.jpg)
基于深度胶囊网络的 AI 合成伪造语音识别

毛特瑞
宁波城市职业技术学院 浙江宁波 315100
1 引言
ASV 的目标是确认给定语音是否由指定说话人发出。近年来,ASV 系统的性能取得了显著提升,但语音转换(Voice Conversion,VC)[1,2]、文本转语音(Text-To-Speech,TTS)[3,4,5]技术的发展,使 ASV 系统极易受到攻击。因此,亟需区分伪造语音与真实语音,以提升 ASV 系统的安全性。
近年来,胶囊网络(Capsule Network, CapsNet)作为 CNN 的有力替代方案被提出,能够学习更具等变性的表示。CapsNet 以“胶囊”替代神经元,在输出分类结果的同时,还能反映样本的属性,即保留样本的结构特征。
2 提出的胶囊网络模型
2.1 特征提取
2.1.1MFCC 特征
MFCC 是自动语音与说话人识别中广泛使用的特征,其提取过程为:先计算短时傅里叶变换(STFT),再通过滤波器组将频谱映射为梅尔频谱,最后计算离散余弦变换(DCT)。
2.1.2CQCC 特征
CQCC 是一种基于幅度的特征,提供了一种时频分析方法。短时傅里叶变换(STFT)的时频分辨率固定,而 CQCC 在低频段能捕捉更多声学信息,在高频段能捕捉更多时间信息,更具适应性。
2.4 识别算法
ASVspoof 2019 LA 数据库分为训练集、开发集和评估集三部分,共采用 17 种合成算法:其中 6 种算法的生成语音包含在训练集和开发集中,剩余 11 种为上述 6 种算法的升级版本或全新的数据生成方法。
(1)训练阶段:
提取 ASVspoof 2019 LA 训练集的 MFCC 和 CQCC 特征构建两种模型:MFCC-CapsNet:CNN 处理 MFCC 特征 + 胶囊网络分类CQCC-CapsNet:CNN 处理 CQCC 特征  胶囊网络分类胶囊网络输出经 softmax 转换为概率输出
胶囊网络分类胶囊网络输出经 softmax 转换为概率输出
(2)测试阶段:使用训练好的模型测试评估集评分规则:得分高表示真实语音,得分低表示伪造语音3 实验结果3.1 评估指标串联检测代价函数(t-DCF):ASVspoof2019 挑战赛推出的主要评估指标.
3.2 实验结果
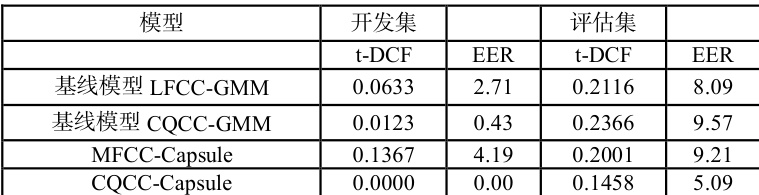
表 2 展示了所提模型在评估集上的性能:MFCC-Capsule 模型的 t-DCF为 0.2001,EER 为 9.21,在评估集(含已知和未知攻击)上略优于基线算法;CQCC-Capsule 模型在开发集(仅已知攻击)上取得了 t-DCF 和 EER均为 0 的最优性能,表 1 不同模型在逻辑访问场景下开发集与评估集的t-DCF 和 EER 得分
动态路由数量可通过动态路由调整连接强度。为进一步分析网络性能,实验调整了动态路由数量,不同路由数量下的 EER 和 t-DCF 结果。结果表明:当训练轮次为 70、动态路由数量为 20 时,所提两种模型均取得最佳性能。
4 结论
本文提出一种适用于逻辑访问场景的语音伪造识别方法,对比了结合两种不同特征提取算法(MFCC 和 CQCC)的模型性能。评估结果表明,所提深度胶囊网络相较于基线算法,t-DCF 降低了 31% ,EER 降低了 37% 。
参考文献
[1]T. Toda, L. H. Chen, D. Saito, F. Villavicencio, M. Wester, Z. Wu, J.Yamagishi.语音转换挑战赛。国际语音通信协会年会(Interspeech),1632-1636(2016)
[2]W. C. Huang, C. C. Lo, H. T. Hwang, Y. Tsao, H. M. Wang. WaveNet声码器及其在语音转换中的应用。第 30 届计算语言学与语音处理国际会议(ROCLING),(2018)
[3]A. V. D. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A.Graves, N. Kalchbrenner, A. Senior, K. Kavukcuoglu.原始音频的生成模型.arXiv 预印本 arXiv:1609.03499,(2016)
[4]Z. Wu, O. Watts, S. King. Merlin:开源神经网络语音合成系统。第 9届国际语音通信协会语音合成研讨会,202-207(2016)
[5]L. Juvela, B. Bollepalli, X. Wang, H. Kameoka, M. Airaksinen, J.Yamagishi, P. Alku.基于生成对抗网络的 MFCC 序列语音波形合成.IEEE 声学、语音与信号处理国际会议(ICASSP),5679-5683(2018)
本文为科研项目成果
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)