.jpg)
基于Whisper模型的口述档案采集方法

张姝 王鹭 孙丽敏 王梓尚 曲靖怡 齐朗
海军档案馆 92677部队 电子工程学院 海军工程大学
一、引言
口述档案作为重要的历史文化记录,为历史事件提供第一手见证,补充和丰富了传统纸质档案,为文化遗产保护提供宝贵资源。然而,传统口述档案采集方法存在显著局限性:人工转录效率低下且易出错;面对大规模档案时人力资源需求巨大;缺乏智能化音频处理能力,难以应对复杂音频环境。这些问题严重制约了采集效率和质量。
随着人工智能技术发展,自动语音识别和自然语言处理技术为口述档案高效采集提供了新机遇。AI 技术能够自动化处理大规模音频数据,显著提升转录准确性和效率。
基于此,本文首次将Whisper 模型应用于口述档案采集领域,通过专门微调使其适应特殊需求。Whisper 模型结合Mel 谱、卷积层与 Seq2Seq Transformer 架构,在快速准确转录口述音频方面表现出色。本文创新点包括:(1)开创性地将Whisper 模型引入并优化用于口述档案采集;(2)基于Common Voice 中文数据集验证方法有效性,展现巨大应用潜力。
二、口述档案采集的传统方法
传统口述档案采集主要通过录音、录像和文字记录等方式进行,依赖人工记录和整理。采集者需准确记录口述内容,遵循真实、完整、客观的原则。
然而,传统方法存在显著局限性:(1)人工转录效率低下,易受记录者理解偏差和注意力分散等人为因素影响;(2)对采集环境要求较高,需安静环境和专业设备;(3)对口述者表达能力要求高,影响受访者投入度;(4)数据存储和管理压力大。
这些局限性制约了口述档案采集的效率和质量。因此,需要借助人工智能等现代技术手段,通过语音识别和自然语言处理技术[5]实现自动转录和智能整理,提升采集工作的现代化水平。
三、基于Whisper 模型的口述档案采集方法
3.1 微调
微调是机器学习中的关键过程,旨在通过对预训练模型进行优化,以提升其在特定任务或领域中的表现。微调属于迁移学习的一种方法,其中预训练模型的参数在新的数据上进行训练,从而适应特定任务。

3.2 Whisper 模型
Whisper 模型支持90 多种语言,是目前最多样化的语音识别模型之一。其核心特性包括自注意力机制,能够衡量输入音频不同部分的重要性,专注于语音相关部分。
Whisper 处理流程如下:首先将音频波形转换为频谱图,反映不同时刻的频率分量强度;随后将音频表示划分为标记(tokens),每个标记代表短时间片段;接着使用Transformer 编码器处理标记,生成编码表示;最后通过解码器预测序列中的下一个词,生成文本输出。
3.3 微调 Whisper
微调过程通过在专门的口述档案数据集上进一步训练 Whisper 模型,使其适应特定领域需求。这包括处理特定术语、地方口音和历史背景对话等挑战。本文选择Whisper 小型模型,该模型包含12 层结构、768 维隐藏表示、12 个注意力头和2.44 亿参数。微调通过最小化交叉熵损失函数优化参数,提升模型在口述档案转录任务中的准确性和领域适应性。
四、基于Whisper 模型的实验
4.1 数据集
实验使用 Mozilla Common Voice 16.1 中文数据集,包含训练集 29406 条、验证集 10626 条、测试集 10626条语音数据,来源于多样化的说话人群体。
4.2 实验参数
训练参数设置:最大步数5000 步,学习率1e-5,批量大小32,每1000 步进行一次评估。采用词错误率(WER)和字符错误率(CER)作为评估指标。
4.3 评价指标
为了评估本文中微调 Whisper 模型的性能,本文采用的关键指标包括:单词错误率(WER)和字符错误率(CER)。WER 衡量自动语音系统生成的转录文本与参考文本之间的差异,CER 衡量转录文本与参考文本之间的字符错误数量.可以有效评估模型在口述档案采集任务中的准确性和性能,具体体现在错误类型和频率方面。
4.4 实验结果
表1 训练结果
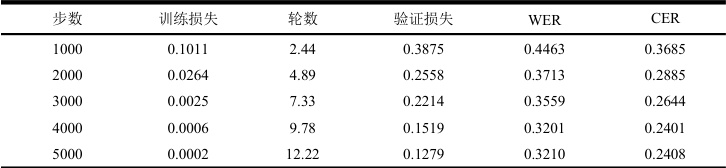
实验结果显示模型性能持续提升。训练和验证损失的下降趋势表明模型在拟合训练数据的同时具备良好的泛化能力,WER 和CER 指标的显著改善证明了微调后的Whisper 模型在中文口述档案转录任务中的有效性。从具体指标分析来看,训练损失接近零表明模型有效学习了语音特征和语言模式。验证损失大幅下降证明模型具备良好的泛化性能。WER 从44.63%降至 32.10% ,CER 从 36.85%降至 24.08% ,表明微调后的 Whisper 模型在中文字符级别转录任务中表现优异,验证了本文方法在口述档案采集领域的实用性。
五、总结及展望
本文首次将 Whisper 模型应用于口述档案采集领域,通过微调技术有效提升了采集效率和准确性。实验结果验证了该方法在WER 和 CER 指标上的显著改进,为口述档案采集的智能化发展提供了新的技术路径。未来工作将重点关注:扩展数据集规模和多样性,涵盖更广泛的口述档案类型;优化微调技术,提高模型在特定任务中的表现;探索更强大计算资源的应用。这将进一步提升模型精度和效率,推动口述档案采集领域的现代化进程。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)