.jpg)
机器学习在网络流量分类与识别中的研究与探索

储柱学
马鞍山师范高等专科学校 安徽马鞍山 243000
随着互联网应用种类的激增和加密技术的普及,传统基于端口和深度包检测的网络流量分类方法效能日益衰退,难以适应现代网络环境。在此背景下,机器学习技术因其强大的模式识别能力,为高效、准确的流量识别提供了新的解决方案。本文旨在研究机器学习在该领域中的应用,通过设计对比实验,评估不同模型的性能,并分析其实际应用潜力与面临的挑战,为相关研究提供参考。
1 机器学习与网络流量分类的基础理论
1.1 网络流量分类的挑战
网络流量分类的根本任务是将网络上的数据流按照产生它们的应用或协议进行归类,比如识别出这是 HTTP 网页浏览流量、那是 BitTorrent 下载流量或者是 Zoom 视频会议流量。传统的分类方法局限性非常明显。基于端口的方法是最简单的,但它严重依赖应用程序使用标准端口这一假设,而现在的应用很多都使用 80 或 443 端口来绕过防火墙限制。深度包检测(DPI)技术通过检查数据包的载荷部分来匹配已知的签名,虽然准确性较高,但无法处理加密流量,而且计算开销很大,随着新应用的出现需要不断更新签名库,维护成本高。此外,网络流量的巨大规模和对实时处理的需求,也给分类系统带来了巨大的性能压力。
1.2 机器学习算法的适用性
机器学习方法为解决上述挑战提供了一条可行的路径。它不依赖端口也不直接检查加密载荷,而是通过分析流量的一系列统计特征来进行分类。这些特征包括流持续时间、数据包大小、到达时间间隔、上下行数据包比例等等。这些特征模式对于特定应用通常是稳定的,即使流量被加密,这些统计特征依然保持不变,因此机器学习能够有效应对加密流量的分类问题。常用的机器学习算法包括监督学习算法如决策树、随机森林、支持向量机(SVM)和朴素贝叶斯,以及无监督学习算法如 K-means 聚类。近年来,深度学习模型如卷积神经网络(CNN)和长短期记忆网络(LSTM)也被引入,用于捕捉更复杂的时空特征。
2 基于机器学习的流量分类模型设计与实现
本研究基于公开数据集 ISCX-VPN2016 进行模型构建与验证。该数据集涵盖了浏览、邮件、视频、聊天等 7 类应用的常规流量及对应 VPN 加密流量,为评估模型在真实加密环境下的泛化能力提供了良好基础。
在数据预处理阶段,我们从原始流量中提取了 15,000 个完整流,并构建了 20 维统计特征向量。特征工程主要围绕流持续时间、双向数据包数量与大小、包长序列的统计值(如均值、方差)以及包到达时间间隔等维度展开。这些特征能够有效刻画不同应用的行为模式,且对加密操作不敏感。随后,我们对数值型特征进行了标准化处理,以消除量纲差异对模型训练的影响。
在模型选型上,本研究选取了四种代表性算法:决策树(DT)、随机森林(RF)、支持向量机(SVM)及多层感知器(MLP)。利用 Scikit-learn 机器学习库,我们将数据集按 7:3 比例划分为训练集与测试集。在训练阶段,我们采用十折交叉验证网格搜索技术对各类模型的核心超参数(如随机森林的树木数量与深度、SVM 的惩罚系数 C 与核函数)进行了优化调优,旨在提升模型的泛化性能与分类准确率。
3 实验结果分析与讨论
3.1 性能评估与对比
模型训练完成后,我们在独立的测试集上评估了它们的性能。我们采用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1-Score 作为评估指标。下表展示了四个模型在测试集上的宏观平均 F1-Score和总体准确率:
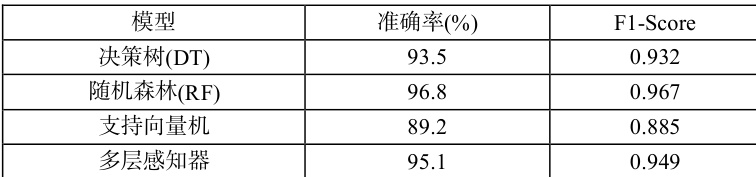
从结果中可以明显看出,随机森林模型表现最好,取得了 96.8% 的准确率和 0.967 的 F1-Score。决策树和 MLP 的表现也相当不错,而 SVM 在本实验中的性能相对较差,这可能是因为其特征空间并非线性可分,而我们的核函数选择及参数调优做得不够充分。随机森林集成学习的优势得到了体现,它通过构建多棵决策树并综合其结果,有效降低了过拟合风险,提高了泛化能力。
3.2 问题与挑战探讨
尽管实验结果令人鼓舞,但在实际部署中仍然面临诸多挑战。首先,我们的模型是在一个静态数据集上训练的,而网络应用是不断更新和变化的,会出现新的应用和协议,这就导致了模型的概念漂移问题,如何实现模型的在线学习和增量更新是一个难点。其次,我们的特征工程过程虽然有效,但依赖于人工设计的统计特征,这可能无法捕捉到最本质的区别特征。深度学习模型可以尝试进行端到端的特征学习,但它需要海量的数据和更强大的计算资源。最后,模型的实时性也是一个需要考虑的问题,对于高速骨干网络,提取大量流的统计特征并进行实时分类对系统的处理能力提出了极高的要求。这些问题的存在说明我们的研究还有待深入。
4 结论
实验表明,机器学习方法,特别是随机森林等集成学习模型,在网络流量分类中能有效克服传统方法的局限,对加密流量实现了超过 96% 的高精度识别,展现出显著优势。然而,研究也暴露了模型面临概念漂移、特征工程依赖性强及实时性处理等实际挑战。未来研究应聚焦于开发在线学习算法以适应动态网络环境,探索端到端的深度学习方法以自动化特征提取,并优化系统实现以满足高速网络的实时处理需求,从而推动该技术的实际部署与应用。
参考文献
[1]赵新建,夏飞,朱凤玲,等.面向网络流量分类的 Mamba 网络:引入数据增强的优化方法[J].软件导刊,2025,24(03):99-108.
[2]郭丽,孙华.基于K-means 和支持向量机SVM 的电力数据通信网络流量分类方法[J].网络安全技术与应用,2024,(04):64-66.
[3]于治平,刘彩霞,刘树新,等.基于机器学习的网络流量分类综述[J].信息工程大学学报,2023,24(04):447-453+483.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)