.jpg)
面向教育场景的跨模态内容生成策略设计

罗良夫
武汉晴川学院 430204
1. 引言
教育场景中,传统内容生成方式存在诸多明显缺陷,突出表现为单模态主导、语义割裂及效率低下。单模态主导意味着内容多以纯文本、纯图像或纯语音等单一形式呈现,难以契合人类通过多感官协同认知的习惯,增加了学习者对复杂知识的理解难度;语义割裂则源于传统多模态内容常采用人工拼接方式,不同模态信息间缺乏内在关联,易出现信息不符、错位等问题,破坏知识的连贯性;效率低下体现在依赖人工制作或简单模板,难以快速响应不同学科、学段及学习者的个性化需求,更新迭代也十分缓慢。
本 文 以 Transformer 系 列 的 CLIP、DALL-E 模 型 为 基 础, 结 合Transformer 模态生成模型在跨模态语义处理、并行计算等方面的特点,依据教育教学全流程的规律,构建了“学情驱动 + 模型匹配 + 内容生成 + 反馈优化”的内容生成策略。该策略旨在针对性地弥补传统方式的不足,更好地满足教育场景下的内容生成需求。
2. 理论基础
2.1 模态
模态 (Modality) 是指信息的存在与传播载体,是人类或机器感知、表达世界的一种感知通道,比如人类的听觉、视觉、触觉。模态在本质上是一种数据的表现形式,比如计算机中存储的文本、图片、视频。
给定一个信息源,其模态可记为M={x∈Ra ∣由同一类感知通道获得}·A: 该模态的维度( 如 128×128×3 图像的 A=49152, ) ;
·同一信息源可有 n 种不同模态: M1,M2,⋯,Mn. 。
2.2 多模态
多模态 (Multimodality) 指两种或两种以上模态的组合,通过模态间的语义关联实现对复杂场景的理解或生成能力,多模态则能够有效的降低知识的理解门槛。
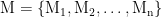 k 为模态数量;
k 为模态数量;
Mi 表示第i 种模态。
2.3 Transformer 模型
Transformer 是基于 Self-Attention Mechanism 机制的一种深度学习模型,主要用于自然语言处理、计算机视觉、语音识别等领域。Transformer 模型的原理是让序列中的每个元素都能通过注意力权值与其它元素建立关联,生成融合上下文信息的向量。
Transformer 属于“编码器 + 解码器”架构,其数学表示形式如下:
·编码器层的输出:
hi=LayerNorm(MultiHead(hi−1,hi−1,hi−1)+hi−1)
hi′ =LayerNorm(FFN(hi) +hi )
其中 FFN(x)=max(0,xW1+b1)W2+b2 是前馈网络
·解码器层的输出:
hi=LayerNorm(MaskedMultiHead(hi−1,hi−1,hi−1)+hi−1)hi′ =LayerNorm(MultiHead(hi,H,H)+hi)
hi′′ =LayerNorm(FFN(hi′ )+hi′ )
掩码 (Masked) 确保生成第 i 个词时仅关注前 i-1 个词。
3. 内容生成策略
Transformer 模态生成模型通过自注意力机制具备较强的跨模态语义对齐与特征捕捉能力。本文以 Transformer 系列的 CLIP、DALL-E 模型为基础,结合 Transformer 模态生成模型的特点,根据教育教学全流程的规律,构建出一个“学情驱动 + 模型匹配 + 内容生成 + 反馈优化”的内容生成策略。
3.1 备课场景下的内容生成
备课阶段的主要目标是快速生成符合知识点要求、便于学生理解的多模态素材集,通过CLIP 模型的语义对齐能力与 DALL-E 的图像生成能力,能够有效的降低教师素材制作成本:多模态素材生成流程:
步骤1 :教师将知识输入到模型中,激活CLIP 与DALL-E 模型;
步骤 2 :CLIP 模型先对教师输入的文本进行语义解析,结合学情数据补充细节内容,确保生成指令既符合知识点,又适配学生基础;
步骤3 :DALL-E 模型根据优化后的指令,分类型生成与知识点对应的素材。
3.2 授课场景下的内容生成
授课阶段的主要目标是通过多模态内容激发学生的学习兴趣,帮助学生理解抽象知识点,可以结合 DALL-E 模型的动态内容生成能力与 Transformer 语音模型的语音交互能力,构建出一个实时响应、多感官刺激的课堂场景:
课堂授课流程:
步骤 1 :对抽象知识进行具象化讲解,讲解抽象复杂的知识时,教师在模型中输入文本指令,DALL-E 模型接收指令后实时生成动态图像,同步激活Transformer 语音模型的播报功能,帮助学生理解抽象的知识;
步骤 2 :学生提出问题后,教师将问题输入到 CLIP 模型中,CLIP 模型根据问题关键词解析其语义,通过 DALL-E 模型生成关于问题的图片,同时Transformer 语音模型生成通俗讲解的内容,通过多种模态数据形式快速解答学生疑问;
步骤3 :课堂互动环节中,教师在DALL-E 模型输入指令,模型生成图片素材后,学生通过课堂大屏观察图片内容进行抢答,通过记录学生答题情况,为后续练习提供数据支撑。
3.3 练习场景下的内容生成
练习阶段的主要目标是针对学生薄弱点生成难度适中的习题,同时通过多模态解析数据帮助学生理解错误的原因。通过 CLIP 模型的语义检索能力与DALL-E 模型的解析生成能力可实现错题精准归因与个性化练习推送效果。
练习生成流程:
步骤 1 :对学情数据进行采集与薄弱点定位,学生完成课程练习题后,通过答题情况数据,定位班级形式的知识薄弱点;
步骤 2 :通过 CLIP 模型搜索与知识点对应的素材,CLIP 模型从知识库中检索与习题相关的数据,建立知识点与多模态素材的关联;
步骤3 :使用DALL-E 模型生成分层练习题与解析,对于较基础的知识,生成文本类型的练习题,帮助学生进行概念的巩固;对较抽象的知识:生成 文本 + 图片类型的练习题,培养学生实验设计能力;对学生易做错的题目,使用DALL-E 模型生成图片 +Transformer 模型生成语音解析,帮助学生直观理解错误原因。
4. 总结
本文介绍了教育场景下的跨模态内容生成策略,该策略以 CLIP、DALL-E等 Transformer 模型为基础,结合教育教学全流程生成多模态教育资源。该策略符合教育教学的规律。该策略从备课阶段、授课阶段、练习阶段三个方面进行设计。同时,通过技术的优化、反馈迭代提升教学质量,解决传统教育中的痛点。未来还结合VR 等技术拓展应用,实现更加精准和高效的跨模态内容生成。
参考文献:
[1] 卢宇, 胡航, 任友群. 生成式人工智能的教育应用与展望—以ChatGPT系统为例 [J]. 华东师范大学学报 ( 教育科学版 ),2023,41(07):122-134.
[2] 徐华伟 , 徐国明 , 张凯 , 王腾 , 朱会灿 , 许杨 . 给大模型制作图文并茂的教科书 : 从 2.5 年的教学视频里挖掘多模态语料 [J]. 大数据2025,31(02):34-46.
[3] 张虹 . 王晨晨 , 陈亮 , 刘宣 . 多模态视觉大模型在家庭教育中的应用研究 : 技术赋能与系统验证 [J]. 中国电化教育 ,2025,(07):102-111.
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)