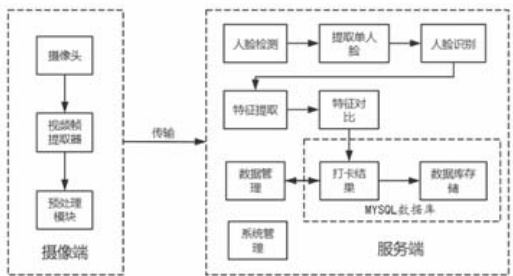
基于系统的需求,智能视频打卡系统的总体设计分为摄像端和服务端两个部分,其总体结构如图 1 所示,摄像端利用不同类型的摄像头捕捉人脸,以确保服务端解析出视频流中所需要的含有打卡人员的人脸的画面。服务器端可分为人员登录模块、人员注册模块、人面部识别模块、打卡记录模块和数据管理模块。摄像端通过设置光环境、背景环境,采集视频帧中的样本。接着,可能进行图像预处理,然后将处理过图像发送至服务器,再利用 MTCNN 模型做人脸框筛选,同时利用 FaceNet 模型进行特征提取与比对获得每一帧识别结果,对比数据库完成一次考勤记录,并在后台系统被管理员分析调用。
打卡系统的显示结果如下图2 所示:
4.总结
本研究设计并构建了一套基于 OpenCV 的智能化视频签到系统,旨在通过人工智能技术在企业管理体系中的应用,克服传统考勤模式下效率低下、易于代签以及管理不便等局限性问题。该系统采用了非接触式人脸识别技术,实现了打卡流程的智能化及自动化运作,显著提高了员工出勤记录的精确度与工作效能,为人力资源管理提供了更为科学的决策依据,同时也强化了工作环境的安全性,助力于构建以人为核心的管理模式的实现。
参考文献
[1]路金叶,郑方圆,王隽滔,等.基于特征脸的面部情绪识别研究[J].西北师范大学学(自然科学版),2025,61(01):117-124.
[2] 王 丽 娟 . 基 于 FisherFace 算 法 的 人 脸 识 别 方 案 研 究 [J]. 机 电 信息,2020,(27):103-104.
[3] 梁博. 计算机视觉在人脸识别领域中的应用研究[J]. 信息与电脑( 理版),2019,31(20):99-101.
[4]Guangwei He,Zhiyu Fan,and Tonglin Che."Design and Implementation of FatigueDriving Detection System Based on YOLOv8 and OpenCV."Journal of Physics: ConferenceSeries 2999.1(2025):012021-012021.
[5]Alsubhi H A ,Jaha S E .Front-to-Side Hard and Soft Biometrics for AugmentedZero-Shot Side Face Recognition[J].Sensors,2025,25(6):1638-1638.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)