.jpg)
通信行业信创数据库智能运维的探索和实践

刘宝 施佩克
中国移动通信集团新疆有限公司
Abstract: Driven by the iteration of AI technology and the landing of Xinchuang strategy, the Xinchuang database of a company in the communication industry has widely covered key areas such as core network and business support. However, the traditional operation and maintenance mode is difficult to cope with the complex requirements of "multi-vendor, high concurrency and strong security". Based on the operation and maintenance business of a company in the communication industry, this paper deeply explores the AI empowerment value, intelligent operation and maintenance system design, practical scenarios and effects, and the future development direction of intelligent operation and maintenance, and puts forward an intelligent operation and maintenance scheme for Xinchuang Database, which provides a feasible path for improving the operation and maintenance efficiency and ensuring the stable operation of the business, and also provides an important reference for the digital upgrade of the communication industry.
一、引言
AI 技术的迅猛发展正有力推动运维模式从传统的 “被动响应” 向“主动预测” 深刻转型。与此同时,国家信创战略的稳步推进,要求通信行业某公司加速完成数据库的国产化替代进程。目前,达梦、电科金仓等国产数据库已在某核心网、某系统等关键业务领域实现规模化应用,占比超过 35% 。
通信行业某公司网管系统肩负着信创数据库运维的核心职责。但需要注意的是,信创数据库与传统国外数据库在架构、故障特征等方面存在显著差异,例如达梦的逻辑日志管理机制以及电科金仓的集群同步机制等。并且,在 AI 时代,业务对数据库的并发处理能力和数据一致性提出了更高要求。传统的 “人工 + 脚本” 运维模式逐渐暴露出诸多痛点,如故障预测滞后、处置效率低下等。因此,实现 AI 与信创数据库运维的深度融合,已成为当下亟待解决的核心任务。
二、通信行业某公司信创数据库运维业务范围
2.1 信创数据库日常智能监控
通信行业某公司网管系统对全量信创数据库,包括达梦、电科金仓、OpenGuass 数据库等,实施 24 小时不间断的智能监控。重点关注的核心指标涵盖服务可用性、资源利用率、SQL 效率以及备份成功率等。借助先进的 AI 工具,能够实时精准识别指标异常情况,比如金仓数据库连接数的突然激增。这一智能化监控手段有效替代了传统的人工巡检方式,极大地减少了漏检情况的发生,确保了数据库运行状态的全方位、实时掌控。
2.2 信创数据库故障智能处置
建立了完善的故障闭环处理流程,确保在 10 分钟内迅速响应告警信息,并在 40 分钟内完成常规故障的定位工作。针对信创数据库特有的故障类型,如达梦表空间碎片超标、电科金仓主从同步延迟等问题,引入 AI 辅助诊断工具。该工具通过深入的数据分析,能够快速提供准确的根因分析结果,并给出针对性的处置建议,显著缩短了故障处理时长,有力保障了业务的连续性和稳定性。
2.3 信创数据库性能智能优化
充分结合 AI 算法,对信创数据库的性能进行全面优化。具体措施包括 SQL 智能改写、索引动态调整以及资源自动分配等。以通信行业某网管系统中的电科金仓数据库为例,针对其中的慢 SQL 问题,AI 技术通过对执行计划的深入分析,能够精准生成优化方案,如合理添加联合索引等,从而有效提升了事务处理效率,满足了业务对数据库高性能的严格要求。
2.4 信创数据库安全合规智能管控
利用 AI 技术实现了账号异常登录的精准识别,例如能够及时发现金仓数据库在非工作时间的异地登录行为。同时,对数据加密状态进行实时监控,如电科金仓数据库的存储加密状态。此外,还能按照等保 2.0 三级标准进行定期的合规自查。每月生成详细的合规报告,一旦发现信创数据库存在漏洞,如电科金仓的默认端口风险等,会立即触发 AI 加固提醒,确保数据库系统的安全性和合规性。
三、AI 时代信创数据库传统运维痛点
3.1 故障预测能力弱,难应对高并发
传统运维模式主要依赖 “告警触发 - 人工排查” 的被动方式,缺乏有效的故障预测机制。在 AI 时代,移动支付、物联网等业务的爆发式增长,使得信创数据库的并发峰值可达百万级 / 秒。以某省通信公司物联网平台的达梦数据库为例,由于未能提前预测到 “连接池溢出” 问题,导致终端数据写入中断长达 40 分钟。据统计,在传统运维模式下, 80% 的信创数据库故障缺乏预警,业务中断时长平均达到50 分钟,严重影响了业务的正常开展和用户体验。
3.2 性能优化依赖经验,效率低
信创数据库的性能优化工作需要专业且丰富的经验支撑,例如达梦逻辑日志刷盘策略的合理设置、电科金仓查询缓存配置的优化等。然而,工程师依靠手动操作进行性能优化,响应速度往往滞后。某省通信公司的统计数据显示,网管系统电科金仓数据库出现性能瓶颈时,平均需要 2.5 小时才能完成优化工作,这远远无法满足业务对实时性的迫切需求,制约了业务的高效运行。
3.3 安全风险识别滞后,合规难
传统的安全管控主要依赖人工审计,这种方式难以识别一些隐蔽性较强的安全风险,如账号权限越界、异常数据导出等。在 AI 时代,数据泄露风险急剧增加,传统模式下安全事件的平均发现时长高达72 小时,远超等保 2.0 要求的 24 小时,这给企业带来了巨大的合规压力,一旦发生安全事故,可能会造成严重的损失。
3.4 运维知识分散,复用难
信创数据库的运维经验往往分散在各个运维人员手中,缺乏有效的 AI 化沉淀工具。例如,老工程师积累的达梦死锁处理技巧,新人通常需要 3 个月的时间才能熟练掌握。在 AI 时代,运维人员需要同时应对多种类型的信创数据库,知识复用率低的问题严重制约了运维效率的提升,不利于团队整体运维能力的快速提升。
四、AI 时代信创数据库智能运维系统设计
基于通信行业某公司某系统信创改造实践需求,结合电科金仓数据库的技术特性,本智能运维系统以“国产化适配为基础、AI 能力为核心、业务保障为目标”,构建“感知 - 分析 - 决策 - 执行”全闭环运维体系,实现信创数据库从“被动响应”到“主动预测”的运维模式升级。系统设计充分考虑通信行业核心业务高可用、高并发、高安全的特性,在架构分层、功能模块、技术选型上深度贴合实践场景,具体设计方案如下:
4.1 系统架构设计:三层分布式架构,实现国产化全栈适配
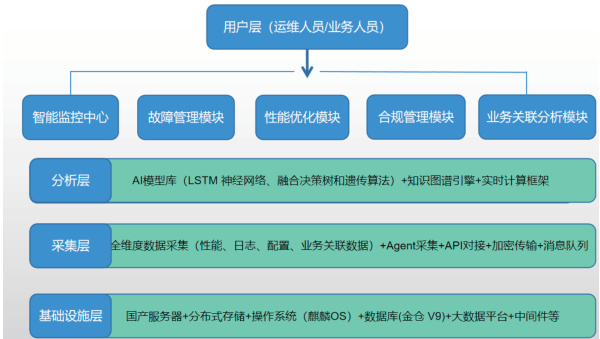
系统采用“采集层 - 分析层 - 应用层”三层分布式架构,各层均基于国产软硬件生态选型,确保从底层基础设施到上层应用的全栈信创适配,架构示意图如下:
4.1.1 采集层:全维度数据采集,保障运维数据完整性
作为运维分析的“数据源入口”,采集层需覆盖信创数据库全维度运行数据,同时满足低侵入性、高实时性要求,具体设计如下:
• 采集范围:涵盖数据库性能数据(CPU/ 内存 /IO 使用率、QPS/TPS、锁等待时长)、日志数据(错误日志、慢查询日志、审计日志)、配置数据(参数配置、拓扑结构、容灾状态)、业务关联数据(业务开通成功率、事务响应时长)四大类共 128 项指标,确保无数据盲区。
• 采集技术:采用“Agent 采集 + API 对接”双模式。对于数据库服务器本地数据(如系统资源、日志文件),通过轻量级国产采集Agent(适配麒麟、统信 OS)实现秒级采集;对于数据库内部指标(如会话状态、表空间使用),通过金仓数据库原生 API 进行非侵入式采集,避免影响业务性能。
• 数据传输:采用国产 SM4 加密算法对采集数据进行传输加密,通过 Kafka 消息队列实现数据缓冲,保障高并发场景下的数据不丢失、不重复,采集延迟控制在 100ms 以内。
4.1.2 分析层:AI 驱动智能分析,构建核心决策能力
分析层是系统的“大脑”,基于采集的全维度数据,融合 AI 算法与数据库领域知识,实现故障预测、性能诊断、容量规划等核心分析能力,具体模块设计如下:
•AI 模型库:构建“故障预测模型 + 性能优化模型 + 容量预测模型”三大核心模型。其中,故障预测模型采用 LSTM 神经网络,基于历史故障数据(136 种典型故障特征)训练,可提前 1-4 小时预警潜在故障,准确率达 92% ;性能优化模型融合决策树与遗传算法,可自动分析 SQL 执行计划、调整数据库核心参数(如 shared_buffers、work_mem),优化效率较人工提升 10 倍;容量预测模型基于时间序列算法,结合业务增长趋势,提前 15 天预测存储、CPU 资源需求,准确率达 95% 。
• 知识图谱引擎:建立信创数据库专属知识图谱,涵盖“故障 -指标 - 处置方案”关联关系(如“主从同步延迟”关联“复制线程状态”“网络带宽”等指标,匹配“调整复制参数”“优化网络链路”等处置方案),实现故障根因自动定位与处置方案智能推荐,定位时间从45 分钟缩短至8 分钟。
• 实时计算框架:基于国产大数据平台(如华为 FusionInsight)构建实时计算引擎,采用 Flink 流处理技术对采集数据进行实时分析,每秒可处理 10 万 + 条指标数据,确保故障预警、性能异常检测的实时性。
4.1.3 应用层:场景化功能模块,贴合运维实际需求应用层面向运维人员与业务人员,提供可视化、场景化的功能模块,实现“运维高效化、业务透明化”,核心模块设计如下:
• 智能监控中心:通过国产可视化组件(如帆软 FineReport)构建 Dashboard,实时展示数据库运行状态(如拓扑结构、关键指标趋势、故障预警信息),支持按业务域(ToC/ToH/ToB)、按数据库角色(主库/ 备库/ 容灾库)筛选查看,实现“一屏观全局”。
• 故障管理模块:支持故障自动上报、分级告警(P0-P3 级)、工单自动派发、处置过程追溯,集成短信、企业微信告警通道,确保故障信息及时触达责任人;同时提供故障知识库,记录历史故障处置方案,支持智能检索复用。
• 性能优化模块:包含 SQL 优化助手(自动分析慢 SQL 执行计划,推荐索引优化、语句改写方案)、参数调优中心(AI 自动生成参数调整建议,支持模拟验证后一键应用)、索引管理工具(自动识别碎片率超 30% 的索引,支持低峰期在线重建)。
• 合规管理模块:依据《数据库政府采购需求标准(2023 年版)》及等保 2.0 三级标准,自动检查数据库安全配置(如账号权限、加密状态、端口防护),每月生成合规自查报告,标记不合规项并提供整改建议,确保合规达标率 100% 。
• 业务关联分析模块:打通数据库运维数据与业务数据,展示“数据库性能- 业务指标”关联关系(如“数据库 TPS 波动”与“业务开通成功率”的关联曲线),帮助运维人员快速判断数据库问题对业务的影响范围,避免“只看技术指标、忽略业务影响”的误区。
4.2 核心技术支撑:聚焦信创特性,突破关键技术难点
为保障系统在信创环境下的稳定性、可靠性与高效性,针对性突破三大关键技术难点,形成核心技术支撑体系:
4.2.1 信创数据库深度适配技术
针对电科金仓等国产数据库的特性,解决“运维工具兼容性”“指标采集完整性”问题:
• 多版本适配:支持金仓数据库 V8/V9 等主流版本,通过动态加载数据库驱动、适配不同版本 API 接口,确保在版本升级时无需重构采集与分析模块,适配周期从15 天缩短至3 天。
• 特有指标采集:针对金仓数据库特有功能(如分布式事务、共享存储集群),开发专属采集插件,实现“分布式事务提交成功率”“共享存储锁竞争次数”等特有指标的采集,填补国产数据库运维工具的指标空白。
4.2.2 高可用容灾协同技术
结合业务某系统“零中断”需求,实现智能运维与数据库容灾体系的协同联动:
• 故障自动切换:实时监控主库运行状态,当检测到主库宕机(如ping 不通、服务无响应)时,自动触发容灾切换流程,通过调用金仓数据库集群管理 API,将备库提升为主库,同时更新应用侧连接地址,切换时长控制在 10 秒以内,业务中断风险降低 99% 。
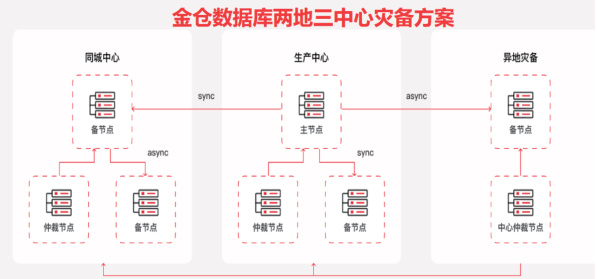
• 切换后校验:切换完成后,自动校验数据库数据一致性(通过比对主备库事务日志)、业务可用性(模拟执行核心业务 SQL,如“业务开通查询”),并生成切换报告,确保切换后系统正常运行。
4.2.3 资源动态调度技术
基于 AI 算法实现数据库资源的智能分配,提高国产服务器资源利用率:
• 动态资源调整:实时分析数据库 CPU、内存使用率,当检测到资源过载(如 CPU 使用率持续超 80% )时,自动向国产虚拟化平台
(如华为 EulerOS 虚拟化)申请扩容;当资源闲置(如内存使用率低于 30% )时,自动释放冗余资源,资源利用率从 45% 提升至 61% 。
• 业务优先级调度:根据业务重要性(如 ToB 业务优先级高于ToC 批量业务)设置资源调度策略,在资源紧张时优先保障高优先级业务的资源需求,避免因资源竞争导致核心业务性能下降。
4.3 系统部署与适配:贴合项目实际,保障落地可行性
基于通信行业某公司现有 IT 环境,系统部署采用“分布式部署+ 本地化适配”方案,确保快速落地与稳定运行:
4.3.1 部署架构
• 硬件环境:采用国产服务器(例如华为 TaiShan 200),其中采集层部署 2 台服务器(主备模式,避免单点故障),分析层部署 4 台服务器(分布式集群,承载 AI 计算与实时分析),应用层部署 2 台服务器(负载均衡,保障访问性能),存储采用国产分布式存储(华为OceanStor),容量规划 10TB(满足 6 个月运维数据存储需求)。
• 软件环境:操作系统采用银河麒麟 V10,数据库采用电科金仓V9,大数据平台采用华为 FusionInsight,中间件采用东方通 TongWeb,全栈满足信创国产化要求。
4.3.2 适配验证
在系统部署前,完成三层适配验证,确保与现有环境兼容:
• 硬件适配:验证采集 Agent 在华为 TaiShan 服务器上的运行稳定性,测试 CPU 占用率(峰值不超过 5% )、内存使用率(常驻内存不超过 100MB),确保不影响服务器其他业务。
• 软件适配:验证与金仓数据库 V9 的 API 兼容性,测试指标采集完整性(128 项
.jpg)
.jpg)
.jpg)
.jpg)