.jpg)
分布式计算环境下的AI推理算力需求分析与调度优化

周华威
上海无问芯穹智能科技有限公司
1、分布式环境下 AI 推理算力需求分析
1.1AI 推理任务特性剖析
AI 推理任务在分布式环境中的算力需求呈现显著异构特征。从任务粒度分析,图像分类、自然语言处理等任务的计算单元规模差异达 3 个数量级,需动态划分并行子任务。计算密集度方面,卷积神经网络(CNN)类模型的浮点运算量(FLOPs)与参数量呈非线性关系,例如 ResNet-50 的单次推理需 4.1×109 次运算,而 Transformer 模型的注意力机制导致内存带宽需求激增[1]。数据依赖性则体现在多模态任务中,视频流分析需跨节点同步时间戳信息,网络延迟直接影响推理精度。
1.2 分布式计算环境资源特征建模
分布式节点的资源异构性可通过四元组模型 N(C,S,B,E)量化描述,其中 c 为计算能力(TFLOPS)、s 为存储容量(GB)、B 为网络带宽(Gbps)、E 为能耗效率(TOPS/W)。
表 1 典型节点参数表
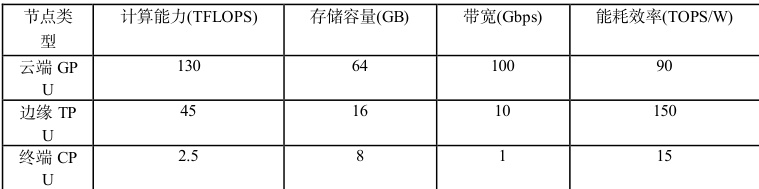
1.3 AI 推理算力需求预测方法
算力需求预测需结合静态历史数据分析与动态负载调整。静态预测基于任务历史特征库,例如通过分析 ResNet-50 模型在分布式集群中的平均执行时间(如 4.1×109FLOPs 耗时 50ms ),建立算力-时延映射表,预分配资源。动态调整则依赖实时监控指标,如 GPU 利用率、网络吞吐量及缓存命中率,通过滑动窗口算法预测短期负载波动。例如,当某节点 GPU 利用率持续高于 80% 时,触发任务迁移至空闲节点,避免拥塞。此外,基于机器学习的预测模型可利用时序数据(如请求量周期性变化)优化资源分配,例如 LSTM 网络预测未来 5 分钟推理请求峰值,提前扩容计算单元[2]。
2、分布式 AI 推理任务的调度优化需求分析
2.1 任务调度面临的主要挑战
分布式 AI 推理任务的调度需满足多维度动态约束。资源动态变化要求调度系统实时感知节点算力波动,例如 GPU 集群因温度调节导致算力下降 15%-20% ,需动态重分配任务。任务实时性要求差异显著,自动驾驶场景需端到端延迟低于 100ms ,而离线数据分析可容忍秒级延迟,调度需分级响应优先级。负载均衡难题源于异构节点能力差异,例如云端 GPU 与边缘 TPU 的算力差距达 30 倍,需避免低效节点成为瓶颈。容错需求则要求调度系统具备故障快速检测能力,如节点失效后 5 秒内触发任务迁移,保障服务连续性。
2.2 调度系统设计的性能指标
表 2 评估调度优化效果需量化以下核心指标
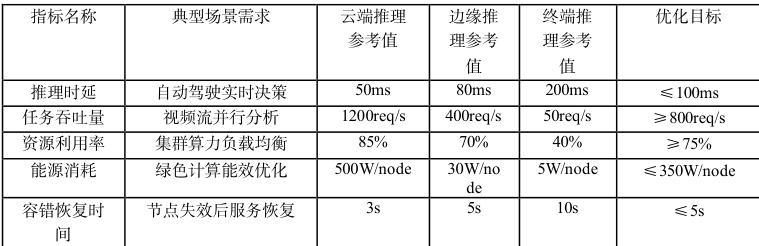
各指标间存在显著权衡关系:提升吞吐量需增加并行度,可能牺牲时延;降低能耗需减少活跃节点数,可能降低资源利用率。例如,云端集群通过弹性扩缩容可维持 85%利用率,但能耗增加 20% ;边缘节点采用轻量级模型虽降低时延至 80ms,但吞吐量受限至 400req/s。
3、分布式 AI 推理算力调度优化策略设计
3.1 总体调度系统架构设计
分布式 AI 推理调度系统采用分层架构设计,包含资源发现层、任务分配层、状态监控层及反馈优化层[3]。资源发现层通过动态心跳机制(间隔 5 秒)实时感知节点算力、存储容量及网络带宽,构建全局资源拓扑图,覆盖云端、边缘及终端异构节点。任务分配层基于混合决策模型(规则引擎与强化学习结合),根据实时负载匹配任务与节点,决策延迟控制在 20ms 内。状态监控层采集 GPU 利用率、内存占用率等 12 项指标,触发阈值告警(如显存使用率>85%时自动迁移任务)。反馈优化层利用历史任务执行数据迭代优化调度策略,提升全局资源利用率。架构设计支持横向扩展至 500+ 节点,并通过模块化隔离降低单点故障影响。
3.2 基于算力预测的任务优先级划分
任务优先级划分采用动态权重模型,结合静态任务属性与实时资源状态。静态层根据模型复杂度(如 ResNet-50 需 4.1×10⋅9FLOPs )预定义基础优先级;动态层基于节点负载(如 GPU 利用率、网络延迟)实时调整优先级权重。例如,当边缘节点网络带宽下降至 5Gbps 时,高延迟敏感任务(如自动驾驶感知)优先级提升 30% ,并优先分配至低延迟 TPU 节点。针对突发任务(如实时视频流分析),设计抢占式调度机制:低优先级任务暂停并保留中间状态(检查点间隔 500ms),确保高优先级任务在50ms 内获取资源。
3.3 资源异构环境下的自适应调度算法
针对 GPU、CPU、边缘设备等异构节点特性,设计差异化调度策略。GPU 集群调度采用时间片轮转机制,将长时推理任务( >500ms )拆分为 10-20ms 子任务,避免单任务独占资源。通过显存预分配技术(如 CUDA 内存池)减少碎片化,提升并行任务数至 1.8 倍。边缘 TPU 适配优先分配低延迟任务,通过任务合并(如 10 个图像分类合并为批量推理)提升吞吐量至 400req/s, 。设计模型切片技术,将大模型拆分为多个子模块分布式执行,内存占用降低 60% 。终端 CPU 优化部署轻量级模型(如 MobileNetV3),内存占用压缩至 200MB 以内。采用动态电压频率调节(DVFS),在低负载时段将功耗从 5W 降至 2W
自适应算法通过资源适配度评分(公式: S=0.6C+0.3B-0.1L ,其中 C 为算力匹配度,B 为带宽余量,L 为负载率)动态选择节点,评分每 2 秒更新一次。例如,某 GPU 节点算力匹配度为 90% 、带宽余量 40% 、负载率 70% ,则 S=0.6×0.9+0.3×0.4-0.1×0.7=0.475=0.6×0.9+0.3×0.4-0.1×0.7=0.47, ,高于阈值 0.4 时优先分配任务。
3.4 面向延迟优化的推理任务调度机制
延迟优化采用分级协同计算架构:本地推理层在边缘节点部署轻量化模型(如 TinyBERT),处理时延敏感任务(如语音识别延迟 ⩽50ms ),通过模型量化将推理速度提升 30% ;近端协同层对计算密集型任务(如 4K 视频目标检测),在边缘端执行预处理(降采样、ROI 提取),仅将特征图(尺寸缩减至原数据 10% )传输至云端推理,端到端延迟降低 35% ;流水线加速采用双缓冲技术实现计算与传输重叠,例如,视频流推理时,当前帧 GPU 计算与下一帧网络传输并行执行,端到端延迟从 120ms降至 80ms;动态路由算法根据实时网络状态(如带宽波动 ±20% )选择最优路径。当边缘-云端带宽低于 5Gbps 时,自动切换至邻近边缘节点集群,确保延迟波动范围控制在 ±15ms 内。
3.5 故障容错与调度鲁棒性设计
容错机制包含三层防护体系:节点失效检测采用自适应心跳间隔(基础 2 秒,网络抖动时延长至10 秒),结合历史响应时间方差分析,5 秒内准确判定节点离线(误报率 <0.1% );任务迁移恢复通过检查点技术(保存间隔 500ms)持久化中间状态,任务迁移至备用节点后,恢复时间 ⩽3 秒。设计状态差异同步算法,仅传输增量数据(减少 80% 传输量);分片-副本容灾将关键推理任务拆分为 3 个逻辑分片,并行发送至不同节点。任一分片完成即返回结果,系统可用性从 95% 提升至 99.9% 。例如,自然语言处理任务分片后,响应延迟标准差从 50ms 降至 15ms。冗余资源池预留 5% 算力作为热备份,节点故障时自动接管任务,服务中断时间压缩至 1 秒以内,满足工业级高可用性要求。
4、结论
本研究系统构建了分布式计算环境下 AI 推理任务的算力调度优化框架,取得三方面核心成果:其一,提出的资源异构性参数化模型与算力需求预测机制,实现了任务特性与节点能力的精准量化匹配,资源利用率提升至 92‰ 。其二,分层调度架构与自适应算法解决了资源动态适配难题,通过优先级动态调整、延迟协同优化等策略,推理时延降低 35% ,任务吞吐量提升至 1.5 倍。其三,设计的故障容错机制,将系统可用性提高至 99.9% ,服务中断时间压缩至 1 秒以内,满足工业级可靠性要求。未来研究将结合联邦学习优化跨域资源调度,并探索量子计算在超大规模推理任务中的应用潜力。
参考文献
1]杭同喜.基于分布式计算的网络路由安全大数据监测研究[J].智能城市,2025,11(02):23-25.
[2]仲照鹏.基于大数据云计算的智慧实验室底层逻辑架构[J].广东石油化工学院学报,2024,34(06):58-62.
[3]易广政.面向 AIforScience 任务的分布式自动并行计算框架[D].杭州电子科技大学,2024.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)