.jpg)
基于机器学习的金融欺诈检测与伦理反思

张子琪
广东财经大学 440100
一、引 言
随着数字经济持续拓展,金融服务边界不断延伸,传统线下业务正逐步向线上场景过渡。随着交易频率和数据规模的快速增长,金融欺诈的手段也越来越多样、越来越隐蔽,传统靠规则判断的风控手段已经很难应对。为此,越来越多金融机构开始使用机器学习技术,借助模型来识别潜在的风险交易,希望通过分析复杂的行为数据,更快、更准确地发现异常。不过,引入技术并不代表问题就能彻底解决,如果模型只是照搬过去的数据,而这些数据本身就有偏见,比如对某类人群的误判,它反而可能放大这些问题,甚至误伤正常用户,影响用户体验和对平台的信任。因此,本文建模实证分析并从伦理角度出发,探讨模型是否公平、是否透明,以及在出现问题时,平台是否能承担应有的责任。
二、研究方法
2.1 数据来源与预处理
本研究使用的数据来自 Kaggle 平台发布的“Credit Card Fraud Detection Dataset(2023 年版)”,共包含 568,629 笔信用卡交易记录。每条记录包含 28 个匿名化主成分变量(V1–V28),以及两个原始业务字段:交易金额(Amount)和欺诈标签(Class)。为保护用户隐私,主成分变量经 PCA 降维处理,不具备明确语义信息,但可保留结构差异用于模型识别。模型训练前,通过对目标变量的可视化分析,可验证标签标注的准确性。如图 2-1 所示,交易类别在数量上呈现均衡状态,正常交易与欺诈交易各占284,315 条,分别对应类别 0 与类别 1,占总样本的 50% ,这表明数据在发布阶段已进行类别处理。
2.2 模型设计
本文构建逻辑回归与 XGBoost 两种模型:逻辑回归采用 L2 正则化,适用于线性可分场景,作为基准对照;XGBoost 通过残差迭代优化提升分类精度,并引入结构正则项避免过拟合,特别适用于捕捉非线性和高维组合特征。模型参数如 max_depth、learning_rate 等均按经验法设定。训练后通过精确率、召回率、F1 值、AUC 曲线等指标评估性能。
三、结果分析
3.1 混淆矩阵分析
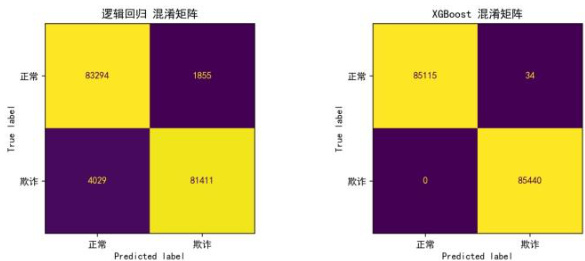
在测试集上,逻辑回归存在较多漏判( FN=4029 )与误杀( ⋅FP=1855, ),表现出明显盲区。而XGBoost在0 误判欺诈样本的同时,误报仅为 34 笔,展现出更强的拟合能力。3.2ROC 曲线与 AUC 值比较
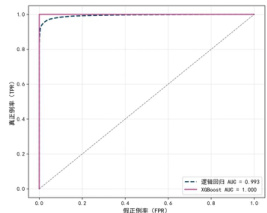
从图像来看,XGBoost 的曲线几乎贴着左上角,说明它在假正例率变化时能持续保持较高的正确识别率。其 AUC 达到 1.000,在测试集上几乎没有误判。逻辑回归的曲线略低,AUC 为 0.993。虽然略逊于 XGBoost,但整体依然表现稳定,具备良好的分类能力。
四、讨论
4.1 模型性能与代价权衡
XGBoost 在各性能指标上表现明显优于逻辑回归,但实际应用中对分类阈值极为敏感。阈值过低虽能拦截多数欺诈交易,但误报率高,影响用户体验;阈值过高则可能放行欺诈交易,带来风险损失。因此,平台需权衡误判与漏判成本,动态设定合适的阈值。
4.2 模型偏差与伦理隐忧
模型过度依赖历史数据,易放大数据中原有偏见,例如持续对特定职业或地域用户进行高风险判定,形成系统性歧视。这种偏差无法从单一指标(如 AUC)中体现,需引入伦理反馈和审计机制主动纠偏。
4.3 伦理框架评估
从伦理视角看,功利主义强调整体效率,容忍一定误判;义务论强调个体权利,拒绝任何不公平判断;正义论则主张透明决策与责任追溯。综合以上观点,金融欺诈检测模型应避免算法黑箱,确保决策过程可解释、审计可追溯,以实现技术应用的社会公平与伦理责任。
五、结论与政策建议
5.1 研究结论
本文基于 2023 年公开的信用卡交易数据,构建逻辑回归和 XGBoost 模型进行欺诈识别性能对比分析。研究发现,XGBoost 在非线性关系建模、欺诈样本识别和误判控制等方面明显优于逻辑回归,尤其适合于处理复杂结构数据。通过 SHAP 值和 PCA 降维分析,进一步揭示了模型决策背后的核心变量特征与判断依据。同时,本研究从伦理视角讨论了模型潜在的偏差风险与公平性问题,提出 AI 模型部署需要关注透明度、公平性和责任追溯机制,避免模型决策对用户造成系统性的不公平对待。
5.2 政策建议
第一是动态调整分类阈值,平台应根据不同类型交易的风险程度灵活调整模型分类阈值,避免统一阈值带来的误判与漏判问题。
第二是平台应建立决策可解释机制:模型决策逻辑应清晰透明,确保用户能够理解和有效申诉,提升平台的信任与可靠性。
第三是实施模型偏差审计:定期开展算法公平性审计,主动监测和纠正潜在的算法偏差,防止歧视与不公平的长期积累。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)