.jpg)
AI 技术在招投标的探索应用

隆雨汐
中国电信股份有限公司湖南IT及大数据中心 湖南省长沙市 410016
【关键字】AI;招投标稽核
1.概述
1.1 需求描述
在项目全生命周期中,招投标阶段是不可或缺的重要环节,每月湖南省内发布的招标项目数以千计,需要大量有经验的员工,花费大量时间筛选是否适合公司进行投标,这对于员工来说是巨大挑战。AI 招投标稽核平台运用 AI 技术,通过学习理解招标文件内容,实现对招投标文件关键内容的识别和理解,以便于实现招投标文件关键要点的稽核,减少人工稽核带来的误差,减轻了员工稽核招标文件的工作量,有效提高了工作效率,为稽核工作提供科学辅助,有助于企业通过精准投标提升中标率,从而支撑企业高质量发展。
1.2AI 技术应用说明
1)RPA 注智:模拟招投标文件人员按键生成文件稽核分析报告,实现闲时系统自动提前生成报告。
2)判别式AI 注智:利用NLP 技术对标书 进行文字识别,并进行文本特征分类,文本特征提取,文本特征工程等技术 AI 识别理解,并稽核。
3)大模型注智:利用大模型强大的自然语言处理能力和泛化能力,对标书进行深度理解和分析,实现对招投标文件关键内容的识别和理解,以便于实现招投标文件关键要点的稽核。
2.业务描述
2.1 业务目标
以过往历史招投标文件为数据基础训练大模型,对标书进行深度理解和分析,实现对招投标文件关键内容的识别和理解,并通过RPA 技术自动输出文件分析报告,方便标书编写人员快速发现问题,提高工作效率。
2.2 适用场景
招投标场景:实现对招投标文件关键内容的识别和理解,自动进行投标文档与招标文件的符合度稽核。
其他应用场景:本组件也可适用于评估报告、解决方案编写、实施方案等多类方案的稽核,减轻人工稽核工作量。
2.3 业务流程
AI 标书稽核业务流程如下:
(1)判别式 AI 注智:利用 NLP 技术对标书 进行文字识别,并进行文本特征分类,文本特征提取,文本特征工程等技术 AI 识别理解,并稽核。
(2)文件稽核:基于大模型的自然语言处理能力和泛化能力,对标书进行深度理解和分析,实现对招投标文件关键内容的识别和理解,进行投标文档与招标文件的符合度稽核。
(3)输出稽核报告:运用 RPA 技术,后台自动下载招标文件解析报告和投标文件稽核报告,提供招投标人员查看和使用。
2.4 业务规则
1)招投标文件内容完整,格式正确,包含标书模板必填内容。
2)招标文件解析点、投标文件稽核点预置完整。
3.技术方案
3.1 方案概述
我们提出了一种基于大模型的标书AI 稽核技术方案,通过深度学习、自然语言处理(NLP)、RPA 等先进技术,实现标书的自动化、智能化审核,运用 AI 技术,通过学习理解招标文件内容,实现对招投标文件关键内容的识别和理解,实现招投标文件关键要点的稽核。
3.2 系统集成关系
1、大数据平台
功能:存储标书数据,包括文本、图片等。
集成关系:大数据平台作为数据基础,与 AI 中台通过数据接口相连,实现数据的传输与处理。
2、AI 中台
功能:运用大模型等 AI 技术,对标书进行智能化分析,学习理解招标文件内容,实现对招投标文件关键内容的识别和理解,实现招投标文件关键要点的稽核,并将稽核结果反馈给用户界面或后续的业务流程。
集成关系:AI 中台接收来自大数据平台的数据,通过内置算法进行分析,并将分析结果反馈给用户界面或后续的业务流程。
3、AI 稽核用户操作界面
功能:提供AI 稽核用户操作界面,允许用户上传标书、查看分析结果、进行异常处理等操作。
集成关系:用户界面是系统与用户之间的桥梁,它接收用户上传的标书,并将AI
中台稽核结果反馈给用户。3.3 主要跨系统流程
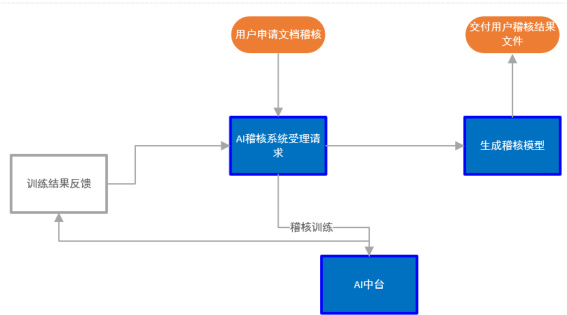
用户在AI 稽核用户操作界面上传标书文档,申请文档稽核,系统受理稽核请求后,调用AI 中台模型能力,进行稽核训练并返回稽核模型结果,输出标书稽核报告反馈给用户。
3.4 详细方案描述
3.4.1 数据采集与预处理
1、多渠道数据收集
招标平台:从政府采购网、企业招标网站、行业协会公告板等,平台定期抓取并下载最新的招标公告、招标文件(如招标文件包、技术规格书、合同模板等)。
投标方:积极与潜在或已有的投标方建立联系,获取其历史投标文档、成功案例、技术提案等内部资料。
第三方数据服务机构:利用专业的数据服务提供商,他们能够提供经过初步筛选和整理的标书文件数据,通过合作购买或数据共享协议,可以快速获取大量高质量的数据资源。
2、数据清洗与预处理
修正格式错误:针对文档中的格式不统一问题,如字体、字号、段落间距等,开发或采用现有的文档处理工具进行批量修正,确保所有文档在视觉上保持一致,便于后续处理。
去除无关信息:通过编写规则或训练专门的模型,自动识别并删除文档中的页眉、页脚、水印、版权声明等无关信息,以及可能的敏感信息(如个人隐私、商业秘密),以保护数据隐私并提升数据质量。
3、数据标注与验证
数据标注:对于需要深入理解或高度依赖上下文的数据部分,如技术规格的关键参数、合同条款的特定要求等,进行标注。
数据集验证:在数据准备完毕后,进行多轮次的验证与审核,包括随机抽样检查、交叉验证、专家评审等,以确保数据集的完整性和一致性,减少因数据质量问题导致的模型偏差。
3.4.2 模型构建与训练
通过大模型的自然语言理解能力,从标书中抽取关键信息,如企业资质、项目经验、技术方案、报价明细等。对大模型抽取的信息进行深度语义理解,为了进行深度语义理解,首先将文本转换为向量形式,在获得文本向量后,利用深度学习模型对文本进行上下文分析,捕捉文本中的长期依赖关系和语义信息,从而更准确地理解文本的含义。在深度语义理解的基础上,系统结合历史经验、合规性标准和行业规则,对关键信息进行深入分析。通过构建招标文件解析规则库和投标文件稽核规则库,引入多种深度学习算法和技术,系统能够自动识别出标书中的潜在风险点(如虚假陈述、夸大业绩等)和不符合规范的内容(如技术参数不符合行业标准、合同条款存在漏洞等 ). 。在模型训练阶段,利用历史标书数据训练 AI 稽核模型,我们采用反向传播算法和梯度下降法等优化算法调整模型参数,使模型能够更准确地识别标书异常和评估合规性。
3.4.3 稽核执行与结果反馈
将待稽核的标书输入训练好的模型,模型自动对标书内容进行深度分析,识别潜在问题。利用模型内置的异常检测算法,对标书中的关键解析点进行深度解析,发现异常内容。系统自动对稽核结果进行整理和分析,生成详细的稽核报告,帮助招投标人员快速稽核、修改标书。
作者简介:隆雨汐,工学硕士学位,中国电信股份有限公司湖南IT 及大数据中心
.jpg)
.jpg)
.jpg)
.jpg)