.jpg)
浅谈使用EasyDataSet制作领域数据集的一些经验

李科 彭小倩 陈健 罗志红
61287 部队 四川成都 610000
1.EasyDataSet 介绍
EasyDataSet 是北京航空航天大学计算机学院共同完成的开源项目,Github 代码库 http://github.com/ConardLi/easy-dataset,超 9000 星。具备 4 项核心能力:(1)文档处理的智能化突破,混合分块策略,允许用户进行精细的手动调整(2)高质量的问答对,系统提示词精确控制问题的风格、目标受众和语调(3)参数配置的人性化设计,提供包括模型提供商、模型名称、API 端口、API 密钥、温度设置等众多选项(4)数据集导出格式的标准化与兼容性,支持导出 JSON、JSONL、CSV 格式的数据集,风格支持 Alpaca、ShareGPT 和自定义格式,生成数据集可与 LlamaFactory 训练框架无缝集成。
2.环境配置和软件安装
笔者个人的计算机配置为:处理器 Intel(R) Xeon(R) Silver 4215R CPU @ 3.20GHz,显卡 RTXA4000 16G,系统为 Windows10 专业版 22H2。大模型管理框架使用的是 Ollama 0.9.6,大模型安装有Qwen3-Embedding-8B、DeepSeek-R1-0528-Qwen3-8B-Q4_K_M、DeepSeek-R1-14B、Qwen3-30B-A3B。EasyDataSet 版本为最新 1.3.9。
3.文档准备和预处理
3.1 文档收集
在领域数据集构建过程中,需从学术论文、行业报告、权威出版物、新闻报道等多渠道获取数据。文档的多样性与代表性至关重要,需收集大量文档覆盖目标领域的核心范畴与边缘场景。在汇聚文档的同时,需建立质量评估机制,确保文档内容的准确性、完整性和时效性。
3.2 文档分类
完成文档收集后,需依据预设的领域体系进行系统化划分,并按类别建立结构化存储目录。在领域目录下,再按文档类型分类,包括纯文本类、代码片段类、数值数据类等。对于不同类型的文档,我们将采取不同的参数配置(如文本分段策略、问题密度控制、提示词工程设计等)。
3.3 文档清洗
在文档分类完成后,需要对文档进行严格的清洗和预处理。这一步骤主要是为了去除无效或重复数据、处理缺失值以及标准化文档格式等。如清除乱码、清除图片(目前复杂图片离线模型识别效果差),将复杂表格中的文字用段落的形式表达出来,将文档中含有本单位、该任务、我们、上一次这样的词语替换成准确的表达。
4. 建立项目和配置参数
4.1 创建新项目
打开 EasyDataSet 软件,创建新的项目,并为项目命名。命名很重要,关系到大模型进行领域标签的生成,建议在命名时遵循统一的规范,例如包含主题、时间、范围、用途、数据类型等重要信息。核心原则是准确性、清晰性和唯一性,让使用者一眼看懂内容。
4.2 配置基本参数
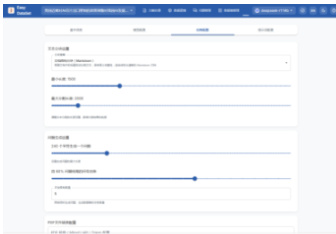
创建好项目后,配置一些基本的参数选项。例如,模型配置中的模型提供商、模型接口、模型名称、模型温度、最大生成 token 数;任务配置中的文本分块策略、最小最大分块字数、手动分块符号等;提示词中的全局提示词和生成问题提示词、生成答案提示词。这些参数将直接影响后续的数据处理流程和数据集生成的质量。
5.文档导入与切割
EasyDataSet 支持导入多种格式的文档,如常见的 TXT、PDF、MD、DOCX 格式。在软件“文献处理”页面,可通过拖拽或点击“上传”按钮批量导入文档。导入过程中系统将自动进行格式校验,对加密 PDF、损坏 DOCX 等异常文件会生成错误报告并提示修复建议。
5.1 选择合适的切割方法
EasyDataSet 提供了五种文本切割功能,分别介绍如下。文档结构分块:根据文档中的标题自动分割文本,保持语义的完整性,适合结构化清晰的文档,例如 Markdown 文档。自定义分块:采用人工输入分割符,适用于复杂文档。固定长度分块(字符):结合自然段落,按指定长度组合,适用于普通文本文件。固定 Token 长度分块:基于 Token 数据分块。程序代码智能分块:根据不同编程语言的语法结构进行智能分块,避免不完整分割。
如果使用 PDF 格式的文件导入后切割形成文本块文字效果不理想,可通过 Ollama 框架部署视觉语言模型,推荐 LLaVA-13B 或 CogVLM,增强文本提取能力。启用该模式后,处理耗时将增加 3 到 5倍。
5.2 注意保持文本的完整性
在进行文本切割时,要特别注意保持文本内容的完整性,避免因分割不当导致的信息损失或误解。除了上面提到的采用恰当的分块策略外,还可以在文本切块后,采取人工检查切割情况,手动调整分段边界,尽可能使章节段落完整。
图 1 模型配置
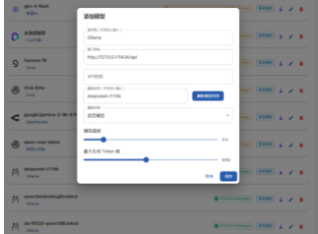
图 2 任务设置
6. 标签管理
完善的标签管理体系能够显著提高数据集制作的质量和效率,我们可以根据领域特点,定义一套科学且完整的标签体系,也可以让大模型根据文档内容自动提炼出一二级标签。一点技巧:在确定标签后,再增加同领域其他文件时可以沿用原标签,也可以增量修改标签。
7. 构建问题
构建问题是制作高质量领域数据集的关键环节,EasyDataSet 利用大模型的推理功能,按字数提出问题,涵盖文章内容。不同模型的推理能力是构建问题的重要因素,因此,需要选择参数量合适的模型,兼顾构建问题的质量和处理文本块的速度。构建完问题后,我们需要检查问题的标签是否正确,有可能出现问题缺标签的情况,这就需要我们在“问题管理”页面的领域树视图中手动把问题挂接上相应标签。
8. 问答对生成和检查
8.1 设置合理的约束条件
可以根据文档的类型,设置全局提示词、生成问题提示词、生成答案提示词,主要对领域特点、受众对象、问题风格、回答风格、字数长短等方面进行约束。
8.2 问答对的生成
在设置完以上参数后,在“问题管理”页面,先选择采用哪些问题构造数据集,再通过“批量构造数据集”选项,调用大模型的推理生成能力构造答案。
8.3 检查问答对
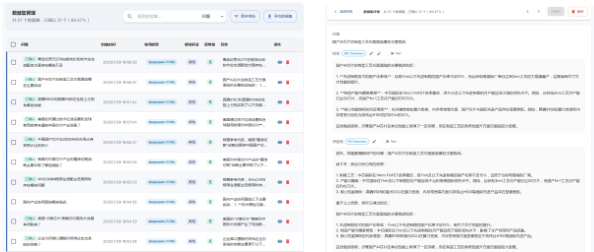
问答对的质量直接关系到最终数据集的效果。在问答对自动生成之后,必须进行严格的人工审核,主要针对语法错误、错别字、逻辑漏洞、内容完整、模型幻觉等方面。采用全量检查的方式,检查问答对的思维链、答案内容是否符合预期目标,并及时修正。如果涉及到专业领域方面的知识,可以邀请相关领域专家进行质量把关。
图 3 问答对管理 图 4 问答对审核
9. 数据集生成
9.1 导出与保存
根据项目要求,将整理好的数据集以合适的格式导出并保存。常用的数据集文件格式包括 JSON、JSONL、CSV。数据集风格又分为 Alpaca 风格和 ShareGPT 风格,每种风格都有其特点和适用场景,区别在于 Alpaca 风格主要用于单轮指令驱动任务(如问答、翻译、摘要),数据结构以 instruction、input、output 为主体的 JSON 对象,典型应用场景为指令响应、领域知识问答、文本结构化生成,而 ShareGPT 风格主要用于多轮对话与工具调用,如聊天机器人、API 交互,数据结构以 conversations 列表为核心的多角色对话链,应用场景为多轮对话、客服系统、实时交互。
9.2 元数据表填写和归档
完成数据集生成后,应立即进行元数据表的填写,元数据表应该包含:数据集名称,领域,数据集问答对数量,数据集的格式和风格,数据集制作完成的时间,源文档的名称、字数,数据集制作人的名字,数据集制作中出现的问题和解决办法,质检人员发现的问题和处理情况。最后按目录进行数据集归档。
10.其他经验
10.1.如果是小场景,多人制作数据集而终端电脑算力不足,可以使用 B/S 架构,在服务器端安装ollama,配置 ollama 局域网暴露,操作如下:服务器高级系统设置的环境变量中,设置用户变量 ollama_host=服务器局域网 IP:11434,系统变量 OLLAMA_HOST=0.0.0.0, OLLAMA_ORIGINS= "*"。防火墙放行 ollama,在 Powershell 下执行命令:netsh advfirewall firewall add rule name="Allow Port11434" dir=in action=allow protocol=TCP localport=11434。客户端 EsayDataSet 模型页面中添加 http://服务器局域网 IP:11434/v1/ 和对应模型全称即可。
10.2.如果是大场景的生产,采用 H100 以上多卡服务器,可通过采用 docker 部署 EasyDataSet、ollama,使用大参数量的模型,采取张量并行,将模型权重放在不同的显卡上面,根据模型大小和 GPU显存调整模型层数分配,并通过 Nginx 代理控制并发连接数,添加 SSL 证书,安全地对外提供服务。
10.3.EasyDataSet1.3.9 新增的数据蒸馏功能,是通过 AI 构建多级标签,在每个子标签下,批量构建大量问题。通过大模型回答这些问题,从现有大模型中提取特定知识、能力,生成紧凑且保留核心知识的问答对数据集的过程。
结语:通过在隔离网环境下利用 EasyDataSet 制作领域数据集,我们不仅成功地实现了高效、安全的数据集生产和管理,而且在这个过程中积累了丰富的经验与技巧。未来的工作中,我们将继续优化相关流程,探索更多创新性的解决方案,为数据集制作的研究与发展做出更大的贡献。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)